محاسبه گر حجم نمونه برای مدل سازی معادلات ساختاری (SEM)
همانطور که بارها در کارگاه های آماری بیان شد، استفاده از آمار استنباطی در جهت تعمیم الگو های کشف شده در در نمونه آماری به جامعه آماری، یک اصل غیر قابل تغییر است. آن اصل معرف بودن نمونه و اینکه نمونه نماینده ای تمام نما از جامعه باشد. ام چه نمونه ای معرف جامعه است و چگونه می توان مطمئن بود که مشت نمونه خروار است؟
- روش نمونه گیری باید احتمالی باشد ( یعنی محقق باید در نمونه گیری خود یکی از رویکرد های تصادفی ساده، سیستماتیک، خوشه ای و یا طبقه ای را استفاده کرده باشد)
- واحد تحلیل در نمونه گیری بر اساس مسئله پژوهش و جامعه آماری مورد نظر مشخص شده باشد.
- و مهمترین بخش حجم نمونه ای مناسب بر اساس روش ها و فرمول های آماری متناسب معین گشته باشد تا بتوان تعمیم پذیری و دقت نتایج را ادعا نمود.(مرادی و میر الماسی، 1396)
متاسفانه همانطور که در دوره های قبلی آماری به دانشجویان گزارش داده شد نزدیک به 98 درصد مطالعات و مستندات علمی در ایران در نمونه ای که شامل 3200 رساله و 1100 مقاله در رشته ها و مقاطع مختلف تحصیلات تکمیلی بررسی شده است، این ایراد فاحش یعنی استفاده از فرمولی مناسب در معیین نمودن حجم نمونه را با خود یدک می کشند که این امر ضربه سنگینی به اعتبار مطالعات کمی کشورمان زده است. در واقع دو روش استفاده از فرمول تعیین حجم نمونه کوکران و یا استفاده از جدول کرچسی و مورگان و یا نظر اساتید باعث این مشکل بسیار بزرگ و بسیار تلخ در تحقیقات کشورمان است. این فرمول ها تنها برای چند آزمون اولیه مقایسه میانگین مثل تی تک نمونه ای و یا دو نمونه مستقل یا دو نمونه وابسته آن هم بصورتی بسیار محدود قابل استفاده است و استفاده از این روش ها در اکثریت آزمون ها اعم از آزمون ها پارامتریک و ناپارامتریک رابطه و علی و تفاوتی کاملا نادرست و غیر منطبق با اصول علمی آماری و روش پژوهش است. در سه سال اخیر هم اکثر دانشجویان آکادمی تحلیل آماری ایران که با روش های مدرن تحقیق آشنا شده و مقالات خود را در ژورنال های معتبر دنیا به چاپ رسانیدند، جملگی یک اصلاحیه از طرف داوران به کار آن ها قبل از پذیرش اعمال می شد و این اصلاحیه چیزی نیست جز اینکه به عنوان مثال در این آزمون رگرسیون، رگرسیون لجستیک، همستگی اسپرمن، پیرسون، یو من وایت نی و …..ده ها ازمون دیگر نباید از این فرمول ها و روش های بسیار ضعیف و قدیمی استفاده می شده است. بنابراین در چرخش دوره های آکادمی تحلیل آماری دوره های دو روزه حجم نمونه با نرم افزار های پیشرفته قرار داده شده است تا محققین در قالب متودی علمی روش نمونه گیری و حجم نمونه خود را مشخص و در مقالات و رساله خود گزارش نمایند.یکی از این دوره دوره ی نرم افزار SAMPLE POWER بوده است که این نرم افزار با قدرت نگارش سناریو های مختلف برای حجم نمونه تحقیق محقق را در انتخاب بهترین سناریو برای حجم نمونه آزمون پژوهشش یاری می رساند. اما از آن جا که این نرم افزار تخصصی که به ظاهر ساده اما دارای نکات بسیار زیادی در تعیین حجم نمونه است تقریبا یک روز 9 ساعته از کلاس به بیان روش تحقیق متناسب برای تعیین حجم نمونه و مفاهیم این حوزه و ارتباط این مفاهیم با هم گذشت. و مفاهیمی چون توان آژمون، اندازه اثر، درجه بندی مقیاس ها، عدم ارتباط حجم نمونه به حجم جامعه، انواع خطا، تعمیم پذیری و دقت نتایج و ….به صورت تفصیلی در آن مورد ارزیابی و بحث واقع شد. این نرم افزار و نرم افزار های مشابه برای نزدیک به 60 آزمون آماری مختلف با حالت های مختلفشان تعیین حجم نمونه می کنند. اما یکی از آزمون های آماری که برای تعیین حجم نمونه در درون این نرم افزار ها فضایی مناسب وجود ندارد، مدل سازی معادلات ساختاری کواریانس محور است. یعنی محقق زمانی که برای آزمون فرضیات خود قصد استفاده از نرم افزار های ایموس ، لیزرل، MPLUS و …. دارد باید حداقل حجم نمونه خود را با یک محاسبه گر مبتنی بر فرمولی مدرن مشخص نماید. روش های مختلفی برای این کار وجود دارد که در دوره ها بیان شده است. مثلا روش مبتنی بر Chi square و یا RMSEA .
اما در محاسبه گر زیر محققین به سادگی می توانند به حداقلی از حجم نمونه برای مدل سازی معادلات ساختاری دست یابند و دیگر به اشتباه از فرمول کوکران و یا روشهای سرانگشتی مثل ضرب عدد ده در سوالات یا عدد 50 در متغیر ها که صرفا شرط استفاده از این نرم افزارها است و نه روش تعیین نمونه، بهره گیرند(مرادی و میر الماسی، 1396)
برای تعیین حجم نمونه از اینجا وارد صفحه محاسبه گر حجم نمونه می شوید. سپس به دقت اعدادی که بیان می شود را طبق نکاتی که گفته می شود وارد می کنید.
- در قسمت Anticipated effect size که باید اندازه اثر مورد نظر برای آزمون مدل سازی معادلات ساختاری را وارد نمایید از قانون سه مقدار Chin در سال 1998 برای مقادیر R2 استفاده می کنید. سه مقدار چین شامل 0.19 و 0.33 و 0.67 است که محقق باید اندازه اثر 0.19 را جهت تشخیص آزمون برای این اندازه اثر وارد نماید.
- در گام دوم توان آزمون Desired statistical power level یا همان عکس خطای نوع دوم را باید وارد نمود که در عرف مطالعات، بخوصوص مطالعات علوم انسانی و اجتماعی این مقدار بین 80 تا 90 درصد انتخاب می شود و حداقل آزمون باید توانی برابر با 80 درصد داشته باشد.
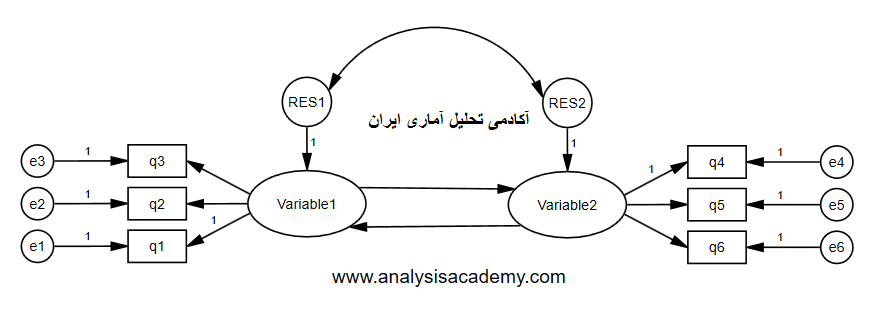
- در قسمت سوم تعداد متغیر های مکنون مدل پژوهش Number of latent variables اعم از برونزا و درونزا را وارد می کنیم که در مثال کلاس ما 5 متغیر مکنون که هر یک تویسط آیتم هایی اندازه گیری می شد داشتیم. اما هر کس بر اساس مدل خود عمل کند و تعدا متغیر های مکنون خود را در آن وارد نماید.
- در گام چهارم تعداد متغیر های آشکار یا همان سوالات پرسش نامه یعنی Number of observed variables را وارد نمایید که در مثال ما 28 متغیر آشکار یا مشاهده پذیر وجود دارد.
- در نهایت هم در گام آخر میزان خطای نوع اول را جهت دستیابی به بازه اطمینان 95 یا 99 درصد را وارد نمایید یعنی بجای Probability level مقادیر 0.05 و یا 0.01 را وارد نمایید. البته بهتر است که هر دو در دو سناریو مختلف وارد شوند سپس بر اساس نوع مسئله، توان محقق، بودجه محقق و غیره یکی از حجم نمونه های تعیین شده انتخاب گردد. سپس آیکون Calculate زده می شود. عدد اول ظاهر شده حجم نمونه علمی شما برای تحقیق پیش رو است.
تعیین حجم نمونه از اینجا
منبع: آکادمی تحلیل آماری ایران