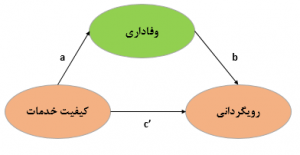
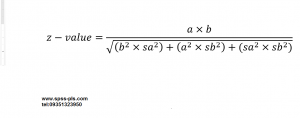وقتی محققین عزیز مدل سازی معادلات ساختاری می آموزند بعد از جمع آوری داده های پژوهش خویش به سراغ اجرای مدل در نرم افزار های مختلف مدل سازی معادلات ساختاری می روند و مدل خویش را بر اساس متغیر ها و شاخص های مختلف پژوهش خود نام گذاری می کنند. این عزیزان نباید فراموش کنند که همانطور که در دوره های مختلف آموزشی به آن ها توصیه شده، باید مقالات مختلفی که در کلاس ها به آن ها ارائه شده را مطالعه نمایند. نکته اینجاست که برای مطالعه این کتاب ها و مقالات باید نامگذاری یونانی پارامتر های یک مدل را بدانند زیرا تمامی کتاب ها و مقالات مرجع این حوزه بر اساس همین نامگذاری ها شروع به بحث پیرامون موارد مختلف کرده اند. در این مقاله تلاش شده نامگذاری صحیح تمامی پارامتر های مدل سازی معادلات ساختاری را با روش علمی بیان نماییم. البته علائم یونانی همه در شکل این مقاله مشخص هستند.
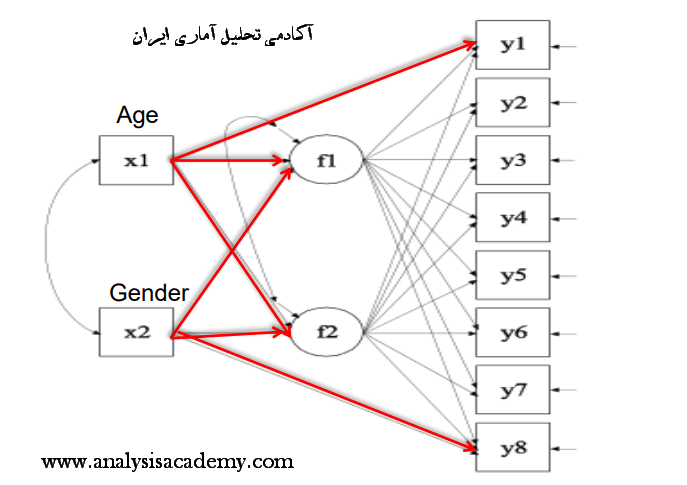
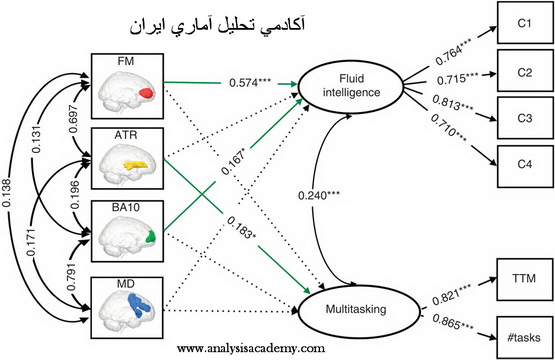
- متغیر مکنون برونزا: متغیر های مکنون برونزا ، متغیر های مکنونی هستند که در نقش علت( متغیر مستقل) بر متغیر های دیگر اثر می گذارند. در مدل سازی معادلات ساختاری آن ها را کسای(xi) یا ξ نامگذاری می کنند.
- متغیر مکنون درونزا: متغیر های مکنونی هستند که تحت اثر متغیر های مکنون برونزا می باشند. در مدل سازی معادلات ساختاری آن ها را اتا(eta) یا η نامگذاری می کنند.
- متغیر های آشکار اندازه گیری کننده متغیر های مکنون برونزا: این متغیر های آشکار در مدل به متغیر های مکنون برونزا متصل هستند. در مدل سازی معادلات ساختاری آن ها را ایکس یا X نامگذاری می کنند.
- متغیر های آشکار اندازه گیری کننده متغیر های مکنون درونزا: این متغیر های آشکار در مدل به متغیر های مکنون درونزا متصل هستند. در مدل سازی معادلات ساختاری آن ها را وای یا Y نامگذاری می کنند.
- خطاهای اندازه گیری شاخص های متغیر های مکنون برونزا: هر یک از سوالات متصل به متغیر های مکنون برونزا دارای خطای اندازه گیری هستند که به صورت عام فارغ از برونزا و یا درونزا بودن متغیر مکنون مربوطه در تحقیقات مختلف آن ها را با e نشان می دهند اما به صورت علمی در مدل سازی معادلات ساختاری آن ها را دلتا(delta) یا δ نامگذاری می کنند.
- خطاهای اندازه گیری شاخص های متغیر های مکنون درونزا: هر یک از سوالات متصل به متغیر های مکنون درونزا دارای خطای اندازه گیری هستند که به صورت عام فارغ از برونزا و یا درونزا بودن متغیر مکنون مربوطه در تحقیقات مختلف آن ها را با e نشان می دهند اما به صورت علمی در مدل سازی معادلات ساختاری آن ها را اپسیلون (xi) یا ε نامگذاری می کنند.
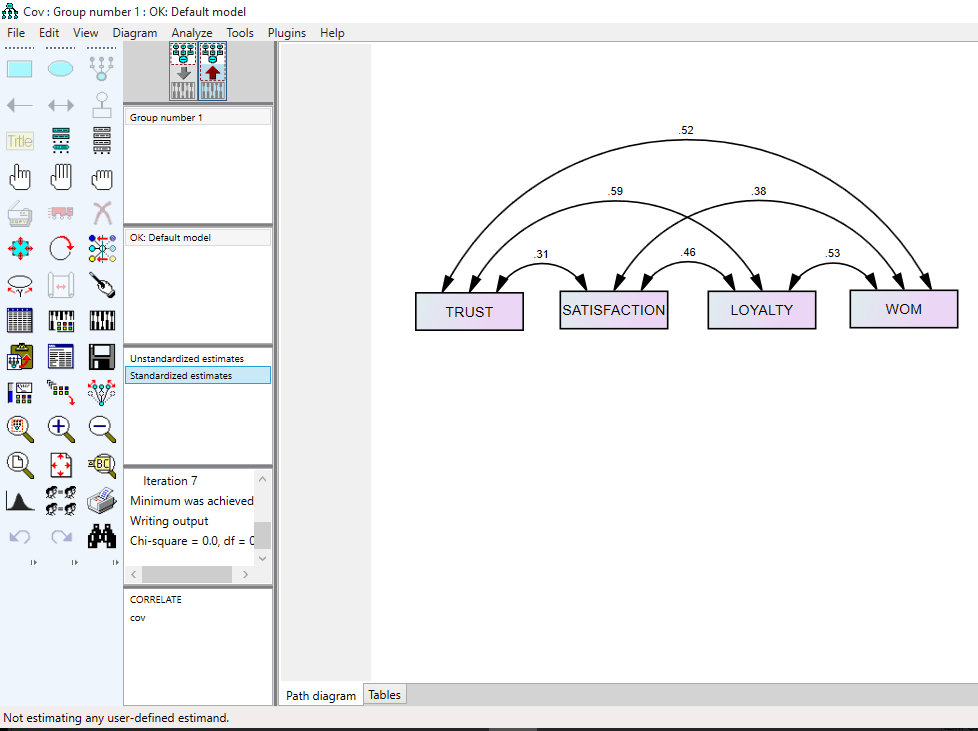
- بار عاملی: یک ضریب همبستگی بین متغیر های مکنون و متغیر های آشکار است که به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را لاندا(lambda) یا λ نامگذاری می کنند.
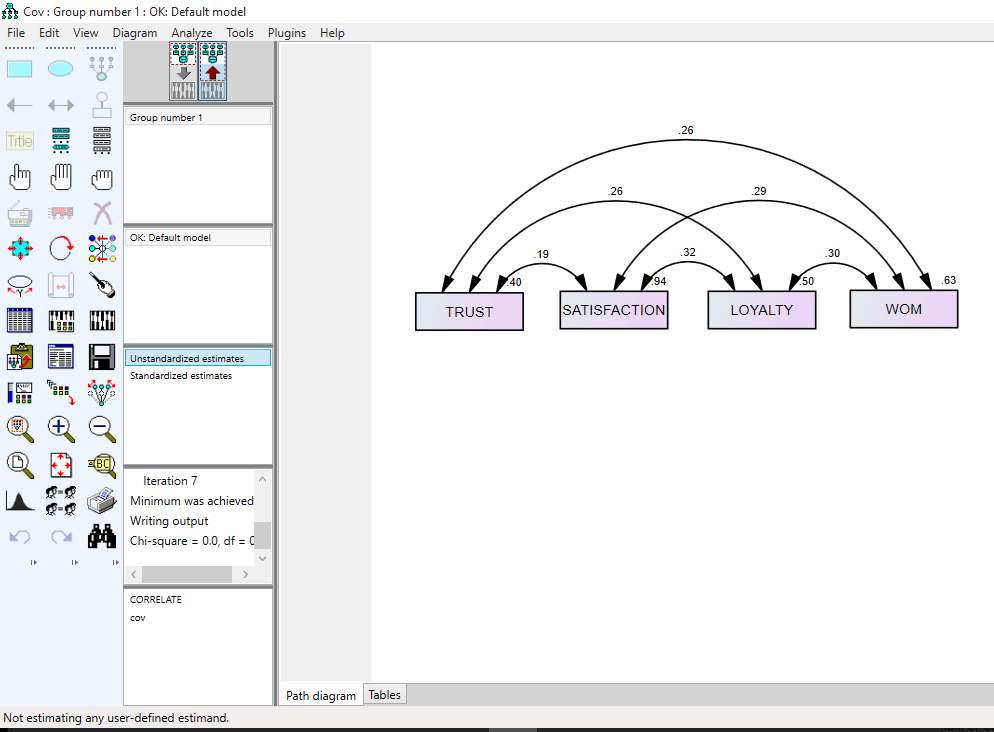
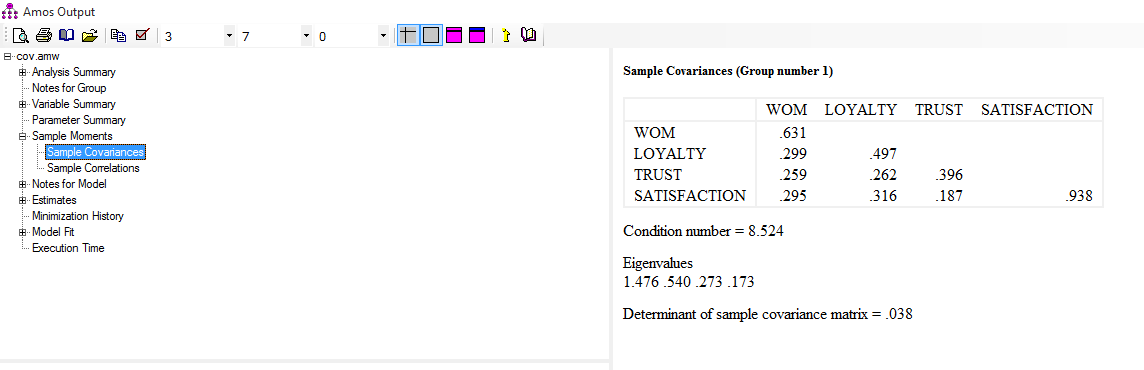
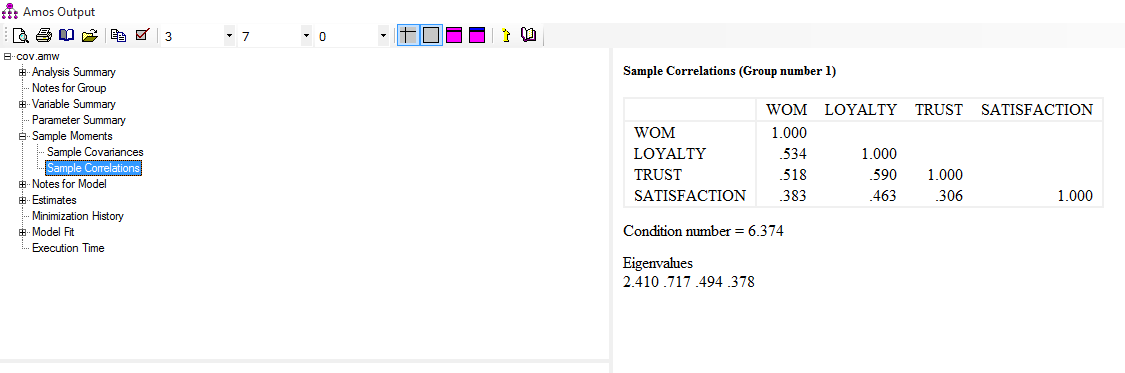
- کواریانس ها: همواره بین متغیر های برونزا در مدل به جهت اینکه این متغیر ها نباید با هم همخطی داشته باشند کواریانس وجود دارد. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را فی(phi) یا φ نامگذاری می کنند.
- ضرایب مسیر از متغیر های مکنون برونزا به درونزا: معمولا در حالت معمول بین این ضرایب مسیر با ضرایب مسیری که از یک متغیر درونزا به متغیر درونزای دیگر است تفاوتی قائل نمی شوند. اما در کتاب های مرجع معادلات ساختاری این دو نوع ضریب مسیر متفاوت نامگذاری می شوند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را گاما(Gamma) یا γ نامگذاری می کنند.
- ضرایب مسیر از متغیر های مکنون درونزا به درونزا: معمولا در حالت معمول بین این ضرایب مسیر با ضرایب مسیری که از یک متغیر برونزا به متغیر درونزای دیگر است تفاوتی قائل نمی شوند. اما در کتاب های مرجع معادلات ساختاری این دو نوع ضریب مسیر متفاوت نامگذاری می شوند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را بتا(Beta) یا β نامگذاری می کنند.
- خطای باقی مانده: در نهایت باید گفت که هدف از مدل سازی معادلات ساختاری پیش بینی رفتار یا واریانس متغیر های درونزا در مدل است. میزان این پیش بینی را شاخص R2 مشخص می کند و میزان عدم تبیین واریانس این متغیر ها را خطای باقی مانده مشخص می کند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را زتا(Zeta) یا ζ نامگذاری می کنند.
البته در پایان خاطر نشان می شوم که نامگذاری به صورت های ساده دیگر یا هر نام گذاری دیگری در محاسبات تفاوتی ایجاد نمی کند اما اگر شما عزیزان قصد مطالعه کتاب ها و مقالات مرجع را داشته باشید باید این نامگذاری علمی را بدانید.
محسن مرادی