تحلیل آماری یک ابزار بسیار مفید برای دستیابی به راهکارهای مناسب در زمانی که فرآیندهای واقعی تحلیل به شدت پیچیده یا در شکل واقعی آن ناشناخته است. میباشد. تحلیل آماری، فرآیند جمع آوری، بررسی، خلاصه سازی و تفسیر اطلاعات کمّی را برای ارائه ی دلایل زیربنایی، الگوها، روابط، و فرآیندها پوشش می دهد.
********* اینجانب سیدسعید انصاری فر دارای لیسانس و فوق لیسانس مهندسی صنایع، فوق لیسانس مدیریت دولتی گرایش MIS و دانشجو دکترا مدیریت دولتی گرایش تصمیمگیری و خط مشیگذاری عمومی میباشم. برخی از سوابق علمی پژوهشی به شرح زیر است:
1- دارای بیش از 40 مقاله در موضوعات مختلف (کنفرانس های بین المللی و مجلات علمی پژوهشی و ژورنال ISC) 2- مولف سه کتاب (مبانی سازمان و مدیریت، آموزش مدل سازی معادلات ساختاری و SPSS، نگهداری کارکنان، چالش ها و نظریه ها) 3- مشاوره آماری و انجام تجزیه و تحلیل آماری در بیش از 700 پایان نامه ارشد و 50 پایان نامه دکترا 4- رتبه 7 کنکور دکترا 5- تدریس خصوصی آمار توصیفی و استنباطی و نرم افزارهای SPSS، AMOS، Smart PLS، LISREL 6- کسب رتبه پژوهشگر برتر و برگزیده در جشنواره علمی پژوهشی شهرداری اصفهان
********* تماس با ما: ایمیل: ansarifar2020@gmail.com شماره همراه: 09131025408 شبکه اجتماعی ایتا: 09131025408
********* گروه علمی آموزشی پژوهشگران برتر: این گروه با بهره مندی از کادری مجرب آمادگی تجزیه و تحلیل کیفی و داده های کمی آماری در موضوعات مختلف با استفاده از نرم افزارهای مختلفی چون SPSS ، Smart PLS، LISREL،R ، AMOS، Nvivo، Max QDA را دارد.
همکاران: 1-مجید دادخواه دکتری مدیریت از دانشگاه آزاد اصفهان 2- مرسا آذر: دکتری مدیریت از دانشگاه آزاد اصفهان 3- زهرا وحیدی: دکتری مدیریت آموزشی، مدرس تحلیل کیفی 4-محمد مهدی مقامی: دکتری آمار از دانشگاه اصفهان 5- طناز فریدنی: کارشناسی ارشد آمار و ریاضی از دانشگاه اصفهان 6- زینب احمدی: کارشناسی ارشد روان شناسی از دانشگاه اصفهان
*********** از دلایلی که پژوهشگران انجام تحلیل آماری را به ما می سپارند: - تیم حرفه ای و با تجربه - متخصص در زمینه انواع نرم افزارهای تحلیل آماری با بیش از 10 سال تجربه - پشتیبانی و آموزش حضوری به صورت رایگان
پس از آمادهسازی دادهها در نرم افزار SmartPLS و رسم مدل (همانطوری که در پست قبل نشان داده شد) نوبت آن است که به برازش مدل بپردازیم و پارامترها و ضرایب رگرسیونی را برآورد کنیم. برای این کار از دستور زیر مانند شکل استفاده خواهیم کرد :
Calculate/ PLS Algorithm
پس از اعمال دستور PLS Algorithm پنجره زیر نمایان میشود.
بدون عوض کردن پیش فرضهای برآورد پس از اجرای دستور Start Calculation، خروجی به دو صورت متنی و تصویری قابل مشاهده است که در شکل زیر نشان داده شده است.
خروجی متنی
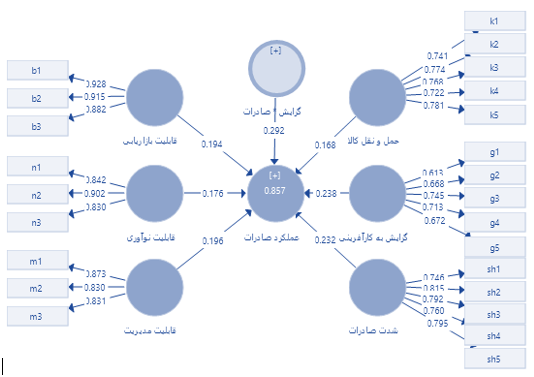
اعداد نشان داده شده، ضرایب رگرسیونی متغیرهای مستقل (سطر) بر متغیرهای مستقل (ستون) است.
خروجی تصویری
1- بارهای عاملی : هریک از اعدادی که بر فلشهای رسم شده از متغیرهای پنهان (متغیرهای آبی رنگ) به متغیرهای آشکار (متغیرهای زرد رنگ) بدست آمده؛ نشانگر بارهای عاملی میباشد. بارهای عاملی از طریق محاسبه مقدار همبستگی شاخصهای یک سازه با آن سازه محاسبه میشوند که اگر این مقدار برابر و یا بیشتر از مقدار 0/4 شود، مؤید این مطلب است که واریانس بین سازه و شاخصهای آن از واریانس خطای اندازهگیری آن سازه بیشتر بوده و پایایی در مورد آن مدل اندازهگیری قابل قبول است (هولاند، 1999). نکته مهم در اینجا این است که اگر محقق پس از محاسبه بارهای عاملی بین سازه و شاخصهای آن با مقادیری کمتر از 0/4 مواجه شد، باید آن شاخصها (سؤالات پرسشنامه) را اصلاح نموده و یا از مدل تحقیق خود حذف نماید.
2-ضریب رگرسیونی استاندارد : ضریب رگرسیونی استاندارد نشان دهنده میزان تاثیر متغیر مستقل بر متغیر وابسته میباشد و در بازه 1- تا 1+ قرار دارد. هرچه این عدد به یک نزدیک تر باشد نشان دهنده تاثیر قوی و مستقیم، هر چه به منفی یک نزدیک باشد نشان دهنده تاثیر قوی و غیر مستقیم و زمانی که به صفر نزدیک تر باشد نشان دهندهی تاثیر نامحسوس و غیر معناداری است.
3- ضریب تعیین (R به توان دو) : نسبت تغییرات (متغیرهای) تعریف شده، به کل تغییرات (متغیرها) میباشد. این اندازه گیری به ما این امکان را میدهد که تعیین کنیم چقدر میتوان به به پیش بینی مدل مطمئن بود. ضریب تعیین میزان بیان واریانس متغیر وابسته به وسیله متغیرهای مستقل را نشان میدهد. برای مثال در مدل فوق 72/4 درصد از تغییرات خلاقیت سازمانی به وسیله متغیرهای مدیریت دانش، جهت گیری استراتژیک رقابتی و نوآوری بیان میشود و 28/6 درصد بقیه مربوط به عواملی است که یا قابل اندازه گیری است و در مدل در نظرگرفته و یا قابل اندازه گیری نیست.
در این پست قصد داریم نحوه ورود دیتاها و رسم مدل را در نرم افزار اسمارت PLS آموزش دهیم. می دانیم که تجزیه و تحلیل حداقل مربعات جزئی (PLS) یک جایگزین برای رگرسیون OLS یا مدل سازی معادلات ساختاری مبتنی بر کوواریانس (SEM) در مدل هایی که متغیر مستقل و وابسته دارند؛ استفاده میشود. بر اساس نظر دیوید گارسون در کتاب “بررسی روش حداقل مربعات جزئی : مدل های رگرسیونی و معادلات ساختاری” PLS در زمانی که :
1-حجم نمونه کوچک باشد (کمتر از 200)؛
2-فرض نرمالیتی برقرار نباشد؛
3-میان متغیرهای مستقل همخطی وجود داشته باشد؛
4- چندین متغیر وابسته و مستقل وجود داشته باشد و شناسایی متغیرهای موثر مشکل باشد. بسیار کاربرد دارد و میتوانید کمک کننده برآورد صحیح باشد.
صفحه اصلی نرم افزار اسمارت PLS پس از نصب به صورت بالا نشان داده میشود. پس از کلیک بر روی نوار ابزار File و انتخاب گزینه Create New Project میتوان پروژهی جدیدی را تعریف نمود.
پس از انتخاب اسم مورد نظر در کادر سمت چپ نرم افزار منویی با اسم انتخابی تشکیل میشود.
با دوبار کلیک بر روی گزینه Double-click to import data دیتای مورد نظر را به نرم افزار معرفی کنید. توجه داشته باشید که فایل دیتای مورد نظر باید دارای پسوند CSV و یا TXT باشد. اگر فایل دیتای شما در نرم افزار SPSS و یا نرم افزار اکسل موجود است. با استفاده از عملیات Save as و انتخاب فرمت CSV، دیتای مورد نظر را تغییر فرمت دهید.
پس از انتخاب فایل دادهها پنجره بالا نمایان میشود. پنجرهای که نمایی کلی از دیتاها و گزارش توصیفی (دادههای گمشده، میانگین، میانه، کمترین، بیشترین، چولگی و کشیدگی) را نشان میدهد.
با دوبار کلیک بر روی مدل نام گذاری شده پنجره زیر جهت رسم متغیرها و روابط نمابان میشود.
1– از این گزینه برای رسم متغیرهای پنهان (متغیری که از گویهها و یا متغیرهای آشکار دیگر ساخته میشود) و تعریف مدل استفاده میشود.
2-برای رسم روابط و یا پیکان یک سویه از متغیر مبدا به متغیر مقصد استفاده میشود.
3-برای بررسی رابطه غیرخطی میان متغیرها از این گزینه استفاده میشود.
4-برای معرفی متغیر تعدیلی به نرم افزار از این گزینه استفاده میشود.
5-تمامی محاسبات ضرایب، برآوردها، بوت استرت و …
6-تنظیم ظاهری مدلها، چپ چین، راست چین و مواردی از این قبیل استفاده خواهد شد.
7-این قسمت اسامی متغیرها، اطلاعات دیتاها و تیترهای خروجیهای گرفته شده مشاهده میشود.
در ادامه، مانند شکل زیر با انتخاب گزینه Latent Variable متغیرهای مورد نظر را در صفحه رسم مدل بوجود میآوریم.
با فعال کردن گزینه Latent Variable، با هر بار کلیک بر روی صفحه سفید رنگ Model Amouzeshi یک متغیر پنهان تشکیل میشود. همانطور که ملاحظه میشود در این صفحه 4 متغیر پنهان رسم کردهایم. برای تغییر نام متغیرها کافی است با راست کلیک بر روی متغیرها گزینه Rename را انتخاب شود تا پنجره زیر باز شود :
پس از اسم گذاری متغیرها وقت آن است مانند شکل زیر که سوالات مرتبط با هر مولفه را برای نرم افزار مشخص کنیم.
در کادر مربوط به متغیرها (Indicators) سوالات مربوط به هرکدام از عامل ها را انتخاب کنید و با گرفتن و کشیدن، آنها را بر روی متغیرهای پنهان قرار دهید تا مانند فوق از هر عامل به سمت سوالاتش فلشی رسم شود. در اینجا سوالات مربوط به جهت گیری استراتژیک رقابتی (OEI1 تا OEI4) را انتخاب کرده و آنها را با کشیدن برروی متغیر جهت گیری استراتژیک رقابتی رها کردیم. این کار را برای تمام متغیرها انجام میدهیم.
پس از معرفی تمام سوالات هر مولفه به نرم افزار، میتوان برای جلوگیری از شلوغ شدن صفحه با کلیک برروی متغیر پنهان و انتخاب گزینه (Hides indicators of selected Constructs)، سوالات را پنهان نمود همانطور که ملاحظه میشود اینکار برای متغیر مدیریت دانش جهت جلوگیری از شلوغی صفحه انجام شده است (علامت + بالای متغیر). همانطور که ملاحظه میشود قرمز بودن متغیرها این مفهوم را به ما میرساند که هنوز مدل رسم شده به طور کامل برای نرم افزار قابل فهم نیست. آخرین مرحله ای که باید انجام شود این است که رابطه میان متغیرها مشخص شود. این کار با فعال کردن گزینه Connect و رسم فلش از متغیر مبدا به متغیر مقصد قابل انجام است.
برای محاسبه حجم نمونه مناسب برای تحلیلهای آماری، باید نوع تحلیل از ابتدا مشخص باشد. همچنین باید توجه داشت که «نوع دادهها» (Data Type)، «توزیع آماری» (Distribution) و میزان پراکندگی آنها (Variance)، «میزان خطا» (Error Level) و همینطور سطح با معنایی (Confidence Level) در تعیین حجم نمونه موثر هستند.
تعیین حجم نمونه ممکن است به روشهایی که در ادامه به آن اشاره میشود، انجام پذیرد:
تعیین حجم نمونه براساس تجربه: در این حالت محقق براساس اطلاعاتی که از توزیع احتمالی یا نوع دادهها دارد، حجم نمونه را تعیین میکند. برای مثال در این حالت اگر حجم نمونه کمتر از حد مورد نیاز باشد، ممکن است «فاصله اطمینان» (Confidence interval) ایجاد شده، دارای طولی بزرگتر از حد قابل قبول باشد که دقت برآورد را کاهش میدهد. همچنین با انتخاب حجم نمونه بزرگتر از مقدار مورد نیاز، هزینههای تحلیلهای آماری بدون آنکه ضرورتی داشته باشد افزایش میدهد.
تعیین حجم نمونه براساس میزان پراکندگی: با انتخاب مقدار واریانس به عنوان معیار پراکندگی برای برآوردگر، میتوان حجم نمونه را انتخاب کرد. در چنین حالتی، برای رسیدن به واریانس کوچکتر (خطای کمتر) برای برآوردگر، احتیاج به حجم نمونه بیشتری نیز هست. در نتیجه اگر هدف تعیین کرانهای فاصله اطمینان باشد، میتوان با انتخاب حجم نمونه بزرگ، به طول فاصله اطمینان کوچکتری نیز دست یافت.
تعیین سطح با معنایی: با ثابت در نظر گرفتن میزان خطا، با افزایش مقدار سطح اطمینان یا سطح بامعنایی به نمونه بیشتری نیز نیاز داریم. در نتیجه باید بین میزان خطا و سطح معنیداری به یک تعادل رسید تا نمونه مناسب بدست آید. با انتخاب حداکثر میزان خطا و در نظر گرفتن سطح با معنایی مناسب به حداقل حجم نمونه خواهیم رسید.
در مسائل مربوط به تعیین حجم نمونه، اغلب توزیع دادهها را نرمال فرض میکنند. از طرفی میدانیم طبق قضیه حد مرکزی (Central Limit Theorem) و «قانون اعداد بزرگ» (law of Large Number) با افزایش حجم نمونه، میانگین بیشتر توزیعهای آماری به سمت توزیع نرمال میل میکنند. بنابراین انتخاب توزیع نرمال برای دادهها کمی کاری غیر منطقی محسوب نمیشود بلکه فقط ممکن است حجم بزرگتری از نمونه به کار آید که باعث افزایش هزینه نمونهگیری میشود ولی در عمل خطا برآورد تغییری نخواهد کرد.
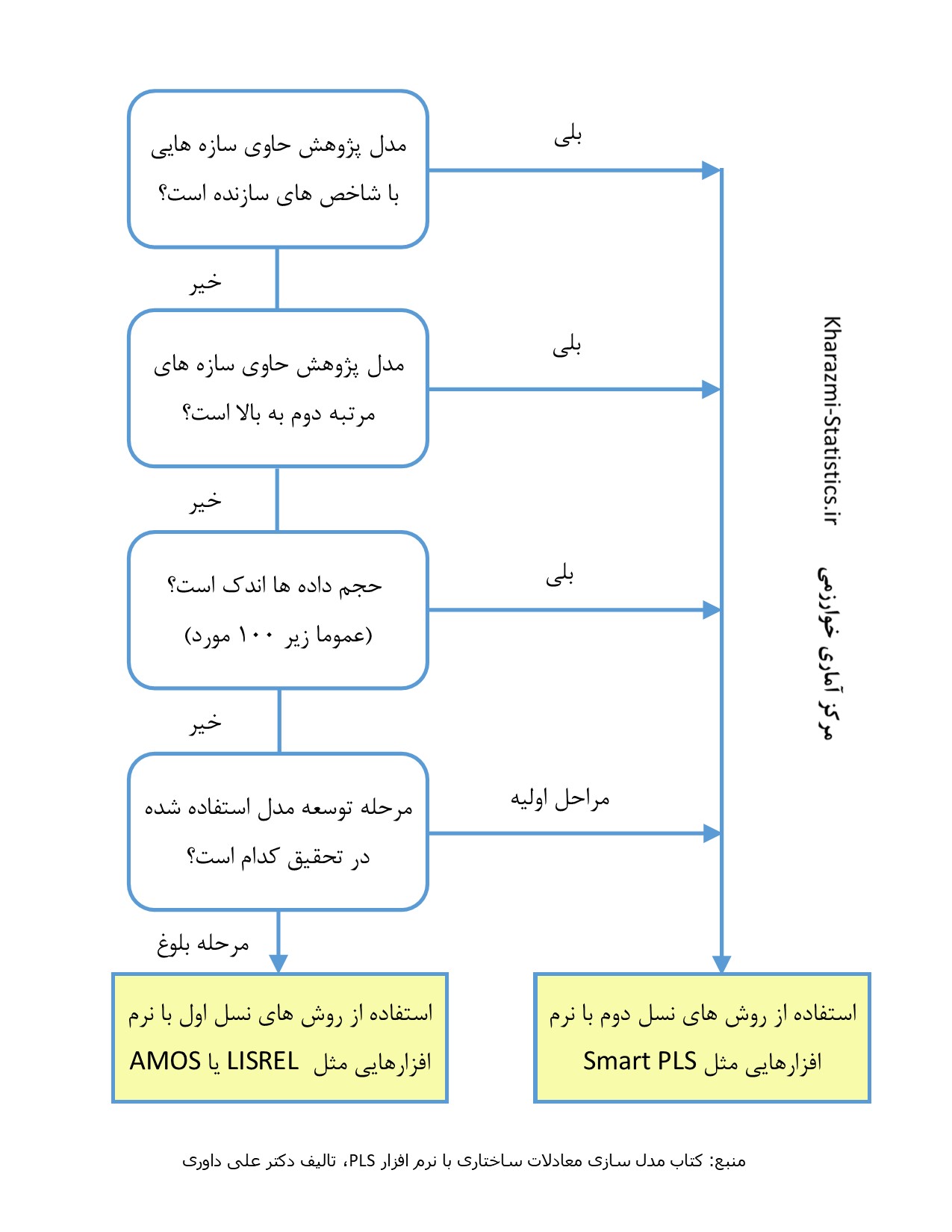
اسمارت PLS یک نرم افزاری کاربردی برای طراحی مدل های معادلات ساختاری است که به کاربر این اجازه را می دهد به جای کدنویسی پیچیده از المان های گرافیکی استفاده نماید. این نرم افزار که در سال 2005 در دانشگاه هامبورگ آلمان طراحی شده است مبتنی بر جاوا می باشد و باعث می شود کاربران سیستم عامل های مختلف از آن استفاده نمایند. هدف این مقاله بیان مراحل انجام تحلیل آماری با نرم افزار SmartPLS و مقایسه آن با نرم افزار Amos و لیزرل می باشد.
علت انجام تحلیل آماری با استفاده از SmartPLS
اصلی ترین دلایل استفاده از نرم افزار Smartpls به شرح زیر است :
1– حجم نمونه کم باشد.
2- داده ها نرمال نباشند.
در صورتی که حجم دیتاها زیاد و یا داده ها نرمال باشند نیز میتوان از این روش استفاده کرد.
اما اگر بخواهیم به طور مفصل توضیح دهیم علت استفاده از نرم افزار اسمارت PLS را به صورت زیر بیان می کنیم :
چه زمانی از AMOS جهت انجام تحلیل آماری استفاده می شود ؟
ویژگی های انجام تحلیل آماری با نرم افزار AMOS و Lisrel
1-روش معادلات ساختاری مبتنی بر کوواریانس بر تایید روابط عوامل تمرکز دارد.
2-روش معادلات ساختاری مبتنی بر کوواریانس برای تایید تئوری پیشین کاربرد دارد.
3-نیازمند حجم نمونه بزرگ است.
4-برای مدل های انعکاسی کاربرد دارد.
5-به صورت ایده آل هر عامل حداقل باید 3 یا 4 گویه داشته باشد.
6-قبل از برازش باید داده های گم شده مشخص شوند.
7-درصورت وجود چند-همخطی، باید قبل از برازش مشخص شود.
تفاوت انجام تحلیل آماری با SmartPLS و AMOS
ویژگی های تحلیل آماری با نرم افزار SmartPLS
1-روش معادلات ساختاری مبتنی بر واریانس بر پیش بینی عوامل تمرکز دارد.
2-روش معادلات ساختاری مبتنی بر واریانس برای اکتشاف تئوری کاربرد دارد.
3-با حجم نمونه کوچک نیز قابل انجام است.
4-برای مدل های انعکاسی و تکوینی کاربرد دارد.
5-از عوامل با یک گویه پشتیبانی می کند.
6-مشکلی برای برازش داده ای که دارای مقادیر گم شده است، ندارد.
7-بررسی شاخص استون-گیسر جهت تایید تناسب پیش بین مدل معادلات ساختاری
هزینه انجام تحلیل آماری با نرم افزار SmartPLS
برآورد هزینه تجزیه و تحلیل آماری با استفاده از نرم افزارهای SmartPLS، AMOS و Lisrel معمولا بر اساس پیچیدگی مدل معادلات ساختاری انجام می شود. طبیعتا هر چه تعداد متغیرهای پنهان، متغیرهای تعدیلگر و میانجی در مدل بیشتر باشد کار تجزیه و تحلیل آماری نیز پیچیده تر می شود. با توجه به این که کوکرانا یک موسسه کاملا حرفه ای و با تجربه برای تحلیل آماری است و بدون واسطه است، تجزیه و تحلیل آماری را با هزینه منطقی انجام می دهد. برای مثال کوکرانا مدل های مشابه شکل زیر را یک مدل پیچیده تلقی کرده و برای تجزیه تحلیل آن هزینه بیشتری درخواست می کند.
نمونه مدل معادلات ساختاری پیچیده از نظر پژوهشگران برتر اسپادانا
دانشجوی هر مقطع و یا هر دانشگاهی که در ایران هستید، میتوانید مشاوره آماری آنلاین (به صورت رایگان) دریافت نمایید. اگر در ابتدای پژوهش هستید و برای بیان مساله، اهداف، فرضیه های آماری، مدل سازی، روش تحقیق، حجم نمونه و … نیاز به کمک دارید و یا اگر دادههای خود را جمعآوری کردهاید و برای تحلیل آن ها نیاز به یک راهنما دارید کافیست از طریق راه های ارتباطی معرفی شده با ما در ارتباط باشید.
در واقع یکی از راه های کنترل اثرات نمره پیش آزمون به عنوان اثر انتقال، استفاده از آزمون آنالیز کوواریانس (ANCOVA) است. به طوری که شرایطی برای مطالعه فراهم می شود. تا اثرات درمان را جدا از اثر بالقوه نمره پیش آزمون بررسی کند.
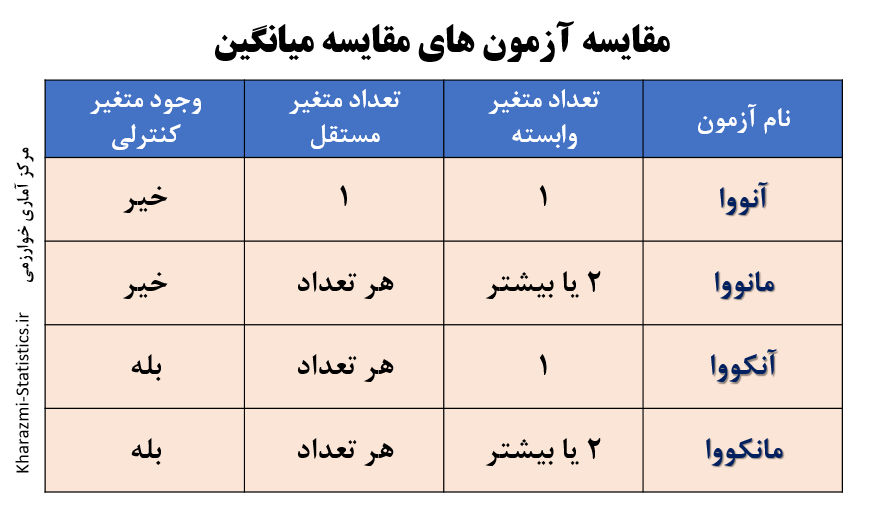
تفاوت تحلیل کوواریانس (ANCOVA) و تحلیل واریانس (ANOVA)
آنکووا گسترش داده شده ی آنالیز واریانس است که پیش فرض های آن را نیز دارد. تفاوت آشکار بین ANOVA و ANCOVA حرف “C” است که مخفف “کواریانس” است. مانند ANOVA، “تجزیه و تحلیل کوواریانس” (ANCOVA) یک متغیر پاسخ پیوسته دارد. تحلیل کوواریانس (ANCOVA) مانند تحلیل واریانس برای تشخیص تفاوت در میانگین چند گروه متغیر مستقل، در حالی که کار کنترل متغیرهای کووریت (Covariate Variables) را انجام می دهد، استفاده می شود. متغیر کووریت معمولاً جزئی از سؤال اصلی تحقیق نیست اما می تواند متغیر وابسته را تحت تأثیر قرار دهد و بنابراین باید کنترل شود.
در حالی که آنالیز واریانس به دنبال اختلاف در بین میانگین ها است. تحلیل کوواریانس به دنبال اختلاف میانگین های تعدیل شده (به وسیله متغیر کووریت که به آن متغیر مخدوش کننده نیز می گویند) می باشد.
پیشفرض های تحلیل کوواریانس تک متغیره (ANCOVA)
قبل از معرفی پیش فرض های تحلیل کوواریانس، از این که یک یا چند پیش فرض معرفی شده در هنگام آنالیز دیتا با نرم افزار SPSS رعایت نشود تعجب نکنید ! همیشه داده استخراج شده از دنیای واقعی مانند مثال های موجود در متن کتاب ها همه چیز را مطلوب نشان نمی دهد. همچنین از این که چند پیش فرض اصلی هم رد شود نگران نشوید ! همیشه یک راه حلی باید وجود داشته باشد.
پیش فرض اول : پیوسته بودن متغیر وابسته و کووریت
متغیر وابسته و متغیر کووریت بایستی پیوسته باشد. برای مثال متغیر زمان (که با واحد ساعت اندازه گیری می شود)، نمرات IQ (امتیاز IQ) نمرات امتحان (0 تا 20) و وزن (به کیلوگرم) پیوسته و کمی می باشد. البته متغیرهای کووریت (متغیرهای مخدوش کننده) می تواند رسته ای نیز باشد (مانند جنسیت). که در این حالت آزمون ANCOVA ترجیح داده نمی شود.
پیش فرض دوم : رسته ای بودن متغیر مستقل
متغیر مستقل بایستی شامل دو یا چند سطح باشد برای مثال جنسیت که دارای دو سطح زن و مرد است. همچنین متغیر گروه تحقیق که شامل (گروه کیس و گروه کنترل) است. فعالیت فیزیکی (کم، متوسط، زیاد) نیز مثال دیگری از این قبیل می باشد.
پیش فرض سوم : استقلال مشاهدات
هیچ ارتباطی بین مشاهدات در هر گروه و یا بین گروه ها وجود نداشته باشد. همچنین هیچ یک از شرکت کننده ها (اعضای نمونه) در بیش از یک گروه نباشد. البته این موضوع بیشتر به طراحی مطالعه مربوط می شود. اگر این پیش فرض رعایت نشود نیاز به یک آزمون آماری دیگری به جای آزمون ANCOVA می باشد.
پیش فرض چهارم : عدم وجود داده پرت
در بین داده های پژوهش نباید داده پرت قابل توجهی وجود داشته باشد. چرا که وجود داده پرت ممکن است بر نتایج بدست آمده از تحلیل کوواریانس تاثیر منفی بگذارد و از اعتبار نتایج آن کاهش دهد.
پیش فرض پنجم : نرمال بودن باقی مانده ها
برای هر سطح از متغیر مستقل، باقی مانده بدست آمده تقریبا بایستی دارای توزیع نرمال باشد. به این دلیل از واژه تقریبا استفاده کردیم چون می دانیم این پیش فرض در اکثر اوقات اتفاق نمی افتد در حالی که نتایج بدست آمده از تحلیل کوواریانس معتبر باقی می ماند.
پیش فرض ششم : همگنی واریانس ها
این پیش فرض به کمک انجام آزمون لون (Levene’s test) در نرم افزار SPSS قابل بررسی است.
پیش فرض هفتم : ارتباط خطی کووریت با متغیر وابسته
در هر سطح از متغیر مستقل، متغیر کووریت رابطه خطی با متغیر وابسته دارد. این پیش فرض به کمک نرم افزار SPSS از طریق رسم Scatter plot گروه بندی شده از متغیر کووریت، پیش آزمون متغیر وابسته و متغیر مستقل بررسی می شود.
پیش فرض هشتم : همسانی واریانس
این پیش فرض به کمک نرم افزار SPSS از طریق رسم Scatter plot ار باقی مانده های رگرسیون در مقابل مقادیر پیش بینی شده بررسی می شود.
پیش فرض نهم : همگنی شیب رگرسیون
همگنی شیب رگرسیون بدین معنی است که شیب رگرسیونی خطوط مختلف در بین گروه ها باید برابر باشد. به عبارت دیگر تعامل نمرات کووریت و متغیر مستقل در بین گروه ها نباید اختلاف معنی داری داشته باشد. به عبارتی دیگر، نیاز هست که شیب های خطوط رگرسیونی برای کووریت ها (در ارتباط با متغیر وابسته) در بین گروه ها (کیس و کنترل) یکسان باشد که به این پیش فرض همگنی شیب رگرسیون گفته می شود که می تواند با یک آزمون F بر روی تعامل متغیرهای مستقل با کووریت ها ارزیابی شود. اگر آزمون F معنادار بود، بدین معنی است که این پیش فرض نقض شده است. مطالعه بیشتر
ارائه مثال انجام تحلیل کوواریانس در SPSS
در یک مطالعه ای فرضی، پرسشنامه کیفیت زندگی در اختیار 60 نفر از مبتلایان به صرع شرکت کننده در پژوهش قرار داده شد تا آن را تکمیل نمایند. این 60 نفر به صورت تصادفی به دو گروه 30 (کنترل) و 30 (کیس) تقسیم بندی شدند. بیماران گروه کیس (Case) تحت مداخله (پیگیری تلفنی به صورت برقراری 10 تماس 15 دقیقه ای) در طی دو ماه قرار گرفتند. همچنین، در بیماران گروه کنترل (Control) هیچ گونه مداخله ای انجام نشده و آموزش های روتین را دریافت کردند. پس از دو ماه و حین مراجعه به درمانگاه، کیفیت زندگی در دو گروه کیس و کنترل مجددا مورد بررسی قرار گرفت.
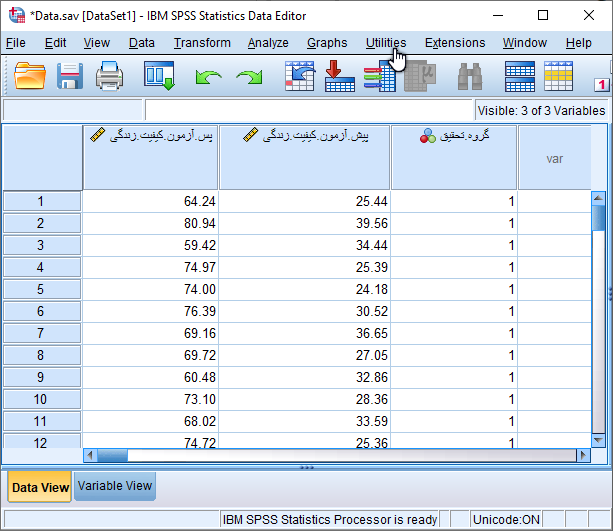
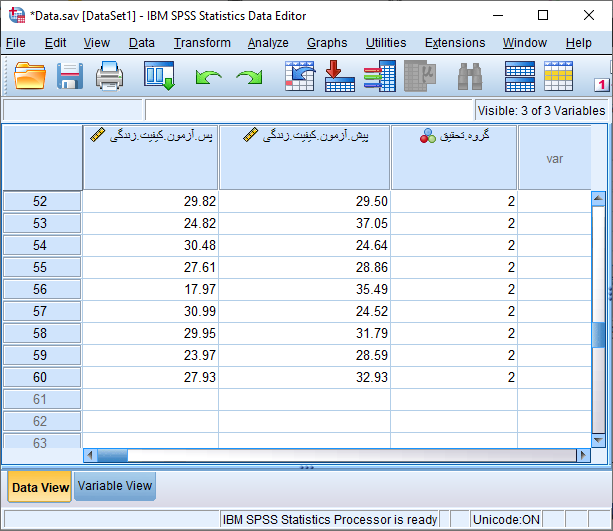
نحوه ورود داده برای انجام تحلیل کوواریانس در SPSS
برای سادگی نمایش داده های وارد شده، فقط نمرات کل کیفیت زندگی را قبل و بعد از مداخله مانند شکل زیر در نرم افزار SPSS وارد کردهایم. توجه داشته باشید که نمرات گروه کیس و کنترل در پیش آزمون و پس آزمون بایستی در یک ستون و زیر هم وارد نرم افزار شود و با ایجاد متغیر دو سطحی گروه تحقیق از لحاظ گروه مطالعه قابل تشخیص باشد.
حال دیتا برای انجام آزمون تحلیل کوواریانس آماده شده است. از طریق مسیر زیر در نرم افزار SPSS آزمون ANCOVA را انجام می دهیم.
Analyze / General Linear Model / Univariate
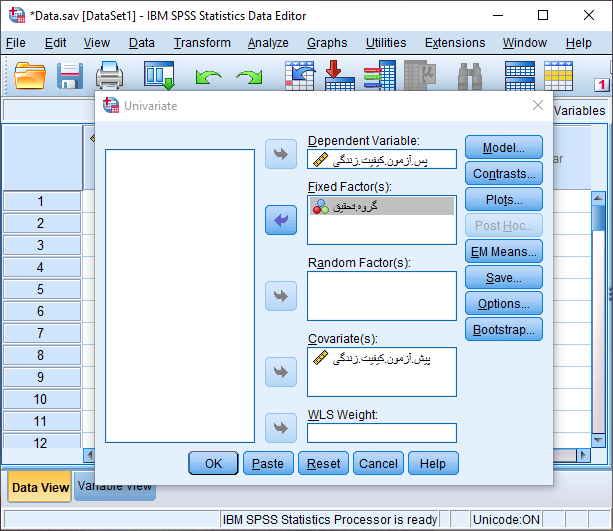
پس از انجام مسیر فوق پنجره زیر جهت تنظیمات تحلیل کوواریانس قابل مشاهده است.
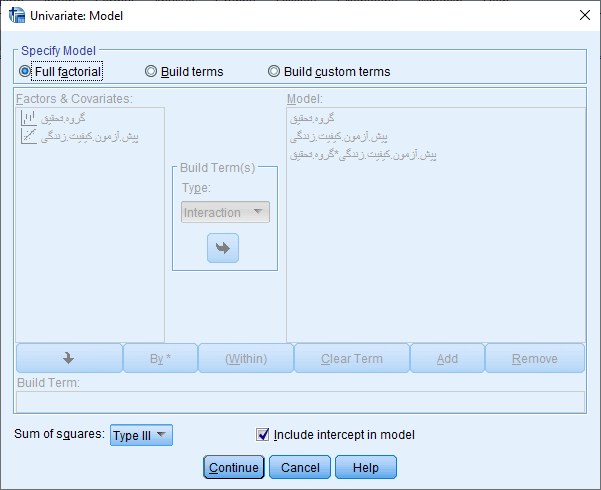
همانند شکل فوق، متغیر کیفیت زندگی پس از مداخله (پس آزمون) را به عنوان متغیر وابسته در کادر Dependent Variable، متغیر کیفیت زندگی قبل از مداخله (پیش آزمون) را به عنوان متغیر کووریت (مخدوش کننده) در کادر Covariate(s) و متغیر گروه را در کادر Fixed Factor(s) به عنوان متغیر مستقل وارد می کنیم. ابتدا برای بررسی پیش فرض همگنی شیب رگرسیونی از طریق دکمه Moldel پنجره زیر را باز می کنیم.
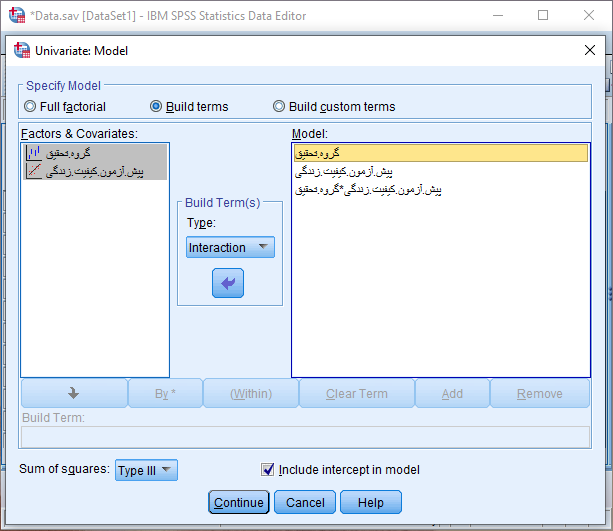
مانند شکل فوق ابتدا در کادر Specify Model گزینه Build terms را فعال میکنیم. سپس در کادر Model متغیرهای (گروه تحقیق، پیش آزمون و متغیر ضربی پیش آزمون کیفیت زندگی * گروه تحقیق را وارد می کنیم. با کلیک بر روی دکمه Continue مجدد وارد پنجره قبلی می شویم. حال با کلیک بر روی دکمه OK خروجی نرم افزار به صورت زیر مشاهده می شود.
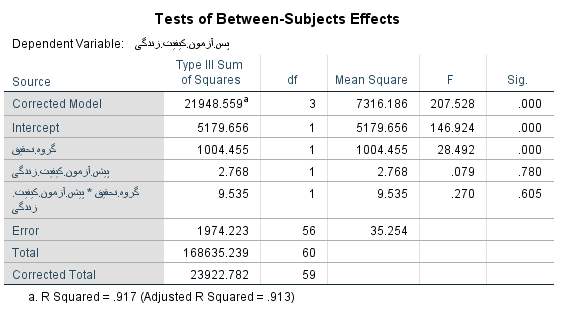
با توجه به جدول فوق ملاحظه می شود سطح معنی داری متغیر گروه تحقیق*پیش آزمون کیفیت زندگی برابر 0.605 و بیشتر از 0.05 می باشد. این امر نشان دهنده این است که پیش فرض همگنی شیب رگرسیون رعایت می شود.
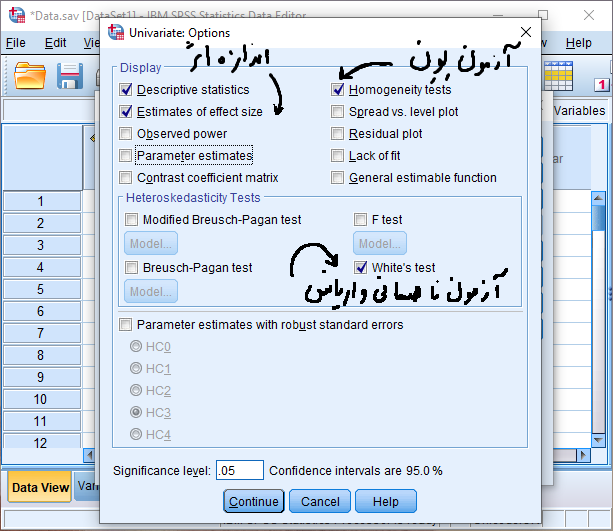
حال برای بررسی پیش فرض همگنی واریانس ها از طریق دکمه Moldel پنجره زیر را باز کرده و مانند شکل زیر تنظیمات لازمه را انجام می دهیم.
مانند شکل فوق ابتدا در کادر Specify Model گزینه Full factorial را فعال میکنیم. با کلیک بر روی دکمه Continue مجدد وارد پنجره قبلی می شویم.
در این پنجره از طریق گزینه Options پنجره زیر باز می شود.
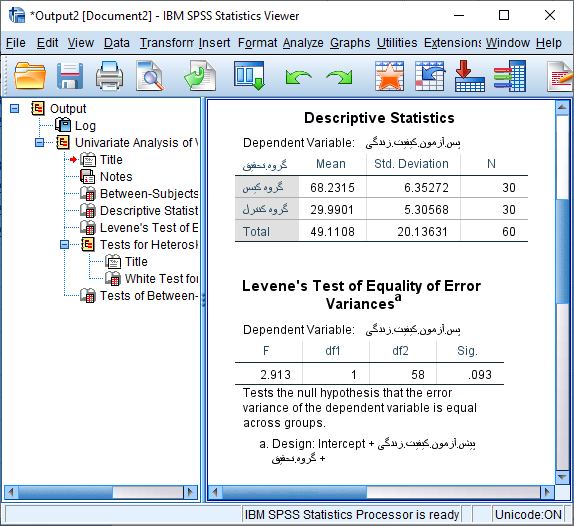
پس از انجام تنظیمات فوق با کلیک بر روی دکمه Continue مجدد وارد پنجره قبلی می شویم. حال با کلیک بر روی دکمه OK خروجی نرم افزار به صورت زیر مشاهده می شود.
با توجه به سطح معنی داری شکل فوق (0.093) فرضیه صفر مبنی بر همگونی واریانس ها در دو گروه شاهد و آزمایش در سطح 5 درصد رد نمی گردد. در نتیجه فرضیه برابری واریانس ها تایید می شود.
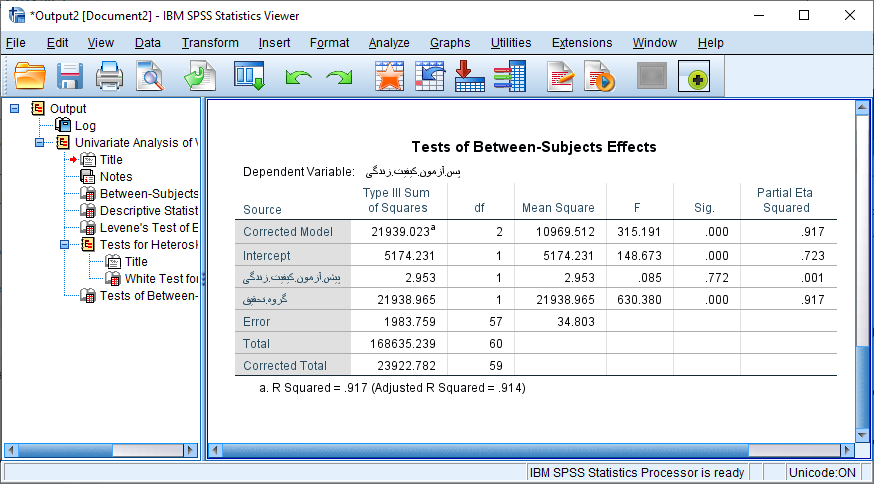
در جدول فوق فوق ملاحظه می شود، در پس آزمون نمرات کیفیت زندگی کل آزمایش (گروهی که پیگیری تلفنی دریافت کردند) با نمرات کیفیت زندگی در گروه گواه تفاوت معنی داری وجود دارد (سطح معنی داری کمتر از 0.05). در نتیجه می توان دریافت که بیمارانی که مداخله دریافت می کنند، نسبت به دیگر افراد، کیفیت زندگی کل بیشتری دارند. به طور کلی مشاهدات بیان می کند که پیگیری تلفنی بر بهبود کیفیت زندگی افراد با اندازه اثر (0.917) تاثیر گذار است.
اندازه گیری مکرر به طرحی گفته می شود که در آن هر یک از آزمودنی ها در معرض بیش از یک متغیر مستقل قرار می گیرند. مورد استفاده مناسب این طرح زمانی است که پژوهشگر علاقمند باشد تغییراتی را که در روند زمان در آزمودنی به وجود می آید مشاهده یا اندازه گیری نماید. هدف اساسی این طرح، به حداقل رساندن خطاهای ناشی از تفاوت های فردی است.
برای درک بهتر مطلب، به مثال زیر که با استفاده نرم افزار SPSS تجزیه و تحلیل شده است توجه نمایید.
پژوهشگری قصد دارد تأثیر اوقات مختلف روز را روی میزان نشاط تعدادی افراد مورد مطالعه قرار دهد. به این منظور 20 فرد (زن و مرد) انتخاب و میزان نشاط آنان را در اوقات مختلف تعیین شده مورد اندازه گیری قرار داد. این پژوهشگر می خواهد بداند که آیا اوقات مختلف روز بر میزان نشاط زنان و مردان شاغل و بیکار تأثیر دارد؟ برای این پژوهش فرضیه زیر قابل تعریف و آزمون است.
"به نظر می رسد میزان نشاط زنان و مردان شاغل و بیکار در اوقات مختلف روز متفاوت است"
برای آزمون فرضیه بالا ابتدا مانند شکل زیر داده ها را بصورت طبقه بندی شده وارد نرم افزار SPSS می کنیم. ستون اول نشان دهنده جنسیت افراد (1 مرد و 2 زن)، ستون دوم وضعیت شاغل یا بیکار بودن افراد را نشان می دهد و سه ستون بعدی میزان نشاط اندازه گیری شده افراد را در اوقات مختلف (سه زمان) روز نشان می دهد.
پس از وارد کردن داده ها از مسیر زیر گزینه Repeated measures را انتخاب می کنیم.
در کادر باز شده باید نام متغیر طول زمانی (Time) را در داخل کادر Within-Subject Factor Name وارد می کنیم. سپس روبروی قسمت Number of Levels تعداد زمان هایی که میزان نشاط را اندازه گیری کرده ایم تایپ می کنیم. در این مثال عدد 3 وارد شده است. سپس روی دکمه Add کلیک می کنیم (شکل زیر را مشاهده کنید). در قسمت Measure Name نیز نام متغیر نشاط را وارد می کنیم (دقت نمایید که نامی که در هر دو قسمت وارد می کنید نباید مشابه با نام متغیرهایی که در فایل اصلی وارد کرده اید باشد). در نهایت روی دکمه Define کلیک می کنیم.
در مرحله بعد مانند شکل زیر 3 متغیر Happiness را به قسمت Within-Subjects Variables و دو متغیر Gender و Employment را به قسمت Between Subjects Factor منتقل می نماییم.
در مرحله بعد، از سمت راست گزینه Plots را انتخاب می کنیم تا کادر زیر باز شود. در این قسمت متغیر Time را به قسمت Horizontal axis و متغیر Gender را به قسمت Separate Lines انتقال داده و روی Add کلیک می کنیم.
در این صورت شکل زیر مشاهده می شود.
در مرحله بعد، یکبار دیگر از متغیر Time را به قسمت Horizontal axis و اینبار متغیر Employment را به قسمت Separate Lines انتقال داده و روی Add کلیک می کنیم. در نهایت روی Continue کلیک می کنیم.
در مرحله بعد، از قسمت سمت راست کادر اصلی، گزینه Option را انتخاب می کنیم تا کادر زیر باز شود. سه گزینه Descriptive Statistics، Estimates of Effect Size و Homogeneity Test را تیک زده، روی Continue کلیک می کنیم.
در نهایت روی OK کلیک می کنیم تا نتایج بصورت زیر ظاهر شوند. جدول اول با عنوان Between Subject Factors تعداد افراد زن و مرد و همچنین شاغل و بیکار را نمایش می دهد.
جدول زیر با عنوان Descriptive Statistics آماره های توصیفی مربوطه را به تفکیک گروه بندی های انجام شده (نشاط، جنسیت و وضعیت اشتغال) نمایش می دهد.
این جدول آماره Box M باکس ام را نشان می دهد. این آزمون این فرض صفر را مورد آزمون قرار می دهد که ماتریس های کوواریانس مشاهده شده متغیرهای وابسته در بین گروه های مختلف برابرند. در جدول زیر چون مقدار F (1.662) در سطح خطای داده شده (0.07) معنی دار نیست بنابراین فرض صفر رد نمی شود. به این معنی که ماتریس های کوواریانس مشاهده شده بین گروه های مختلف با هم برابرند.
جدول زیر نتایج آزمون های چند متغیره (چهار آزمون اثر پیلای، لاندای ویلکز، اثر هتلینگ، بزرگترین ریشه روی) را نشان می دهد. برای معنی داری و غیر معنی داری هر آزمون می توان به مقدار Sig دقت نمود که اگر کمتر از 0.05 باشد در سطح 0.05 معنی دار است. از میان چهار آزمون چندمتغیره، آزمون لاندای ویلکز از معروفیت بیشتری نسبت به چهار آزمون دیگر برخوردار است. اما آزمون اثر پیلای در موقعیت های عملی دارای قدرت بیشتری نسبت به سایر آزمون هاست. در این مثال هیچیک از اثرات معنی دار نشده است.
جدول زیر نتایج آزمون کروویت ماخلی را نشان می دهد. آزمون کروویت ماخلی این فرض صفر را آزمون می کند که ماتریس کوواریانس خطای مربوط به متغیرهای وابسته تبدیل شده نرمال یک ماتریس همانی است. در این آزمون چنانچه سطح معنی داری کوچکتر از 0.05 باشد فرض H0 رد و فرض H1 تأیید می گردد. چنانچه فرض H0 رد شود نمای توان کروویت ماتریس واریانس-کوواریانس متغیر وابسته را پذیرفت و باید از سه آزمون دیگر گرینهاوس گیسر، هیون -فلت یا حد پایین استفاده نمود که این آزمون ها درجه آزادی تصحیح می نمایند. در این مثال کروویت ماتریس واریانس-کوواریانس در سطح خطای 0.05 (Sig.=0.283) پذیرفته می شود و نیازی به استفاده از سه آزمون دیگر نیست.
جدول زیر آزمون های اثرات درون آزمودنی ها را نشان می دهد. چون در قسمت قبل کروویت ماتریس واریانس-کوواریانس از طریق آزمون کرویین ماخلی پذیرفته شد در این قسمت ما برای آزمون معنی داری و غیر معنی داری هر اثر از ردیف های Sphericity asumed استفاده می کنیم. ولی چنانچه کروویت ماتریس واریانس کوواریانس پذیرفته نشود باید از سه ردیف دیگر (آزمون های گرینهاوس گیسر، هیون-فلت و حد پائین) استفاده نمود که معروفترین آن ها آزمون هیون-فلت می باشد. همانطور که مشاهده می شود تنها اثر تعاملی Time*Gen*Empoyment در سطح خطای 0.05 معنی دار شده است.
این جدول نتایج آزمون لون جهت سنجش برابری واریانس های خطای متغیر Time در اوقات مختلف روز را نشان می دهد. همانطور که مشاهده می شود در وقت اول و سوم این آزمون غیر معنی دار و تنها در وقت دوم معنی است (به دلیل Sig کمتر از 0.05). نتیجه اینکه تنها در وقت دوم، واریانس خطا در بین افراد مختلف متفاوت می باشد.
جدول زیر مهمترین نتایج پژوهش را در بر دارد. همانطور که مشاهده می شود هیچیک از اثرات Gender، Employment یا Gender*Empoyment معنی دار نشده است به این معنی که میزان نشاط زنان و مردان شاغل و بیکار در اوقات مختلف روز هیچ تفاوتی با هم ندارد!.
نمودار زیر میزان نشاط زنان و مردان را بصورت جداگانه در اوقات مختلف روز نشان می دهد. خط بنفش رنگ مربوط به میزان نشاط مردان و خط سبز رنگ مربوط به نشاط زنان است. این نمودار نشان می دهد که مردان در وقت اول بیشترین نشاط و پس از آن نشاط آن ها کاهش می یابد در حالی که زنان در وقت سوم بیشترین نشاط را داشته اند.
نمودار زیر میزان نشاط افراد شاغل و بیکار را نشان می دهد. خط بنفش رنگ میزان نشاط افراد شاغل و خط سبز رنگ میزان نشاط افراد بیکار را نشان می دهد. این نمودار نشان می دهد که افراد شاغل و بیکار در وقت اول و سوم بیشتر از وقت دوم نشاط داشته اند ولی در کل میزان نشاط افراد شاغل بیشتر از افراد بیکار بوده است.
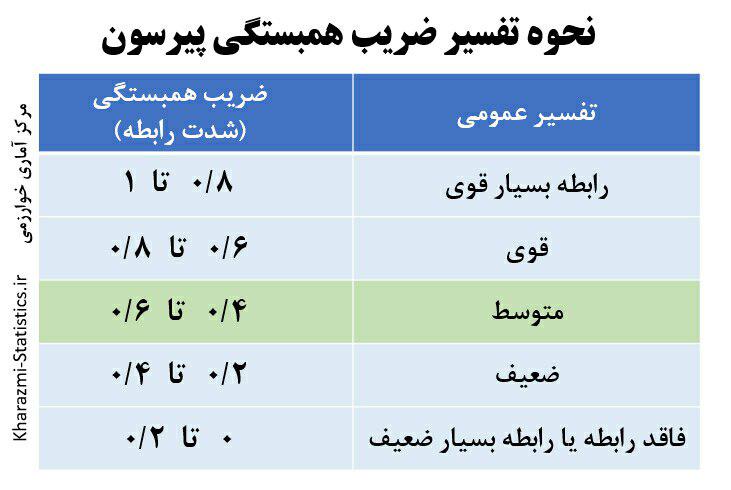
برای تعیین سازگاری یا انسجام، سؤالاتی از پرسشنامه که قرار است جنبههای یک مفهوم یا سازه را اندازهگیری کند، بایستی با یکدیگر همبستگی نسبتاً زیادی داشته باشند. یکی از روشهای اندازهگیری برای سازگاری درونی محاسبه نوعی پایایی است. پایایی یکی از مهمترین ویژگیها برای ابزارهای سنجشی است که جهت اندازهگیری متغیرها یا سازههای پنهان طراحی شدهاند. بدون داشتن یک ابزار پایا نمیتوان به نتایج پژوهش اعتماد کافی داشت و در صورت تکرار پژوهش، نتایج میتواند دارای تفاوت معنیدار با مرحله اول باشد. هر چند پایایی شرط کافی برای اعتماد و اطمینان به نتایج به بار آمده از یک ابزار سنجش نیست اما شرط ضروری و لازم است. برای سنجش هماهنگی درونی بین آیتمهای مختلف یک ابزار نیز از تکنیکهای مختلفی میتوان استفاده کرد که استفاده از ضریب آلفای کرونباخ یکی از آنهاست. هر قدر شاخص آلفای کرونباخ به یک نزدیکتر باشد همبستگی درونی بین سوالات یک پرسشنامه بیشتر و در نتیجه پرسشها همگنتر خواهند بود. غالباً ضریب آلفای بالای 0.7 مطلوب تلقی میشود و در صورت پایین بودن مقدار آلفا بایستی پرسشهای دارای ناهمگونی زیاد را حذف کرده تا به مقدار مطلوب نزدیک شود.
البته بایستی دقت نمود که زیاد بودن آن (بالای 0.9) همواره دلیل بر خوب بودن نیست زیرا اولاً ممکن است سؤالات با هم همخطی چندگانه و تکنیکی داشته باشند منظور اینکه سؤالات با هم همپوشانی بالایی دارند (کوواریانس مشترک آنها بالا است). به عبارت دیگر یک چیز را اندازه میگیرند که در این صورت بایستی یکی از سؤالاتی که همپوشانی بالایی دارد نگه داشت و مابقی را از پرسشنامه حذف نمود. ثانیاً ممکن است سؤالات با یکدیگر همبستگی کمی داشته باشند که بهتر است در این حالت به موارد دیگر که در گزارش spss میآید توجه نمود.
در جدول زیر دسته بندی ضریب آلفای کرونباخ آورده شده است:
از توزیعهای آماری برنولی، دوجمله ای، نرمال و ... میتوان به راحتی عدد تصادفی را در نرم افزار SPSS تولید نمود. برای این منظور لازم است به اندازه تعداد نمونهای که میخواهید عمل زیر را انجام دهید: فرض کنید 100 نمونه تصافی از توزیع دوجمله ای با پارامترهای n=10 و p=0.3 میخواهید. الگوریتم زیر را دنبال کنید. ما از ذکر جزئیات خودداری میکنیم.
1- در پنجره مشاهده دادهها، در ردیف 100 اُم عدد دلخواهی وارد کنید مثلا 0 یا 1.
2- در پنجره مشاهده متغیر، نام متغیر را تغییر دهید (مثلا rvbinomial) و تعداد رقم اعشار را روی صفر تنظیم کنید.
3- در منوی Transform گزینه Compute Variable انتخاب کنید.
4- در قسمت Target Variable نام متغیر خود را یعنی rvbinomial را وارد کنید.
5- در قسمت Numeric Expression دستور (RV.BINOM(10,0.3 را وارد کنید.
لازم به ذکر است که توابع تولید عدد تصادفی از توزیع های دیگر را میتوانید با انتخاب عبارت Random Numbers در بخش Function Group مشاهده نمایید که در قسمت Functions and Special Variables فهرست شدهاند.
حال روی دکمه Ok کلیک کنید.
(در صورت ظهور پنجرهای دیگر با عبارت سوالی Change existing variable روی عبارت Ok کلیک کنید)
6- نمونه تصافی شما تولید و در قسمت مشاهده دادهها قابل دستیابی میباشد.
توجه شود در صورتی که میخواهید اعداد تصادفی شما تکراری نباشد میبایست عددی که تکراری است را با اولین عدد متفاوتی که از تولید دوباره عدد تصادفی بدست میآورید جایگزین کنید.
آزمون فریدمن (Friedman) برای طرح های درون گروهی (نمونه های وابسته) مناسب است. آزمون فریدمن تعمیم یافته آزمون ویلکاکسون است و معادل ناپارامتریک آزمون اندازه های مکرّر است. در این آزمون ما یک گروه از افراد یا آزمودنی داریم که در حداقل دو وضعیت یا دو مقطع زمانی مختلف موردسنجش قرار گرفته اند. هدف این است که تغییرات نمرات (میانه) را در چند (2 و بیشتر) وضعیت یا مقطع زمانی مقایسه کنیم. سطح سنجش متغیر در این آزمون باید ترتیبی باشد. پژوهشگران عموما از این آزمون جهت رتبه بندی یا اولویت بندی متغیرها استفاده می کنند.
به عنوان نمونه می توانیم مثال مطرح شده در آزمون ویلکاکسون را توسعه دهیم و به مقایسه میزان رضایت از زندگی در سه مقطع قبل از ازدواج، یکسال بعد از ازدواج و ده سال بعد از ازدواج بپردازیم. می توانیم از مردم بپرسیم که از هرکدام از شرایط فرهنگی، سیاسی، اقتصادی و امنیتی کشور چقدر رضایت دارید و سپس به بررسی این امر بپردازیم که مردم از کدام یک از شرایط رضایت بیشتری دارند. می توانیم از تعدادی از صاحب نظران اقتصادی بپرسیم که هرکدام از عواملِ عدم وابستگی به درآمد نفتی، حمایت از تولید داخلی، افزایش وام های خوداشتغالی، بهبود شرایط گردشگری و آموزش نیروی انسانی چقدر در بهبود وضعیت اقتصادی کشور مؤثر هستند و سپس به اولویت بندی (رتبه بندی) پاسخ ها بپردازیم و بررسی کنیم که از نظر صاحب نظران کدام یک از عوامل فوق تأثیر بیشتری در بهبود وضعیت اقتصادی دارد.
مثال: پژوهشی با هدف تعیین و رتبه بندی"مهم ترین ویژگی های اساتید دانشگاه"در دانشگاه شیراز انجام شد و در آن از 100 دانشجوی دکتری دانشگاه شیراز پرسیده شد که نظر خودشان را در ارتباط با هرکدام از ویژگی های مطرح شده اساتید در پرسشنامه ابراز کنند. از دانشجویان پرسیده شد که تا چه حد به هرکدام از ویژگی های اساتید اهمیت می دهند؟ پنج ویژگی مطرح شده در ارتباط با اساتید عبارتند از: تسلط علمی، اخلاق خوب در روابط با دانشجویان، ظاهر مرتب و آراسته، فن بیان مناسب و رعایت انصاف در نمره دهی. دانشجویان به هرکدام از ویژگی های مطرح شده در قالب طیف 11 گزینه ای (از 0 تا 10 که نمره بالاتر به معنای اهمیت بیشتر است) نمره دادند.
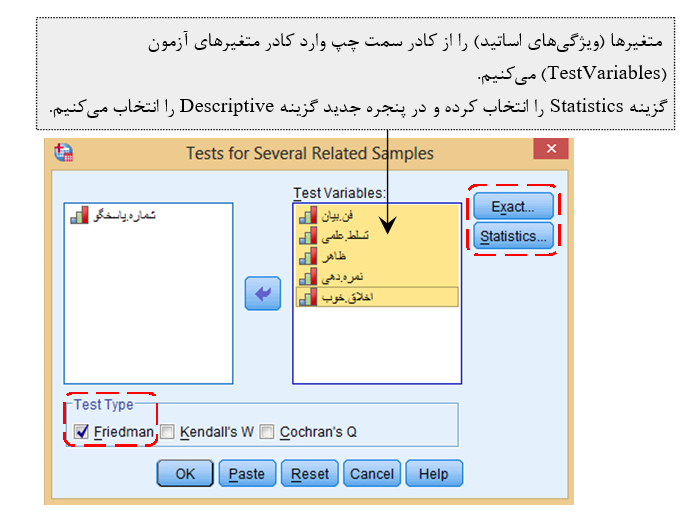
بر این اساس سوال زیر طرح و آزمون شد: کدام ویژگی های اساتید اهمیت بالاتری برای دانشجویان دارد؟ با استفاده از آزمون فریدمن سوال مطرح شده را ارزیابی میکنیم.
اجـ ـرا: مسیر زیر را دنبال میکنیم:
Analyze --->Nonparametric Tests --->Legacy Dialogs --->K Related Samples
نتـ ـایج: در جدول بعد میانگین و انحراف استاندارد متغیرها ارائه شده است. دامنه میانگین از 0 تا 10 است. مقایسه میانگین ویژگی های اساتید نشان می دهد که بالاترین میانگین (7.79) متعلق به ویژگی انصاف در نمره دهی و پایین ترین میانگین (3.31) متعلق به ویژگی ظاهر آراسته است. جهت بررسی معنی دار بودن تفاوت بین ویژگیهای اساتید و رتبه بندی مهم ترین ویژگی های اساتید از نظر دانشجویان، باید نتایج جدول آخر (Test Statistics) را بررسی کنیم.
Descriptive Statistics
N
Mean
Std. Deviation
Minimum
Maximum
فن بیان
100
4.99
1.83
2
9
تسلط علمی
100
4.48
1.66
2
10
اخلاق خوب
100
5.01
1.79
2
10
انصاف در نمره دهی
100
7.79
1.55
5
10
ظاهر آراسته
100
3.31
2.01
0
8
جدول زیر وضعیت رتبه بندی متغیرها (ویژگیهای اساتید) را نشان می دهد. میانگین رتبه (Mean Rank) هرکدام از ویژگی ها در جدول گزارش شده است. مقایسه میانگین رتبه ها نشان می دهد که بالاترین میانگین رتبه (4.58) به ویژگی انصاف در نمره دهی اختصاص دارد و که بدین معناست که مهم ترین ویژگی استاد از نظر دانشجویان ویژگی انصاف در نمره دهی است. بعد از ویژگی فوق، مهم ترین ویژگی اساتید به ترتیب شامل ویژگی های فن بیان مناسب، اخلاق خوب در روابط با دانشجویان، تسلط علمی و ظاهر مرتب و آراسته می شود. لازم به ذکر است که میانگین رتبه با میانگین حسابی تفاوت دارد و نحوه محاسبه این دو میانگین متفاوت است.
Ranks
Mean Rank
فن بیان
3
تسلط علمی
2.56
اخلاق خوب
2.93
انصاف در نمره دهی
4.58
ظاهر آراسته
1.94
جدول زیر مهم ترین جدول آزمون فریدمن است که قبل از تفسیر جداول دیگر نخست باید نتایج این جدول را ارزیابی کرد و در صورت معنی دار بودن آزمون فریدمن، به تفسیر نتایج جداول توصیفی و میانگین رتبه بپردازیم. این جدول معنی داری آماری را نشان می دهد. مقدار مجذور کای به دست آمده برابر با 163.7 است که در سطح خطای کمتر از 05/. قرار دارد (05/.>P). معنی دار بودن آزمون فریدمن بدین معناست که رتبه بندی ویژگیهای اساتید از نظر دانشجویان بامعناست و دانشجویان رتبه بندی متفاوتی از ویژگی های اساتید دارند.
Test Statisticsa
N
100
Chi-Square
163.75
df
4
Asymp. Sig.
000.
a. Friedman Test
گـ ـزارش: از آزمون فریدمن برای رتبه بندی مهم ترین ویژگی های اساتید استفاده شد. آزمون فریدمن نشان داد که اهمیت و رتبه ویژگی های مطرح شده در مورد اساتید با یکدیگر متفاوت است(001/. >P، 4 = df، 163.74= مجذور کای). مقایسه میانگین رتبه ها نشان میدهد که مهم ترین ویژگی اساتید از نظر دانشجویان به ترتیب ویژگی انصاف در نمره دهی، فن بیان مناسب و اخلاق خوب در روابط با دانشجویان است. میانگین رتبه این ویژگی ها به ترتیب 4.58، 3 و 2.93 است(میانگین رتبه همه ویژگیها را در یک جدول گزارش کنید).
تا کنون به احتمال زیاد برای بررسی تاثیر یک یا چند متغیر روی یک متغیر دیگر از تحلیل رگرسیون (Regression analysis) استفاده می کردید. اما همانطور که می دانید در هر باراجرای تحلیل رگرسیون تنها می توانید یک متغیر وابسته ( Dependent variable ) داشته باشید.ضمناً زمانی میتوانید از تحلیل رگرسیون استفاده کنید که هر متغیر در مدل تنها یکی ازنقش های پیش بینی کننده (Predictor) یا نتیجه ( Outcome ) را بازی کند. به عبارت دیگریک متغیر نمی تواند همزمان هم پیش بینی کننده و هم نتیجه و پی آمد باشد. البته شاید بهترباشد به جای اینکه ادعا کنیم در چنین مدل هایی نمی توانیم از تحلیل رگرسیون استفاده کنیم ،بگوییم تحلیل چنین مدل هایی با استفاده از این روش دشوار بوده و مستلزم چندین بار اجرای تحلیل خواهد بود و در آخر هم ترکیب نتایج به دست آمده و نتیجه گیری نهایی کار چندان راحتی نیست. برای حل این مشکل از تحلیل مسیر ( Path Analysis ) استفاده می کنیم. تحلیل مسیر که تعمیم یافته ی تحلیل رگرسیون است نه تنها امکان تحلیل چندین متغیر وابسته در یک زمان را به شما می دهد، بلکه در این تحلیل یک متغیر میتواند همزمان دو نقش پیش بینی کننده و نتیجه را در مدل بازی کند. اما کار به همین جا ختم نمی شود و در قدم بعدی به مدل معادلات ساختاری یا Structural Equation Modeling می رسیم. مدل معادلات ساختاری که از این پس آنرا SEM می نامیم نه تنها تمام قابلیت ها و مزایای تحلیل مسیر را دارد بلکله درSEM می توانیم متغیر پنهان ( Latent variable ) هم داشته باشیم!
دانشجویان مجموعه بزرگی از افراد کشور هستند که به مطالعه کتب تخصصی رشته خود احتیاج دارند و یکی از مسائلی که با آن درگیرند، پیدا کردن کتاب های تخصصی شان از بین تنوع بالای کتاب های دانشگاهی می باشد که این موضوع با سایت های آنلاین که کتاب های دانشگاهی را به تفکیک رشته های گوناگون گروه بندی کرده و انواع کتاب ها را در دسترس کلیه دانشجویان قرار داده به آسانی حل شده است. از آنجایی که کتاب های دانشگاهی رشته های گوناگون بسیار حائز اهمیت هستند، ناشران بسیاری در حوزه نشر و پخش کتب دانشگاهی در بازار رقابت می کنند
اما با توجه به هزینه بالای دریافت این کتابها از سایتهای خارجی از قبیل آمازون برای محققین عزیز، استفاده از منابعی که این کتابها را به صورت رایگان در اختیار ما قرار میدهند (سایت دانلود کتاب خارجی)، راه مناسبی است. دانلود رایگان کتاب و در واقع دانلود کتاب دانشگاهی و دانلود کتاب علمی در بعضی سایتهای رایگان دانلود کتاب امکانپذیر است و فقط باید آنها بشناسید. اگر شما هم به دنبال یافتن سایتهایی جهت دانلود کتاب دانشگاهی مد نظر خود یا دانلود کتاب علمی خاصی هستید، این مطلب پاسخی برای نیاز شماست.
سایت FreeBookSpot
یکی از بهترین سایت های دانلود رایگان کتاب خارجیسایت FreeBookSpot است. این وبگاه، مجموعه عظیمی از کتاب الکترونیکی رایگان در بیش از ۱۰۰ زمینه موضوعی مختلف برای کاربران فراهم کرده است. حدود ۴۵۰۰ کتاب الکترونیکی در موضوعات برنامهنویسی، مهندسی، ستارهشناسی، داستانی، علمی و … در این سایت موجود است. در این وبگاه دانلود کتاب بدون نیاز به ثبتنام امکانپذیر است و شما میتوانید کتب را بر اساس عنوان، نام نویسنده، شابک و زبان جستجو کنید. در این سایت بخشهایی با عنوان پرطرفدارترین کتب و آخرین کتب دانلود شده نیز موجود است.
سایت LibGen
شما میتوانید کتابهای مد نظر خود را از سایت LibGen به آدرس gen.lib.rus.ecدانلود نمایید. تقریباً هر کتاب علمی و دانشگاهی را میتوانید در اینجا بیابید. مخصوصا اگر یکی دو سالی از انتشار آن گذشته باشد.
با داشتن نام کامل کتاب، نام نویسندگان یا شماره بینالمللی کتاب میتوانید از این سایت کتابهای تخصصی خود را دانلود کنید. فرمت کتابهای موجود در این کتاب pdf یا djvu بوده و برای نمایش کتاب دریافتی ممکن است به نرمافزار مخصوص نیاز داشته باشید. دانلود کتاب دانشگاهی و دانلود کتاب علمی از این سایت معمولاً رایگان است.
سایت Scribd
دیگر سایت دانلود رایگان کتاب خارجی Scribd است. این سایت در واقع یک سایت اشتراکگذاری فایلهای مختلف میباشد. شامل بیش از ۱ میلیون کتاب دیجیتال و کتاب صوتی از بیش از ۱۰۰۰ ناشر میباشد. علاوه بر این، بیش از ۶۰ میلیون انواع مدارک اعم از کتب غیرداستانی، حلالمسائل و راهنماهای آموزشی، مجلات، مقالات علمی پژوهشی، کتاب صوتی، اسناد و مدارک، روزنامهها و مجلات، مقالات و مطالب خبری، بروشورها، اسناد حقوقی و تجاری، اسناد دولتی، کمیکها، خاطرات، نامهها، ارائهها، نوشتارهای خلاقانه، فرمهای حقوقی، نقشهها، نشریات ادواری، گزارشات، تحقیقات علمی، رزومهها و سی وی ها، نقد و بررسیها، سخنرانیها، تألیفات و کارهای درسی و را دربرمی گیرد. این وبگاه شامل بیش از ۸۰ میلیون کاربر از بیش از ۱۹۴ کشور است. دارای نرمافزارهای مخصوص رایانههای شخصی، گوشیهای هوشمند و تبلت های آندرویدی و IOS، کیندل فایر، NOOK میباشد. فرمت فایل های موجود در این سایت بسیار متنوع است مانند PDF، Excel، Word، PPT، txt و …
سایت BookSee
یکی دیگر از سایتهای معتبر برای دانلود کتاب های علمی و دانشگاهی، سایت BookSee به نشانی booksee.orgاست. از طریق این سایت نیز میتوانید با داشتن نام کتاب مد نظر خود، کتابهای تخصصی علمی را دانلود نمایید. بانک داده این سایت شامل نزدیک به ۲٫۵ میلیون کتاب الکترونیک است. سایت booksee.org هم نسخه دسکتاپ و هم نسخه موبایل دارد و کار کردن با آن در دستگاههای موبایل نیز میسر است. دانلود کتاب علمی و دانلود کتاب دانشگاهی از سایت booksee.org نیز رایگان است.
سایت BookYards
سومین سایت معتبر برای دانلود کتابهای انگلیسی علمی، سایت BookYard به نشانی bookyards.comاست. این سایت بانک داده ای شامل ۲۳۰۰۰ کتاب الکترونیکی دارد و این تعداد کتاب روز به روز به کمک مخاطبان سایت در حال گسترش است. دانلود کتاب های مختلف اعم از دانشگاهی و غیر دانشگاهی از این سایت رایگان بوده و امکانات دیگری از قبیل دانلود نرمافزارهای موبایل رایگان نیز دارد.
سایت DOAbooks
سایت DOABooks به نشانی doabooks.org محلی برای دسترسی به کتابهای آزاد است. این سایت در حقیقت یک دایرکتوری با دسترسی همگانی به کتاب هاست. افرادی که کتابی برای انتشار دارند به این وب سایت برای انتشار کتاب خود اعتماد میکنند و مخاطبان نیز میتوانند از این سایت نسبت به دانلود کتاب دانشگاهی مد نظر خود اقدام کنند. اگر به دنبال دانلود کتاب از یک منبع رایگان هستید، این سایت جای خوبی برای نیاز شماست زیرا بانک داده این سایت شامل ۱۱۰۰۰ کتاب است و امکان دانلود کتاب را برای شما فراهم کرده است.
سایت BookBoon
سایت BookBoon به نشانیbookboon.com دایرکتوری بسیار بزرگی از کتب الکترونیکی قابل دانلود در زمینههای مختلف علمی از قبیل مهندسی کامپیوتر و آی تی، آمار و ریاضی، علوم طبیعی، برنامهنویسی، مهندسی، مدیریت و حسابداری است و دانشگاهیان محترم میتوانند کتاب مد نظر خود را به راحتی از آن دریافت کنند. همچنین لیستی شامل محبوبترین کتب از نظر کاربران در سایت موجود است که میتواند راهنمای کسانی باشد که قصد ترجمه کتاب دارند. البته این سایت در کنار لیستی از کتابها که امکان دانلود رایگان کتاب برای آنها فراهم شده است، بخشی از کتابهای خود را نیز به صورت اختصاصی برای اعضا منتشر میکند.
در این مقاله روش معادلات ساختاری با رویکرد بیزی در نرم افزار AMOS آموزش داده می شود. یکی از مهم ترین ویژگی های نرم افزار AMOS در ویرایش جدید، آن است که با استفاده از روش بیزی می تواند به برآورد پارامترها در مدل هایی بپردازد که متغیرهای حاضر در آن ها از نوع رتبه ای یا اسمی هستند. البته این ویژگی در نگارش اولیه این نرم افزار وجود نداشت. به طور کلی مدل سازی معادله ساختاری بیزی از ویژگی های ارزشمند نرم افزار AMOS است.
مزایای تحلیل معادلات ساختاری بیزی
1- در مواقعی که حجم نمونه کم است استفاده از رویکرد معادلات ساختاری بیزی مناسب است. در حالی که برآورد حداکثر درست نمایی نسبت به برآورد بیزی در نمونه های کوچک، تمایل بیشتری به رد مدل دارد (موتن و آسپاروهو، 2012). هنگامی که حجم نمونه زیاد است و همه ی پارامترها دارای توزیع نرمال می باشند برآورد پارامترهای بیزی و حداکثر درست نمایی یکسان خواهد بود (ون دی شوت و همکاران، 2014).
2- تجزیه و تحلیل بیزی در برخورد با پارامترهایی که توزیع آن ها نرمال نیست، می تواند دقت بیشتری داشته باشد. به عنوان مثال، برآورد بیزی جایگزین مناسبی برای استفاده از آزمون سوبل و یا انجام بوت استرپ در هنگام آزمون اثرات غیر مستقیم در مدل های دارای متغیر میانجی است (ون دی شوت و همکاران، 2014).
3- تجزیه و تحلیل بیزی می تواند در حذف پارامترهای غیر قابل قبول مفید باشد. (منفی بودن واریانس و یا بیشتر بودن مقدار همبستگی از یک).
مزایای روش معادلات ساختاری بیزی در نرم افزار AMOS
1- در نرم افزار AMOS، مواقعی که داده پرت وجود داشته باشد امکان این که از روش بوت استرپ برای آزمون اثرات غیر مستقیم استفاده شود وجود ندارد. اگر چه برای این مشکل در ادبیات پیشین راه حل هایی پیشنهاد شده است با این حال روش بیزی راه حل راحت تری برای آزمون اثرات غیر مستقیم می باشد.
2- روش معمول و استاندارد برآورد پارامتر (برای مثال روش برآورد حداکثر درست نمایی) در نرم افزار AMOS فرض می کند متغیرهای تحقیق دارای توزیع نرمال چند متغیره است. زمانی که این فرض نقض می شود به ویژه زمانی که متغیر وابسته تحقیق از نوع ترتیبی باشد، روش برآورد بیزین می تواند مفید واقع گردد.
توزیع های پیشین و پسین
آمار بیزی به طور کلی از یک توزیع خاص پیشین شروع می شود. یعنی بیان باور قبلی شخص (قبل از مشاهده داده ها) در مورد این که پارامتر مورد نظر به چه صورت در جامعه توزیع شده است (بیرن، 2016). در طول تحلیل بیزین، این باور پیشین با دیتای جدید ترکیب شده و بدین ترتیب توزیع جدیدی بدست می آید که به آن توزیع پسین گفته می شود (آربوکل، 2017). توزیع پسین بدست آمده در واقع نشان دهنده اطلاعات جدید بروز شده (به وسیله داده) در خصوص پارامتر جمعیت می باشد (ون دی شوت و همکاران، 2014).
توزیع پیشین می تواند مبتنی بر تحقیقات مهم (از جمله متا آنالیزها) و یا تجربه باشد. در این حالت پیشین محقق، پیشین آگاهی بخش (حاوی اطلاعات مفید) نام دارد. از طرف دیگر اگر اطلاعات پیش زمینه ای کمی در خصوص پارامتر جامعه وجود داشته باشد به طوری که آگاهی کمی در خصوص پارامتر دهد محقق می تواند از پیشین نا آگاهی بخش (دارای اطلاعات غیر مفید) استفاده کند. که در حقیقت یک پیشین نا آگاهی بخش، جهل (نادانی) در خصوص پارامتر جمعیت را نشان می دهد.
ارزیابی مدل معادلات ساختاری به روش بیزی
پی-مقدار پسین پیشگویانه (posterior predictive p-value) می تواند برای ارزیابی فیت یک مدل واحد استفاده شود. به عبارتی دیگر، این سؤال را مطرح می کند که چگونه داده های تولید شده (شبیه سازی یا تکرار شده) از روش بیزی با داده های مشاهده شده متناسب می باشند (کاپلان و دپائولی، 2012).
نحوه قضاوت با پی-مقدار پسین پیشگویانه (posterior predictive p-value)
موتن و آسپاروهو (2012) نشان داده اند که اگر مقدار پی-مقدار پسین پیشگویانه نزدیک به 0.5 باشد مدل تحقیق از برازش بسیار خوبی برخوردار است. با این حال آن ها هیچ نوع تئوری و یا اطلاعات تجربی در خصوص این که به چه میزان مقدار (PPP) کم باشد تا محقق مدل را رد کند ارائه نداده اند. آن ها پیشنهاد کردند که برای رد یا تایید مدل با مقدار PPP باید بیشتر شبیه به یک شاخص برازش معادلات ساختاری (مانند NFI، GFI و …) برخورد شود تا مانند یک آزمون آماری (Chi-Square). به گفته این نویسندگان، بهتر است آستانه PPP برای رد مدل، در سطوح 1 درصد، 5 درصد و یا 10 درصد در نظر گرفته شود.
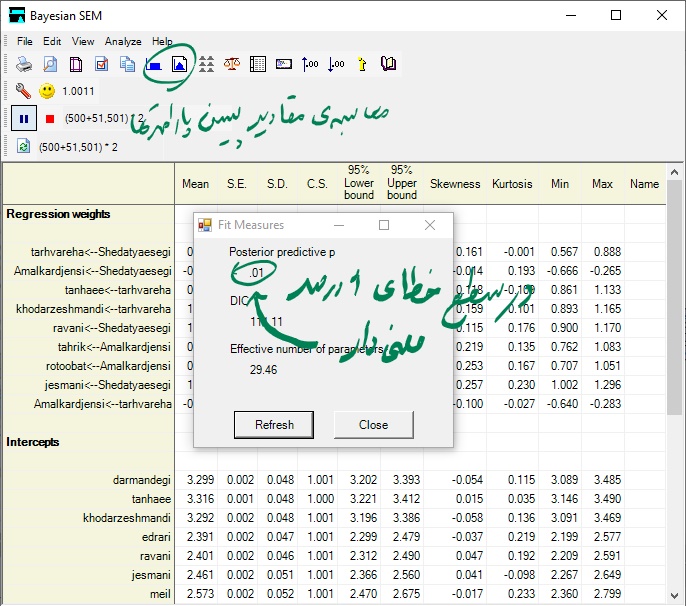
همچنین برای ارزیابی مدل شاخص (DIC) وجود دارد که برای مقایسه مدل، با مدل های رقیب به روشی شبیه به رویکرد در نظر گرفته شده با معیار AIC استفاده می شود. ون دی شوت و همکاران (2017) بیان می کند که “با در نظر گرفتن AIC و BIC، مدل های با مقدار DIC کمتر باید ترجیح داده شوند.” همچنین ببینید : (Bayesian Fit Measures).
ارزیابی در خصوص برآورد ضرایب و پارامترها
ارزیابی پارامترهای مدل در رویکرد معادلات ساختاری بیزی توسط فاصله های قابل قبول انجام می شود. یک فاصله قابل قبول می تواند به عنوان “احتمال که پارامتر مورد نظر در یک بازه خاص قرار دارد تعبیر شود” (کاپلان و دپائولی، 2012). این تعریف می تواند با معنای فواصل اطمینان در آمار، در تضاد باشد. برای مثال در تعریف فاصله اطمینان داشتیم : 95 درصد فواصل بدست آمده پارامتر مجهول مورد نظر را دربردارند (ون دی شوت و همکاران، 2014).
آزمون فرضیه ها در خصوص معنی داری یا عدم معنی داری ضرایب رگرسیونی در روش معادلات ساختاری بیزی در نرم افزار AMOS با استفاده از این فواصل قابل قبول انجام می گیرند به طوری که اگر عدد 0 در فاصله قابل قبول ضریب مورد نظر بود، فرض صفر مبنی بر عدم معنی داری ضریب رگرسیونی (ضریب رگرسیونی برابر با صفر است) رد نمی گردد.
همگرایی مدل معادلات ساختاری با رویکرد بیزی
معادلات ساختاری بیزی از یک روش مبتنی بر شبیه سازی برای تخمین پارامترهای مدل و توزیع پسین استفاده می کند. این امر مستلزم این است که محقق قبل از ارزیابی مناسب بودن مدل، تعیین کند که آیا مدل همگرا شده است یا خیر (بیرن، 2016). یکی از معیارهای همگرایی در نرم افزار AMOS، معیار آماره همگرایی (CS) است. مقدار CS کمتر از 1.002 نشان دهنده همگرایی مدل است. در این مرحله می توان شبیه سازی را متوقف کرده و سپس مدل را ارزیابی نمود. (آربوکل، 2017).
نحوه انجام معادلات ساختاری بیزی در نرم افزار AMOS
برای تحلیل آماری بیزی در نرم افزار AMOS مدل فرضی زیر را در نظر می گیریم. قصد داریم پارامترهای مدل قرار داده شده را به وسیله رویکرد بیزی برآورد کنیم.
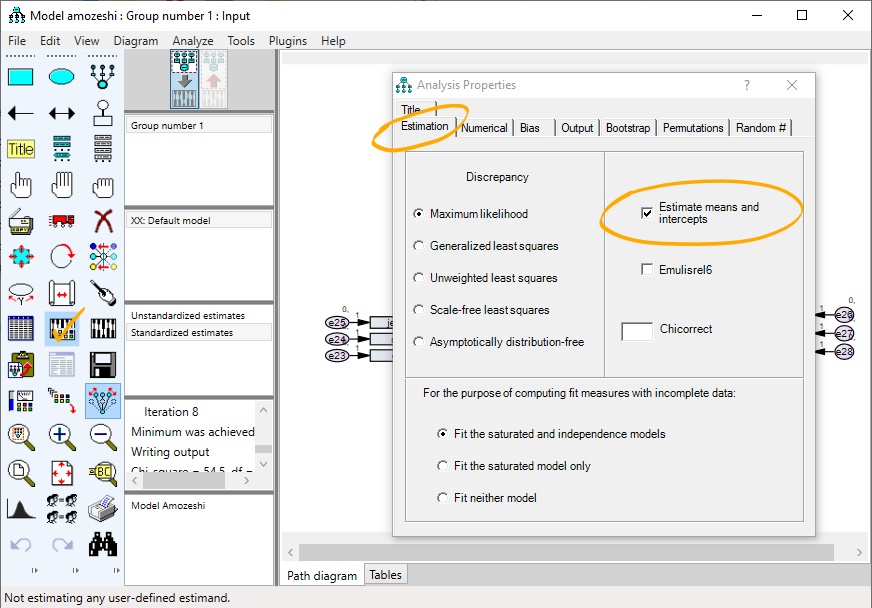
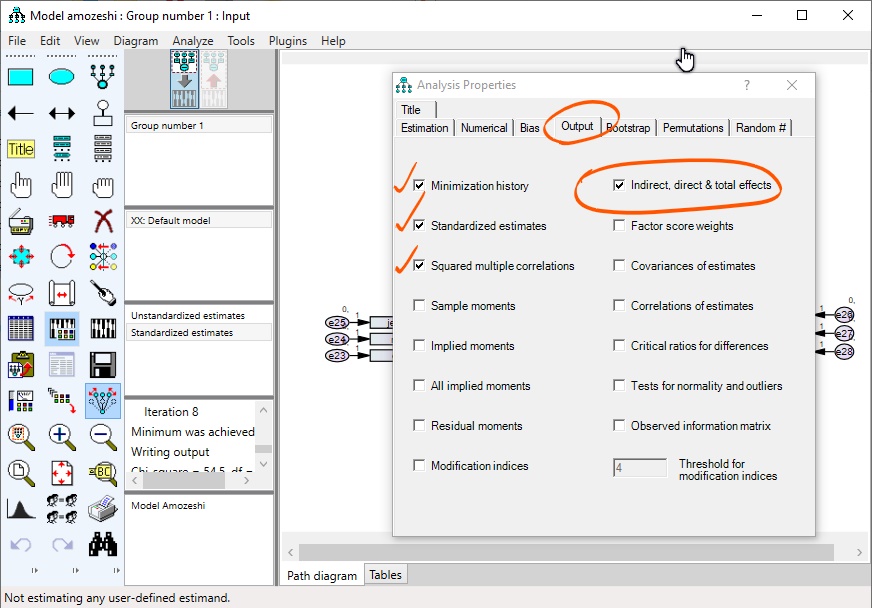
برای برآورد بیزی لازم است تیک گزینه (Estimate means and intercepts) را از زبانه Estimation موجود در پنجره ی Analysis Properties مانند شکل زیر فعال شود.
پس از انجام مرحله قبل لازم است که در زبانه Output موجود در پنجره ی Analysis Properties تیک گزینه های مورد نظر مانند شکل زیر فعال گردد. در اینجا ما قصد داریم مقدار اثرات مستقیم و غیر مستقیم به روش بیزی را مشاهده کنیم.
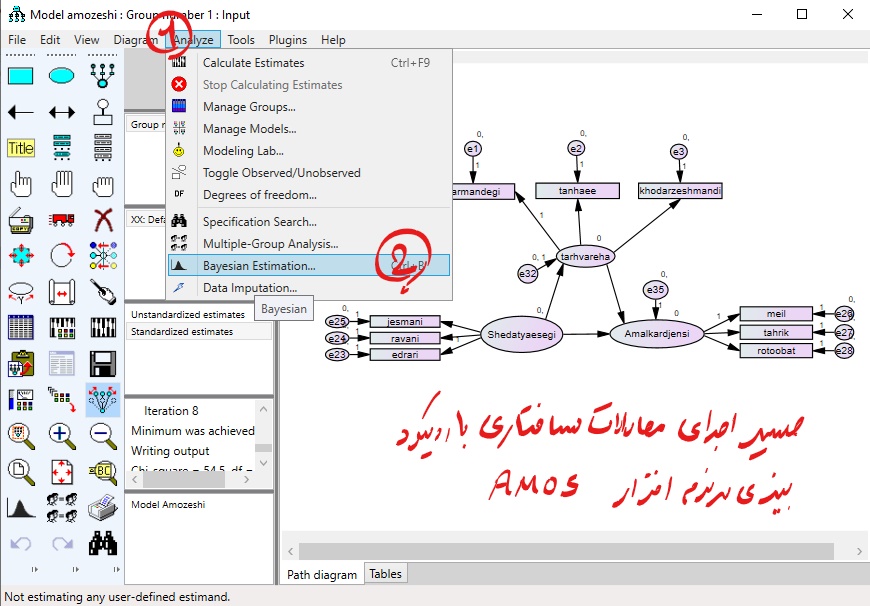
پس از انجام مراحل گفته شده از طریق منوی Analyze مدل را به روش بیزی تخمین می زنیم. دستور انجام تحلیل بیزی در نرم افزار AMOS به صورت زیر است :
برآورد پارامترهای مدل به روش بیزی در AMOS
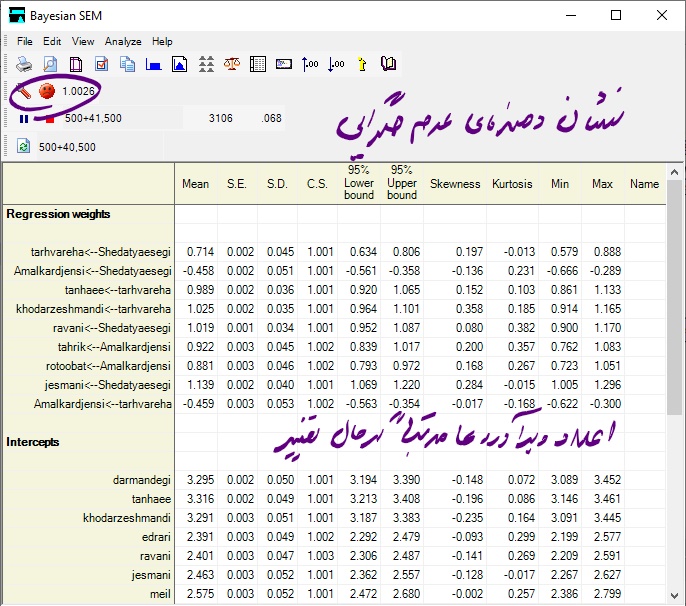
پس از اجرای دستور فوق پنجره جدیدی تحت عنوان Bayesian SEM باز می شود. در این زمان، نرم افزار در حال شبیه سازی داده برای برآورد پارامترها است. مقدار پارامترهای بدست آمده مرتبا در حال تغییر هستند و شکلک بالا سمت چپ که بیانگر همگرایی مدل است اگر در حالت ناراحت باشد نشان دهنده عدم همگرایی است و اگر در حالت لبخند باشد نشان دهنده این است که مدل همگرا شده است و می توانیم عمل شبیه سازی را متوقت کنیم و به سراغ ارزیابی مدل و پارامترها بپردازیم.
مانند شکل زیر پس از گذشته چند ثانیه مدل به حالت همگرا در می آید (شکلک خوشحال) و از آن به بعد برآورد پارامترها با کمترین تغییر عوض می شوند. حال وقت آن است که محقق عملیات شبیه سازی را متوقف کند.
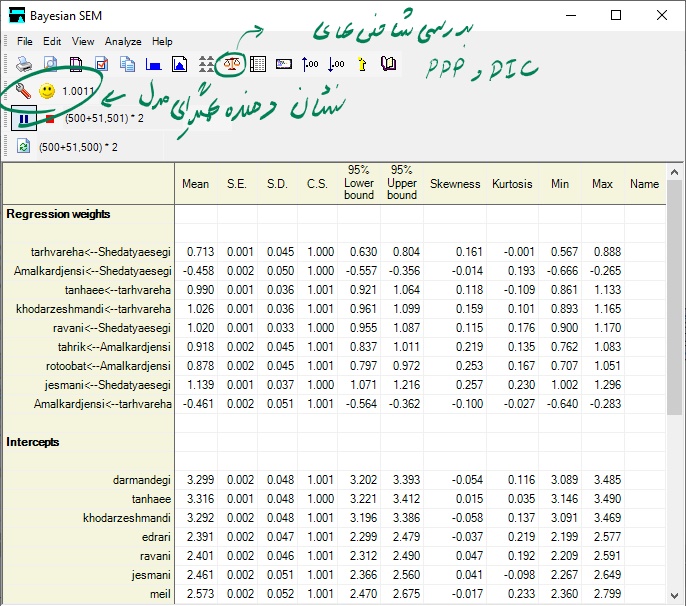
پس از متوقت کردن شبیه سازی، از طریق دکمه مشخص شده در شکل بالا (Fit measures) شاخص های ارزیابی برازش مدل را بررسی می نماییم.
همانطور که مشاهده می شود مقدار PPP برابر 0.01 بدست آمده که در سطح خطای 1 درصد قابل قبول است. هر چند همانطوری که در ابتدای مقاله به آن اشاره کردیم نباید به این شاخص به دید آزمون آماری نگاه کرد. بنابراین با مقدار بدست آمده دچار مشکل نخواهیم شد.
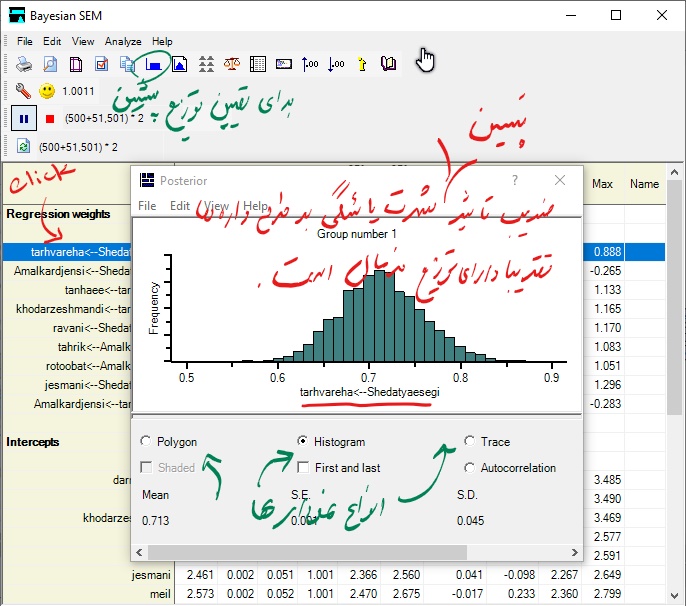
توزیع های پیشین و پسین در نرم افزار AMOS
پس از کلیک بر روی گزینه (Posterior) در قسمت بعدی مقادیر پسین برای پارامترهای مورد نظر مشاهده می شود.
برای بدست آوردن مقدار شاخص های پسین مورد نظر (میانگین و انحراف معیار و …) لازم است که پس از باز شدن پنجره Posterior مانند شکل فوق روی پارامتر مورد نظر خود کلیک کنید. همانطوری که از نمودار هیستوگرام ضریب تاثیر شدت نشانه های یائسگی بر عملکرد جنسی مشاهده می شود، توزیع این پارامتر تقریبا دارای توزیع نرمال است.
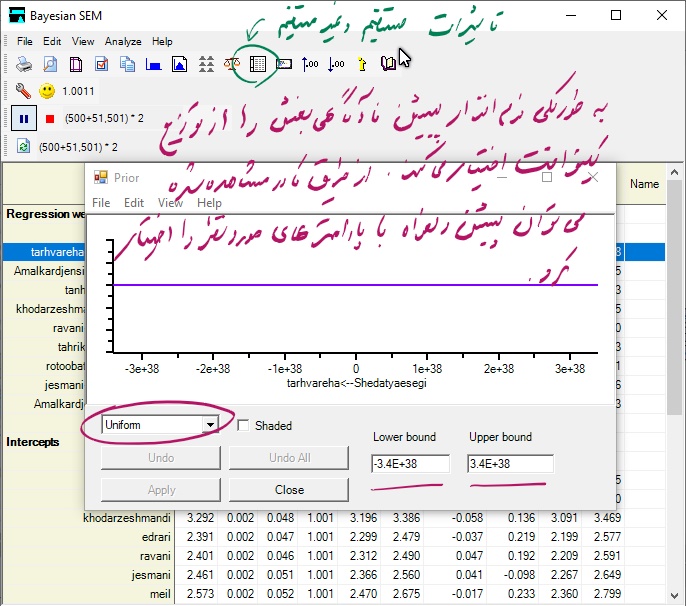
همانطوری که در شکل فوق نشان داده شده است با کلیک بر روی دکمه Prior پنجره ای با همین نام مانند شکل زیر باز می شود. لازم است که پس از باز شدن پنجره Posterior مانند شکل زیر روی پارامتر مورد نظر خود کلیک کنید.
همانطوری که در شکل فوق ملاحظه می شود نرم افزار AMOS به صورت پیش فرض از پیشین نا آگاهی بخش یونیفرم (یکنواخت) استفاده می کند. از طریق کادر نشان داده شده می توان پیشین مورد نظر را انتخاب نمود. همچنین می توان توزیع آن را بر روی نمودار رسم کرد.
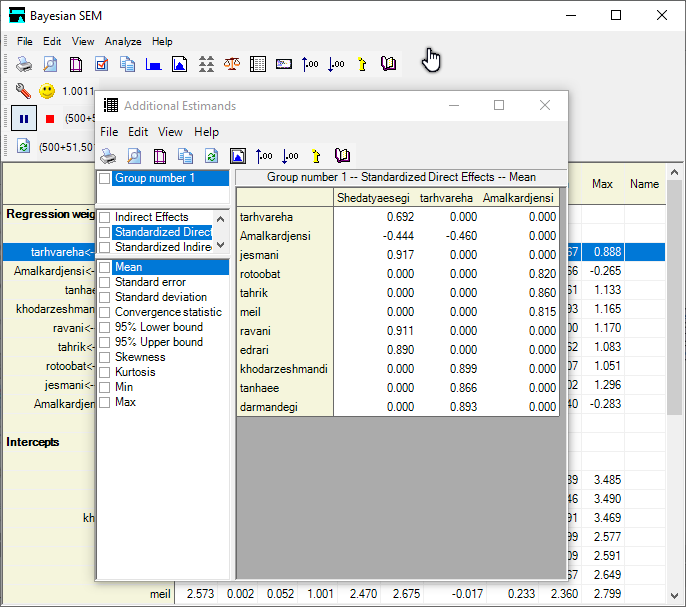
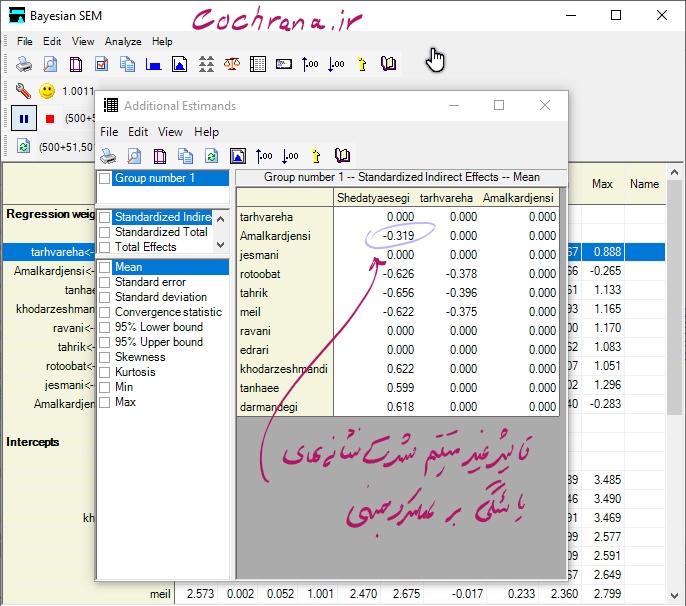
پس از انجام مراحل فوق وقت آن است که از طریق دکمه (Additional estimands) مقدار اثرات مستقیم و غیر مستقیم متغیرهای تحقیق مشاهده شود. نتایج در شکل زیر گزارش شده است :
شکل فوق مقادیر اثرات مستقیم استاندارد شده با روش معادلات ساختاری با رویکرد بیزی را نشان می دهد. به عنوان مثال اثر مستقیم استاندارد شده تاثیر شدت نشانه های یائسگی بر طرحواره های روانشناختی برابر 0.692 بدست آمده است.
همانطوری که مشاهده می شود مقدار اثر غیر مستقیم استاندارد شده شدت نشانه های یائسگی بر عملکرد جنسی از طریق متغیر میانجی طرحواره های روانشناختی برابر 0.319- بدست آمده است.
یک پژوهشگر برای نگارش پروژه ها و مقالات علمی خود نیاز به موتور های جستجو، بررسی ایده های جدید، تقویت رزومه خود در فضای آنلاین، دسترسی رایگان به بانک های مقالات روز، ابزار های نگارش مقالات، ترسیم نمودار ها، گرفتن بودجه و اسپانسر برای تحقیقات خود، پیدا کردن ژورنال مناسب برای ارسال مقالات خود، گرفتن بازخورد از دیگر محققان، پیدا کردن اساتید و همکاران خارجی برای کارهای خود، عضویت در شبکه های اجتماعی علمی، فضاهای ابری برای اشتراک جزوات و ارائه ها و … و صد ها ابزار دیگر دارد. این نوشتار دقیقا معادل یک کلاس و دوره سرچ و جستجو می باشد.
این مقاله و نوشتار در حقیقت یکی از نوشتار های مرجع از طرف آکادمی تحلیل آماری ایران می باشد و مدت زمان و تعداد ساعات بسیار زیادی را برای جمع آوری آن وقت صرف کرده ایم تا عزیزان به ابزار جستجو و سرچ قدرتمند مجهز شوند و تمام پایگاه هایی که در دوره سرچ قرار بر واکاوی آن ها بود را با یک توضیح یک خطی در اختیار شما عزیزان قرار می دهیم. هر محقق بیش از نیمی از پژوهش خود را در فضای اینترنت انجام می دهد اما متاسفانه سرچ و جستجوی او محدود به چند سایت معروف می باشد و در بسیاری از مواقع این پایگاه ها نیاز های او را برآورده نمی سازد. بنابراین با یک پیمایش طولانی سایت ها و پایگاه هایی که یک محقق به آن نیاز خواهد داشت را در بخش های مختلف همراه با توضیحی کوتاه در مورد آن سایت به همراه لینک آن سایت در این نوشتار قرار داده ایم. امیدواریم بتوانیم با این نوشتار در جهت ارتقای کیفیت پژوهش های عزیزان حرکت کرده باشیم.
در اینجا مجموعه ای از ابزارهای دیجیتالی طراحی شده است که به محققان کمک می کند تا میلیون ها مقاله تحقیقاتی موجود در.فضای آنلاین را پیدا نمایید. موتورهای جستجو به شما کمک می کنند که مقالات مورد علاقه خود را سریع پیدا کنید و از نظر ادبیات پژوهشی به روز باشید.
موتورهای جستجو
BibSonomy نشانک ها و لیست ادبیات را به اشتراک بگذارید.
wizdom فضایی برای استناد و کتابشناسی ایجاد کنید و گروه های تحقیقاتی خود را بر روی آن فضای ابری ایجاد کنید تا پرونده ها و منابع را به اشتراک بگذارید.
ContentMine دسترسی به بیش از 100،000،000 مطالعه بهره گیری از این ادبیات نظری
Data Elixir مجموعه ای هفتگی از بهترین اخبار علوم داده ، منابع از سراسر وب.
Delvehealth مجموعه ای از داده های کارآزمایی بالینی جهانی ، پروفایل های محقق بالینی ، انتشارات و خطوط تولید دارو.
F1000Prime متخصصان برجسته زیست پزشکی به دانشمندان در کشف ، بحث و انتشار تحقیقات کمک می کنند.
Google Scholar راهی را برای جستجوی گسترده ادبیات علمی در بین رشته ها و منابع فراهم می کند.
Labii مجموعه ای از برنامه های وب برای محققان ، از جمله یک برنامه آنلاین برای یافتن ، اظهار نظر ، رتبه بندی و مدیریت مقالات تحقیقاتی
LazyScholar افزونه Chrome برای جستجوی ادبیات شما. این افزونه را نصب کنید و مقالات مورد نیاز خود را دریافت نمایید.
LiteracyTool وبسایتی آموزشی است که کمک می کند تا در کشف ، درک و اکتشاف موضوعات علمی مورد علاقه خود اطلاعات لازم را بدست آورید.
Mendeley یک پلت فرم منحصر به فرد شامل شبکه های اجتماعی ، مدیر مرجع ، ابزارهای مطالعه مقاله.
Microsoft Academic اطلاعات مربوط به مقالات آکادمیک ، نویسندگان ، کنفرانس ها ، ژورنال ها و سازمان ها را از منابع مختلف پیدا کنید. این سایت متعلق به ماکرو سافت است و شمارا کمک بسیاری خواهد کرد.
MyScienceWork انتشار اطلاعات و دانش علمی به روشی آزاد و در دسترس تمام متن
paperity جمع آوری مقالات و مجلات دسترسی آزاد و تمام متن
Paperscape مخزن باز و آنلاین برای مقالات تحقیق علمی.
PubPeer جستجوی انتشارات و ارائه بازخورد از تحقیقات منتشر شده یخود را در این سایت انجام دهید.
ReadCube این سایت مدعی است که ما فناوری هایی را توسعه می دهیم که دنیای پژوهش را در دسترس تر و متصل تر می کند.
Scientific Journal Finder این سایت در حقیقت یکی از مهمترین سایت های یابنده ژورنال مناسب برای چاپ مقالات شما می باشد. در آن عضو شوید و از امکانات آن بهره برید.
Sparrho موتور های جستجوی علمی را در این سایت خواهید یافت.
SSRN مخزن آنلاین تحقیق علمی و مطالب مرتبط در علوم اجتماعی.
Stork بر اساس کلمات کلیدی خود کاربران ، نشریات و کمکهای جدید را به کاربران اطلاع می دهد.
Zotero به شما در جمع آوری ، سازماندهی ، استناد و به اشتراک گذاری منابع تحقیقاتی کمک می کند.
مدیریت مجموعه های بزرگی از داده ها و کد های برنامه نویسی در حال حاضر برای بیشتر محققان غیر قابل اجتناب است در این بخش با ابزارهایی آنلاین برای ذخیره سازی و به اشتراک گذاری داده ها و کد ها مواجه خواهیم داشت.
SlideShare انجمن برای به اشتراک گذاشتن ارائه ها و سایر محتوای حرفه ای
Socialsci محققان را کمک کند تا داده ها را برای نظرسنجی ها و آزمایش های خود کنند .
Zenodo یک پایگاه مهم برای دسترسی به مطالعات به صورت دسترسی تمام متن در رشته های مختلف می باشد. همچنین می توان تحقیقات خود را در این پایگاه با دیگران به اشتراک گذاشت.
در ارتباط با متخصصان و محققان ، مجموعه ای از ابزارهای آنلاین وجود دارد که به محققان کمک می کند تا به محقق دیگر کمک کنند و برای همکاری های جدید تخصص پیدا کنند. این وب سایت ها و ابزار های آنلاین برای ارتباط محققین مختلف دنیا با یکدیگر می باشند.
با کارشناسان و محققان ارتباط برقرار کنید
academia مکانی برای به اشتراک گذاشتن مطالعات و پیگیری تحقیقات و پژوهشگران دیگر.
Addgene از طریق این پلت فرم به اشتراک گذاری مطالعات و کتاب ها و جزوات خود با محققان دیگر و نیز ارتباط با محققین دیگر برای انجام پژوهش های مورد نظراتان می باشد.
Cureus دسترسی رایگان و آزاد به مجله پزشکی و مکانی برای پزشکان برای تهیه CV دیجیتال.
Direct2experts شبکه ای فدرال از تخصص تحقیقات زیست پزشکی.
Expertnet به شما در یافتن متخصصان در دانشگاه های فلوریدا کمک می کند.
GlobalEventList یک فهرست جامع از رویدادهای علمی در سراسر جهان.
innocentive به محققین کمک می کند تا به سرعت ایده های جدید تولید کند و مشکلات مهم را حل کند.
briefideas مکانی را برای توصیف ایده های کوتاه – در 200 کلمه یا کمتر – ، بایگانی شده ، جستجو و قابل استناد فراهم می کند. عزیزان آکادمی تحلیل آماری حتما به این سایت رفته و ایده های خود را بیان کنید.
LabRoots شبکه اجتماعی برای محققان. در شبکه در حوزه های مختلف علمی مورد نظر خود با محققین دنیا همکاری نمایید.
LabsExplorer جستجو برای شرکای تحقیق و توسعه ، دید خود را افزایش داده و سرمایه گذاری کنید.
LabWorm دارای بهترین ابزارهای علمی که مرتبا بروز رسانی می شود.
net بستر آنلاین برای شبکه سازی حرفه ای و به اشتراک گذاری دانش در علوم زیستی.
Linkedin یک شبکه اجتماعی حرفه ای برای همه از جمله محققین که امکانات بسیاری برای دیده شدن شما ارائه می کند.
Loop یک شبکه اجتماعی و تعاملی فوق العاده برای همکاری محققین و نیز اشتراک ایده ها و مطالعات خود با دیگران
Mendeley یک پلت فرم منحصر به فرد شامل شبکه های اجتماعی ، مدیر مرجع ، ابزارهای مطالعه مقاله.
MyScienceWork انتشار اطلاعات و دانش علمی به روشی آزاد و در دسترس تمام متن
nanoHUB بستر متمرکز برای تحقیق ، آموزش و همکاری فناوری نانو
OSF یک وبسایت جامع از اطلاعات، جزوات، مقالات، کتاب ها و سایر اسنادی که محققین سراسر جهان در آنجا به اشتراک گذاشته اند و حتما به محققین آکادمی تحلیل آماری آن را پیشنهاد می دهیم.
ResearchGate شبکه اجتماعی برای محققان که نیازی به توضیحی پیرامون اهمیت فوق العاده آن برای محققین ندارد.
SocialScienceSpace شبکه اجتماعی و فضایی برای کشف ، اشتراک و شکل دادن به موضوعاتی که دانشمندان اجتماعی و رفتاری با آن روبرو هستند
Trellis یک سکوی دیجیتالی که شما را به بقیه جامعه علمی وصل می کند
Wesharescience مکانی برای به اشتراک گذاری ، جستجو ، سازماندهی ویدئو های تحقیقاتی در رشته های تحقیقاتی مختلف
دسترسی به ایده های علمی جدید و آموزش های مختلف
AcademicJoyبه اشتراک گذاری ایده ها و داستانهای تحقیقاتی در زمینه تحقیق و نوآوری.
AcaWiki ویکیپدیای آکادمیک که می تواند برای عزیزان بسیار سودمند باشد.
Animate Science به دانشمندان کمک می کند تا با استفاده از رسانه بصری ، کار خود را توسط همسالان خود و عموم مردم مورد توجه قرار دهند.
analysisacademy مدرسه پژوهش کمی و کیفی و تنها محل برگزاری دوره های بین المللی روش پژوهش با نرم افزار های تخصصی و گواهی های بین المللی از انگلیس، اتریش و آمریکا
WebPlotDigitizer ابزاری مبتنی بر وب برای استخراج داده ها از ، تصاویر و نقشه ها
Wolfram Alpha ابزارهای مبتنی بر وب برای محاسبات علمی.
جمع آوری کمک های مالی / کمک مالی
محققین در نظر گیرند که بسیاری از سایت ها هستند که علاوه بر امکان همکاری با محققین دیگر جهان که موجب ایجاد فرصت های تحصیلی و پژوهشی بسیاری برای عزیزان می شود، می توان برای ایده ها و پروژه های خود بودجه و اسپانسر های آکادمیک جذب نمود.
Grant Forward موتور جستجو برای کمکهای مالی تحقیقاتی.
Instrumentl پایگاه داده و ابزار جستجوی اطلاعاتی که در مورد پروژه های تحقیقاتی خاص اطلاعات کسب می کند و سپس آنها را با بهترین کمک های مالی موجود در اختیار شما قرار می دهد.
Pivot COS پایگاه داده ای که شامل فرصت های بودجه از همه رشته ها می شود.
Publiconn شبکه اجتماعی برای سازمانهایی که از بودجه اهداکنندگان دولتی یا خصوصی استفاده می کنند و سازمانهایی که تأمین اعتبار می کنند.
در این بخش با ابزار ها و سایت های دیجیتال برای نگارش تحقیقات و سازماندهی منابع به صورت استاندارد آشنا می شویم.
مدیریت مراجع
CitationStyles در این پایگاه سبکهای استناد دهی در مقالات خود را پیدا و ویرایش کنید.
Citavi سایت نرم افزار قدرتمند مدیریت مراجع که به زودی نسخه حرفه ای آن را به صورت فول کرک برای شما روی سایت مدرسه پژوهش کمی و کیفی ایران analysisacademy.com قرار می دهیم.
Colwiz استناد و کتابشناسی ایجاد کنید و گروه های تحقیقاتی خود را بر روی فضای ابر ایجاد کنید تا پرونده ها و منابع را به اشتراک بگذارید.
EndNote ابزار نرم افزاری برای انتشار و مدیریت کتابشناسی ، استنادها و منابع
Mendeley یک پلت فرم منحصر به فرد شامل شبکه های اجتماعی ، مدیر مرجع ، ابزارهای مطالعه مقاله.
papers نرم افزاری قدرتمند که در آن روش کشف ، سازماندهی ، خواندن ، حاشیه نویسی ، اشتراک گذاری و استناد را به طرز چشمگیری بهبود می بخشد.
Zotero به شما در جمع آوری ، سازماندهی ، استناد و به اشتراک گذاری منابع تحقیقاتی کمک می کند
ابزار نوشتن مشارکتی
ASCIIdoctor مجموعه ای از ابزار پردازنده متن و انتشار متن برای تبدیل AsciiDoc به HTML5 ، DocBook و موارد دیگر.
Authorcafe بستر خدمات نویسندگی و نشر برای نوشتن مطالب علمی.
Authorea بستر نوشتن اسناد علمی ، دانشگاهی و فنی با همکاری.
ludwig با مقایسه کلمات خود با منابع معتبر مانند زمان نیویورک یا بی بی سی به شما در بهبود نوشتن انگلیسی کمک می کند.
Ref-n-wright افزونه ای مایکروسافت ورد که به شما در بهبود مهارت های نوشتن انگلیسی کمک می کند.
Writfull بازخورد در مورد نوشتار خود را با استفاده از داده های پایگاه داده Google Books ارائه می دهد.
سیستم Open Access یک الگوی جایگزین انتشار را ارائه می دهند و به هر کسی امکان می دهد تا آثار منتشر شده را به صورت رایگان دریافت کند. محققان همچنین می توانند با قرار دادن نسخه های اصلی مطالعات خود در این پایگاه ها ، میزان قرار گرفتن در معرض کار خود را به حداکثر برسانند همچنین این پایگاه ها ابزار هایی را در اختیار محقق برای هر چه بیشتر دیده شدن مقالات آن ها در هزاران سایت فراهم می سازد.
eLife دسترسی آزاد به امیدوار کننده ترین پیشرفت ها در علم.
GigaScience پایگاه دسترسی به داده های رایگان آنلاین
Limn پایگاه دسترسی آزاد و رایگان که به تشریح مشکلات عصر حاضر می پردازد.
PeerJ دسترسی آزاد به نسخه اولیه چاپ نشده و انتشار یافته تحقیقات علوم زیستی
Cureus دسترسی رایگان و آزاد به مجلات پزشکی و مکانی برای پزشکان برای تهیه CV دیجیتال.
ScienceOpen شبکه تحقیقاتی کاملاً در دسترس برای به اشتراک گذاری و ارزیابی اطلاعات علمی.
ArXiv نسخه های الکترونیکی تحقیقات و جزوات و کتاب ها در رشته های فیزیک ، ریاضیات ، علوم کامپیوتر ، زیست شناسی کمی ، امور مالی کمی و آمار.
biorXiv پایگاهی در حوزه زیست شناسی که در آن محققان مقالات خود را قبل از ارسال برای ژورنال ها به آنجا ارسال کرده و منتشر می شود و می توانند بازخورد و نظریات دیگر محققین را به عنوان بازخورد کار خود دریافت نمایند.
Peerage of Science پایگاهی که در آن محققان مقالات خود را قبل از ارسال برای ژورنال ها به آنجا ارسال کرده و منتشر می شود و می توانند بازخورد و نظریات دیگر محققین را به عنوان بازخورد کار خود دریافت نمایند.
PeerJ PrePrints پایگاهی در حوزه بیولوژی و پزشکی که در آن محققان مقالات خود را قبل از ارسال برای ژورنال ها به آنجا ارسال کرده و منتشر می شود و می توانند بازخورد و نظریات دیگر محققین را به عنوان بازخورد کار خود دریافت نمایند.
SlideShare انجمن برای به اشتراک گذاشتن ارائه های پاورپوینت و سایر محتوای حرفه ای.
Zenodo پایگاهی است که ، محققان را قادر می سازد تا هرگونه خروجی تحقیق خود را به اشتراک بگذارند.
پشتیبانی از نگارش و نوشتار مطالعات شما
Exec & Share کدهای برنامه نویسی و داده هایی را که پیوست تحقیقات خود قرار داده ایم ، آشکارا در این سایت به اشتراک بگذارید.
RunMyCode آشکارا کد و داده هایی را که پایه گذاری انتشارات تحقیق شما هستند به اشتراک بگذارید.
ORCID شناسه ثابت دیجیتال را فراهم می کند که شما را از هر محقق دیگر متمایز می کند. از طریق این سایت می توان برای مطالعات خود اسپانسر های مالی مناسب پیدا کرد.
در این بخش ابزار ها و وب سایت هایی ارائه شده است که به کمک آن ها می توان بررسی مجلات و ناشران و پیدا کردن ژورنال مناسب برای مقاله ای که آماده نموده اید را بیاموزید. بسیاری از عزیزان و محققین آکادمی تحلیل آماری ایران در این بخش مشکلات زیادی دارند که اینگونه برطرف خواهد شد.
Edanz راهنمای شخصی که ابزارها و خدماتی را که برای انتشار نیاز دارید توصیه می کند.
Editor lookup ابزار جستجو برای یافتن متخصصان علمی برای کارهای علمی مانند ویراستاران و داوران نسخه های علمی دستی.
Journalfinder elsevier سرویس Elsevier که به شما کمک می کند ژورنالی را پیدا کنید که بتواند برای چاپ مقاله علمی شما مناسب باشد.
journalguide راهننمایی بسیار کاربردی است برای اینکه بهترین ژورنال را برای تحقیقات خود پیدا کنید
journalreviewer کاربران اطلاعات مربوط به تجربیات خود را در مورد فرآیندهای بررسی و داوری مجلات دانشگاهی را در آن ارائه می دهند.
RoMEO درباره حق چاپ و چاپ و نشر و سیاست های ناشر اطلاعات کسب کنید.
SciRev تجربه خود را با روند بررسی علمی به اشتراک بگذارید و از دیگران بیاموزید که تصمیم بگیرند کجا نسخه های مقالات را ارسال کنید
ابزارهای جدید تغییرات گسترده ای در ارزیابی مطالعات ، چه از نظر ارزش علمی مقالات و چه از دستاوردهای کلی پژوهشگران.در اختیار گذارده است این ابزار ها مجموعه ای جدید است که نه تنها ارزش کار های شما را بر اساس ایمپکت فاکتور یا تعداد استنادات بررسی می کند بلکه ارزش و تأثیر کار شما را با روشهای دیگر که جدید می باشند نیز تحلیل می کند.
F1000 متخصصان برجسته زیست پزشکی به دانشمندان در کشف ، بحث و انتشار تحقیقات کمک می کنند.
is یک افزونه مفید برای مرور گر شما جهت یادداشت گذاری و هایلایت مطالب مهم علمی مورد استفاده در تحقیقات
journalreview ارزیابی و بررسی مقالات چاپ شده در ژورنال های پزشکی.
Labii مجموعه ای از برنامه های وب برای محققان ، از جمله یک برنامه آنلاین برای یافتن ، اظهار نظر ، رتبه بندی مقالات تحقیقاتی
Libre بستر بررسی مشارکتی ارزش تحقیقات (آزمایش بتا).
PubPeer جستجوی انتشارات و ارائه بازخورد از تحقیقات منتشر شده یخود را در این سایت انجام دهید.
Pubmed Commons نظرات و اطلاعات خود را در مورد انتشارات علمی را درون PubMed به اشتراک بگذارید.
Rubriq بررسی کننده ی مستقل مقالات شما از ژورنال ها و داورانی که کار خود را برای آن ها ارسال می کنیم. در واقع محققین می تواننند جهت بررسی کارهایشان و گرفتن نظرات تخصصی و علمی و نیز قرار گیری مطالعه خود در این فضای اشتراک آزاد مطالعه خود را در اینجا سابمیت نمایند.
ScienceOpen شبکه تحقیقاتی کاملاً در دسترس برای به اشتراک گذاری و ارزیابی اطلاعات علمی.
Winnower پلت فرم انتشار آنلاین مقالات علمی است. آن ها بیان می کنند که هدف ما انقلابی کردن علم از طریق شکستن موانع ارتباطات علمی از طریق انتشار مقرون به صرفه و شفاف برای محققان است. .
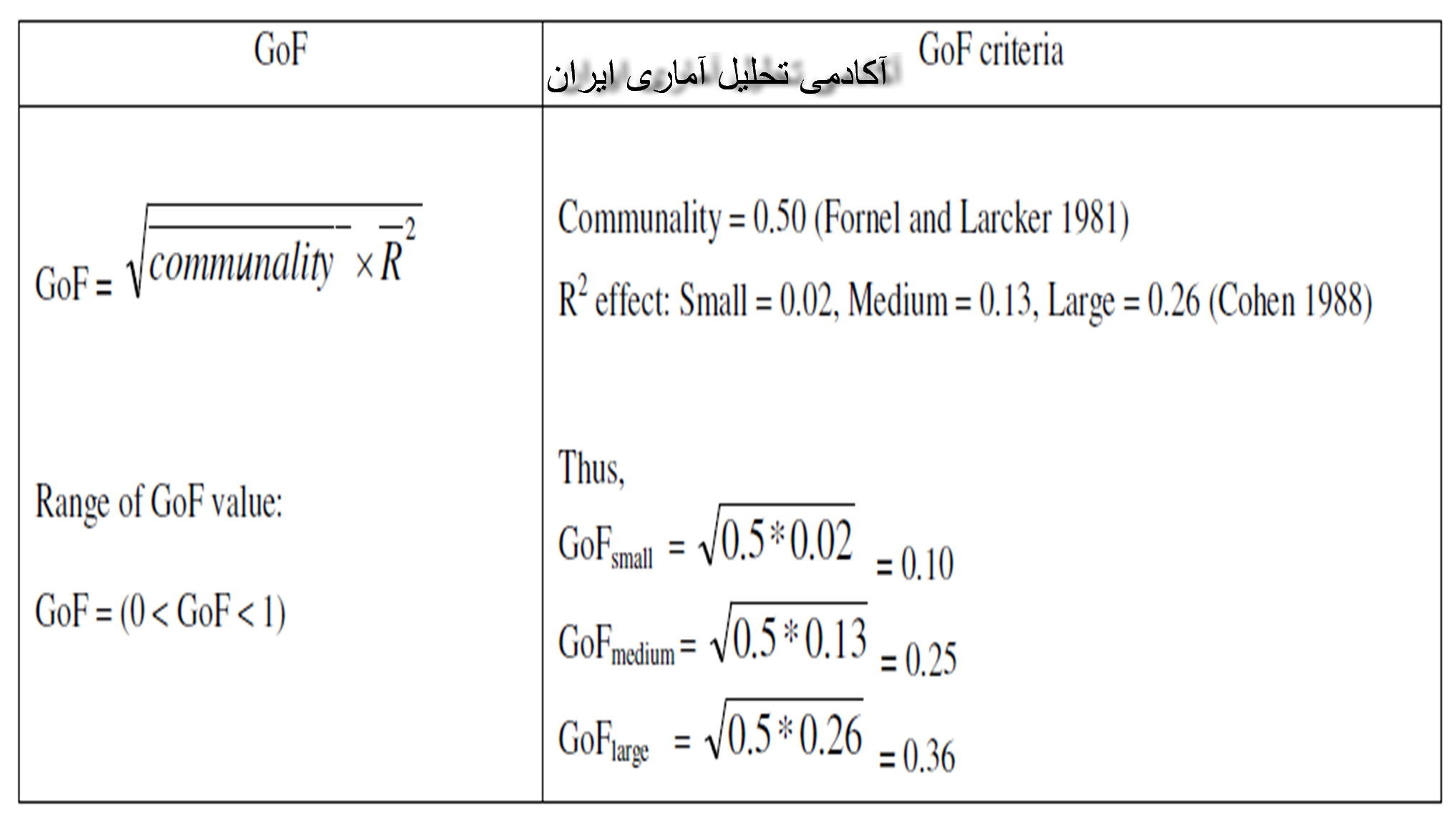
متاسفانه مدل هایی که با رویکرد واریانس محور از طریق نرم افزار های خانواده PLS مورد بررسی قرار می گیرند فاقد شاخصی کلی برای نگاه به مدل به صورت یکجا هستند. یعنی شاخصی برای سنجش کل مدل شبیه به رویکرد کواریانس محور وجود ندارد. اما در تحقیقات مختلف در این حوزه پیشنهاد شد که از شاخصی به نام GOF می توان به جای شاخص های برازشی که در رویکرد های کواریانس محور وجود دارد، استفاده نمود. این شاخص هر دو مدل ساختاری و اندازه گیری را به صورت یک جا در نظر گرفته و کیفیت آن ها را مورد آزمون قرار می دهد.(محسن مرادی، 1393)
تحلیل عاملی یا آنالیز فاکتور یا Factor Analysis یکی از روشهای آماری چند متغیره است که بین مجموعه فراوانی از متغیرها که به ظاهر بی ارتباط هستند ، رابطه خاصی را تحت یک مدل فرضی برقرار می کند.
در تحلیل عاملی تعداد زیادی از متغیرها برحسب تعداد کمی از ابعاد یا سازه ها بیان می شود ، این سازه ، فاکتور یا عامل نامیده می شود.
تحلیل عاملىFactor Analysis
تحلیل عاملی چیست ؟
تحلیل عاملی یا آنالیز فاکتور یا Factor Analysis یکی از روشهای آماری چند متغیره است که بین مجموعه فراوانی از متغیرها که به ظاهر بی ارتباط هستند ، رابطه خاصی را تحت یک مدل فرضی برقرار می کند.
در تحلیل عاملی تعداد زیادی از متغیرها برحسب تعداد کمی از ابعاد یا سازه ها بیان می شود ، این سازه ، فاکتور یا عامل نامیده می شود.
منطق تحلیل عاملى
تحلیل عاملى براى ایجاد ارتباط بین متغیرهاى مشاهد شده و تعداد کمترى از متغیرهاى مفهومى زیرین طراحى شده است . تحلیل عاملى ، سنجه هاى مشاهده شده را برحسب عوامل مشترک ( مشاهده نشده ) به اضافه واریانس یکتا نشان مى دهد . روابط بین عوامل مشاهده نشده و سنجه هاى مشاهد شده تحت عنوان وزن ( براى مثال وزن هاى رگرسیونى ) که عامل ها را به سنجه ها ارتباط مى دهند ، تعریف مى شوند .
تعریفی دقیق از تحلیل عاملی
آنالیز فاکتور ، چرخه اى را براى حرکت از مدل مسیر مبتنى بر ” سنجه واحد براى هر سازه ” بر چند سنجه براى هر سازه یا مدل مسیر چند معرفه فراهم مى سازد . از این طریق مى توان متغیرهاى نظرى مورد توجه را در تحلیل مسیر آزمود . در این حالت متغیرها به عنوان عامل محسوب مى شوند و براى هر سازه چند سنجه وجود دارد که این عامل سبب بهبود سنجش سازه ها مى شود .
نکتهتحلیل آماری
با گسترش تحلیل مسیر ، با پیوند منطق تحلیل عاملى ، مدل سازى مسیر ، دیگر نمى توان مدل ها را از طریق تکنیک هاى رگرسیونى حداقل مربعات معمولى ( OLS ) حل نمود .
تحلیل عاملی در برابر تحلیل رگرسیونی
تحلیل عاملی
تحلیل رگرسیونى ما را به یک سنجه واحد که فکر مى کنیم بر متغیر مفهومى مورد نظر نزدیک است محدود مى کند ، در صورت داشتن سنجه هاى مختلف ، بهترین گزینه ما براى تحلیل مسیر معمولاً ترکیب گزینه هاى اندازه گیرى خواهد بود . در اصل آن سنجه باید نشانگر بهترین روایى حتى در صورتى که در برگیرنده خطاهایى از متغیرهاى جمع شده هستند ، باشد .
در مقابل ، در رویکرد تحلیل عاملى بیش از اینکه بر انتخاب بهترین سنجه فکر کنیم ، باید سنجه هاى مختلفى براى ارزیابى متغیرها انتخاب کنیم . سازه عملکرد ( عامل ) به واسطه نقاط مشترک سنجه ها تعریف مى شود . عامل عملکرد ، عاملى است که با دیگر متغیرهاى نظرى روابط درونى دارد و هر کدام از آنها عامل هایى هستند که از طریق چند سنجه تعریف مى شوند . در مدل مسیرى که خطوط یک جهته عامل ها را بر همدیگر وصل مى کند ، همبستگى ها ( کوواریانس ها ) میان عامل ها به ضرایب مسیر تغییر مى یابد ، به همان صورتى که تحلیل رگرسیونى همبستگى ها یا کوواریانس ها را به ضرایب مسیر تغییر مى دهد .
تحلیل عاملی شکل تغییر یافته رگرسیون
براى خوانندگانى که با تحلیل مسیر آشنا نیستند ؛ مى توان گفت تحلیل عاملى خیلى شبیه رگرسیون است . از آنجایى که آنالیز فاکتور نیز همانند رگرسیون جزء مدل هاى خطى کلى محسوب مى شود ، آن را مى توان به عنوان شکل تغییر یافته رگرسیونى دید .
برجسته ترین تفاوت این دو رویکرد در اینست که در تحلیل عاملى همه متغیرهاى مدل رگرسیونى سنجش نمى شوند . همچنین در تحلیل عاملى ماتریسى که مورد تحلیل قرار مى گیرد ، تحلیل همبستگى است و بنابراین راه حل مشابه رگرسیونى باید بر ضرایب استاندارد شده ( بتا ) توجه داشته باشد .
معادله ى رگرسیونى در شکل ماتریسى Y=BX+E است ، در صورتى که معادله اصلى تحلیل عاملى Y=Pf+U مى باشد . در معادله آخر ، فقط Y ها به طور واقعى سنجیده مى شوند Y ها بر حسب بردار عامل هاى f که بیانگر عامل هاى سنجش نشده مى باشد ، ماتریس وزن ها یا P که بیانگر ماتریس ضرایبى است که عامل ها را بر سنجه هاى مشاهده شده Y وصل مى کنند و بردار باقیمانده ها یعنى U ، تعریف مى شوند .
عناصر P در اصل ضرایب رگرسیونى هستند ؛ اما در واژگان تحلیل عاملى به عنوان عناصر ماتریس الگوى عاملى تعریف مى شوند . عناصر U یعنى باقیمانده هایى که بعد از تجزیه عامل مشترک وجود دارند ، یکتایى در آنالیز فاکتور نامیده مى شوند . معادله تحلیل عاملى از نظر شکل ، معادل تحلیل رگرسیونى است
راه کارهای تحلیل عاملی
تحلیل عاملی
آنالیز فاکتور همانند دیگر روشهای آماری راهی برای رسیدن پژوهشگر به اهداف خود می باشد. چنانچه هدف تحقیق کاهش و خلاصه کردن داده ها باشد ، تحلیل عاملی روش مناسبی برای این منظور خواهد بود. در این راستا پژوهشگر برای رسیدن به اهداف خود باید به این سوالات پاسخ دهد :
کدام متغیر باید در تحلیل وارد شود ؟
چه تعداد متغیر را باید در تحلیل وارد نمود ؟
متغیرها چگونه سنجیده می شوند ؟
آیا حجم نمونه برای تحلیل عاملی کافی است ؟
کارکرد اصلی تحلیل عاملی
هنگامى که محققین سنجه ها را در مورد مجموعه اى از ابعاد زیرین اولیه گردآورى مى کنند ، تحلیل عاملى بیشتر براى تأیید آزمون مدل بکار مى رود تا کشف مدل . هر چند که در عمل ، تعیین ماهیت متغیرهاى سنجش نشده همواره به وضوح مشخص نیست تا جایى که تکنیک هاى تحلیل عاملى به عنوان تکنیک هاى اکتشافى بکار گرفته شده اند . بکار بردن تکنیک آنالیز فاکتور براى مشخص سازى ابعاد سنجه هایى که به طور غیر نظرى در هم جمع یا با هم ترکیب شده اند ، مى تواند تفسیر عامل هاى سنجش نشده را دشوار سازد .
نکات مهم در تحلیل عاملی
طبیعی است که در روش تحلیل عاملی باید دقت زیادی کرد، اگر ناآگاهانه از آن استفاده شود ممکن است بسادگی نتایج ضد و نقیضی به بار آورد.
به طور کلی این تحلیل برای متغیرهای رتبه ای زیاد مناسب نیست.
تحلیل عاملی برای داده های انبوه بوده و برای متغیرهای فاصله ای بیشتر مناسب است.
نکته ی دیگر مناسب بودن داده ها برای تحلیل عاملی است ، مثل کافی بودن حجم نمونه
چهار وظیفه مهم تحلیل عاملی
به طور مشخص تحلیل عاملی چهار وظیف زیر را می تواند انجام دهد:
تشخیص یک مجمعه از ابعاد مفهومی که معمولاً از دید پژوهشگر پنهان است ( و یا به سهولت قابل مشاهده نیستند)
ارائه روش ترکیب و خلاصه کردن تعداد زیادی از افراد جامعه (یا واحدهای تحلیل ) به داخل تعدادی گروه کاملاً متمایز از بین یک جامعه بزرگ
تشخیص متغیرهای مناسب برای تحلیل های بعدی (مثلاً استفاده از آنها در تحلیل رگرسیون و تحلیل همبستگی )
ایجاد یک مجموعه از متغیرهای کاملاً جدید که تعداد آنها نسبت به متغیرهای مورد مشاهده خیلی کمتر است و قرار دادن آن به جای مجموعه متغیرهای مورد مشاهده در تحلیل های بعدی
هدف اغلب تحلیل های عاملی ساده کردن ماتریس همبستگی است، به گونه ای که بتوان آنها را در اغلب عوامل اصلی توصیف کرد؛ به عبارتی بتوان آنها را بر حسب تعدا کمی از عامل های زیر بنایی توضیح داد تا در نتیجه به روابط بین متغیرها پی برد. در واقع، هدف تحلیل عاملی ساده سازی مجموعه ی پیچیده ای از داده ها می باشد. زمانی که اسپرمن در سال ۱۹۰۴ این تکنیک را معرفی کرد، از ساده ترین روشهای محاسباتی استفاده شده بود. امّا با گذشته سالها و با کامل تر شدن رایانه ها، روشهای رایانه ای بسیاری به وجود آمد. در حال حاضر روشهای محاسباتی متفاوتی از تحلیل عاملی وجود دارد، که البته بعضی از آنها از لحاظ فنی نامناسب هستند و نتایج گمراه کننده است.
از تحلیل عاملی می توان بر روابط اساسی بین مقولات یا متغیرها پی برد. تحلیل عاملی مشخص می کند که در بین داده ها چه چیز عامل نامیده می شود، البته منظور از عامل همان ابعاد یا ساختار پنهانی است که محقق در پی کشف و یا آزمون آنهاست. این عامل های سازنده فرضی هستند که غالباً می توانند بین تبین داده ها مورد استفاده قرار گیرند؛ به عبارتی تحلیل عاملی، واریانس موجود در متغیرهای مختلف را بر اساس معدودی از عوامل نشان می دهد.
تحلیل عاملی گویای این سؤال است که عوامل متعدد، چگونه می توانند در یک مجموعه از داده ها قرار گیرند با آن سؤال (گویه) مرتبط شوند. در واقع، تجزیه و تحلیل عاملی روشی برای تعیین تعداد و ماهیت متغیرهای واقعی در میان تعداد زیادی از مقیاس ها می باشد. تحلیل عاملی تعداد متغیرهایی را که می باید پژوهشگر به کار گیرد کاهش می دهد؛ به سخنی دیگر یکی از اهداف اصلی تکنیک تحلیل عاملی، کاهش ابعاد داده هاست، یعنی کاهش دهنده ی تعداد متغیرها به تعداد کمتری از متغیرها یا همان عوامل پنهان است. بنابراین، هدف اصلی تکنیک های تحلیل عاملی، یافتن روش مختصر و مفید کردن اطلاعات بدست آمده از تعداد زیادی متغیر مورد مشاهده و تبدیل آنها به یک مجموعه کوچکتر از ابعاد ترکیبی جدید (عامل ها) با حداقل از دست دادن اطلاعات است. در این روش ابعاد یا سازه های اساسی که فرض می شود از لحاظ مفهومی مبنای مشترک متغیرهای مورد مشاهده هستند، مورد جستجو قرار می گیرد.
وظایف تحلیل عاملی
به طور مشخص تحلیل عاملی چهار وظیفه ی ذیل را می تواند انجام دهد:
تشخیص یک مجموعه از ابعاد مفهومی که معمولاً از دید پژوهشگر پنهان هستند ( و یا به سهولت قابل مشاهده نیستند) در بین تعداد زیادی از متغیرها. یعنی هدف آن کشف یگانگی ها در بین متغیرهای متعدد است. در واقع، در روش تحلیل عاملی می توان سازه هایی را که قبلاً نامعلوم بودند آشکار ساخت.
ارائه روش ترکیب و خلاصه کردن تعداد زیادی از افراد جامعه (یا واحدهای تحلیل) به داخل تعدادی گروه کاملاً متمایز از بین یک جامعه ی بزرگ؛ یعنی هدف آن تشخیص یگانگی در بین افراد جامعه (یا واحدهای تحلیل) است.
تشخیص متغیرهای مناسب برای تحلیل های بعدی ( مثلاً استفاده از آنها در تحلیل رگرسیون و تحلیل همبستگی) از بین تعداد زیادی متغیر مشاهده، در مورد چگونگی تشخیص انتخاب متغیرهای مناسب است.
ایجاد یک مجموعه از متغیرهای کاملاً جدید که تعداد آنها نسبت به متغیرهای مورد مشاهده خیلی کمتر است و قرار دادن آن به جای مجموعه متغیرهای مورد مشاهده در تحلیل های بعدی (مثل استفاده از آنها در تحلیل رگرسیون و یا تحلیل همبستگی)، در مورد چگونگی استفاده از این متغیرهای جدید که اصطلاحاً به آنها نمره ی عاملی گفته می شود، توضیح داده می شود.