

نرم افزار اسمارت پی ال اس (pls) چه کاربردی دارد؟
<p dir="RTL" style="text-align:justify">اهمیت روز افزون تجزیه و تحلیل داده ها در تحقیقات علمی، باعث توجه هر چه بیشتر جامعه علمی به این مقوله شده است. همان گونه که یک پژوهش علمی بدون مروری بر ادبیات موضوع و کنکاش در نظریه ها، ناقص میماند، اضافه نمودن تحقیق میدانی به تئوری های مطالعه شده جلوه ی دیگری به پژوهش داده و اعتبار آن را دوصد چندان می کند. در این راستا،داده هایی که محقق از اعضای نمونه آماری تحقیق خود جمع آوری می نماید، احتیاج به تجزیه و تحلیل دارند تا تفسیر یافته ها و تعمیم نتایج میسر گردد.</p>< p dir="RTL" style="text-align:justify">در مطالعات حوزه ی علوم انسانی و اجتماعی، تجزیه و تحلیل داده های پژوهش طبق فرآیندی با قالب کلی مشخص و یکسان صورت می پذیرد که مرتبط با آن روش تحلیل آماری متعددی تا به حال معرفی شده است. در این میان، مدل سازی معادلات ساختاری (SEM) که در اواخر دهه شصت میلادی معرفی شد، ابزاری در دست محققین جهت بررسی ارتباط میان چندین متغیر در یک مدل را فراهم می ساخت. قدرت این تکنیک در توسعه نظریه ها باعث کاربرد وسیع آن در علوم مختلف از قبیل بازاریابی، مدیریت منابع انسانی، مدیریت استراتژیک و سیستم اطلاعاتی شده است. یکی از مهمترین دلایل استفاده زیاد پژوهشگران از SEM، قابلیت آزمودن تئوری ها در قالب معادلات میان متغیرهاست. دلیل دیگر لحاظ نمودن خطای اندازه گیری توسط این روش است که به محقق اجازه می دهد تا تجزیه و تحلیل داده های خود را با احتساب خطای اندازه گیری گزارش دهد.</p>< p dir="RTL" style="text-align:justify">مدل سازی معادلات ساختاری تا این زمان، با دو نسل روش های تجزیه و تحلیل داده ها معرفی شده است. نسل اول روش های مدل سازی معادلات ساختاری روش های کوواریانس محور هستند که هدف اصلی این روش ها تایید مدل بوده و برای کار به نمونه هایی با حجم بالا نیاز دارند. نرم افزارهای LISREL، AMOS، EQS و MPLUS چهار عدد از پرکاربردترین نرم افزارهای این نسل هستند. چند سال پس از معرفی روش کوواریانس محور، به دلیل نقاط ضعفی که در این روش وجود داشت، نسل دوم روش های معادلات ساختاری که مولفه محور بودند، معرفی شدند. روش های مولفه محور که بعدا به روش حداقل مربعات جزئی تغییر نام دادند، برای تحلیل داده ها روش های متفاوتی نسبت به نسل اول ارائه دادند.</p>< p dir="RTL" style="text-align:justify">پس از معرفی روش حداقل مربعات جزئی، این روش از علاقه مندان بسیاری برخوردار شد و پژوهشگران متعددی تمایل به استفاده از این روش پیدا کردند. مهمترین نرم افزار برای این روش Smart PLS می باشد.</p>< p dir="RTL" style="text-align:justify">دلایل استفاده از روش پی ال اس PLS و نرم افزار Smart PLS در پژوهش ها:</p>< p dir="RTL" style="text-align:justify">محققین دلایل متعددی را برای استفاده از روش پی ال اس (PLS) ذکر نموده اند. مهمترین دلیل، برتری این روش برای نمونه های کوچک ذکر شده است. دلیل بعدی داده های غیرنرمال است که محققین و پژوهشگران در برخی پژوهش ها با آن سر و کار دارند در نهایت دلیل آخر استفاده از روش پی ال اس (PLS)، روبرون شدن با مدل های اندازه گیری سازنده است.</p>< p dir="RTL" style="text-align:justify">دلایل استفاده از روش معادلات ساختاری پی ال اس (PLS – SEM) به شرح زیر است:</p>< ol> <li dir="RTL" style="text-align:justify">حجم کم نمونه</li> <li dir="RTL" style="text-align:justify">داده های غیر نرمال</li> <li dir="RTL" style="text-align:justify">مدلهای اندازه گیری از نوع سازنده</li> <li dir="RTL" style="text-align:justify">قدرت پیش بینی مناسب</li> <li dir="RTL" style="text-align:justify">پیچیدگی مدل ( تعداد زیاد سازه ها و شاخص ها)</li> <li dir="RTL" style="text-align:justify">تحلیل اکتشافی</li> <li dir="RTL" style="text-align:justify">توسعه تئوری و نظریه</li> <li dir="RTL" style="text-align:justify">استفاده از متغیرهای طبقه بندی شده</li> <li dir="RTL" style="text-align:justify">بررسی همگرایی</li> <li dir="RTL" style="text-align:justify">آزمودن تئوری و فرضیه</li> <li dir="RTL" style="text-align:justify">آزمودن فرضیات شامل متغیرهای تعدیلگر</li>< /ol>< p dir="RTL" style="text-align:justify">با توجه به موارد بالا، حجم نمونه اندک بهترین دلیل استفاده از PLS است. روش های نسل اول مدل سازی معادلات ساختاری که با نرم افزارهایی نظیر LISREL، EQS و AMOS اجرا می شدند، نیاز به تعداد نمونه زیاد دارند، در حالی که PLS (پی ال اس) توان اجرای مدل با تعداد نمونه خیلی کم را دارا می باشد.</p>< p dir="RTL" style="text-align:justify">یک مزیت مهم دیگر که محققین به آن استناد می کنند، امکان استفاده از مدل های اندازه گیری با یک شاخص (سوال) در روش PLS-SEM می باشد. این روش به پژوهشگر این امکان را می دهد که بتواند در مدل پژوهشی خود از مدل های اندازه گیری با یک سوال استفاده کند.</p>< p dir="RTL" style="text-align:justify">هدف ما شناخت شما دوستان بر مبانی تئوریک روش مدل سازی معادلات ساختاری (sem)با رویکرد تحلیل آماری پایان نامه است . مدل سازی معادلات ساختاری یکی از بهترین روش های آماریست که ابزاری در دست پژوهشگران جهت بررسی ارتباط بین متغیرهای مستقل ،وابسته ،میانجی و تعدیلگر در مدل است .</p>< p dir="RTL" style="text-align:justify">با تقدیم ادب و احترام حضور شما دوستان عزیزم میخواهم با شما دوستان خوبم در خصوص مدل سازی با این نرم افزار و بیان مزیت های اون و آموزش کلیدی جزییاتش صحبت کنم .</p>< p dir="RTL" style="text-align:justify">ببینید دوستان گلم یکی از مزیت های جالبی که مدل سازی معادلات ساختاری داره بررسی اثر متغیر ها روی هم در آن واحد است .</p>< p dir="RTL" style="text-align:justify">ضمنا برای شما دوستان در رشته مدیریت که حجم نمونه تحقیقتون پایینه بهتره که ازاین نرم افزار در ارائه فصل ۴ خود استفاده نمایید، چون این نرم افزار به حجم نمونه کم حساسیت نشون نمیده حتی با نمونه 50 تا 80 نفری جواب میده و مورد دیگری که میتونیم در نرم افزار pls اون رو شاخص قلمداد کنیم این است که تحلیل عاملی مرتبه دوم به بالا فقط از طریق این نرم افزار میسر است و امکان انجام تحلیل عاملی مرتبه دوم به بالا از طریق نرم افزار هایی مثل Amos،lisrelمقدور نیست و فقط از طریق نرم افزار plsامکان پذیر است .</p>< p dir="RTL" style="text-align:justify">شما میتونید با استفاده از نرم افزار pls مدل مفهومی تحقیقتون رو در حالت های مختلف اندازه گیری ،ساختاری و کلی نشون بدید .</p>< p dir="RTL" style="text-align:justify">برخلاف مدل های مبتنی بر کواریانس، مدل یابی مسیر با استفاده از روش PLS تا سال های اخیر به ندرت در علوم اجتماعی مورد استفاده قرار گرفته است. این در حالیست که الگوریتم اساسی آن در دهه 1970 توسعه یافته و اولین نرم افزار آن با نام LVPLS از دهه 1980 برای استفاده در دسترس بوده است. دلایل استفاده محدود از این نرم افزار را می توان عدم سهولت استفاده و مشکلات روش شناختی آن دانست.</p>< p dir="RTL" style="text-align:justify">در سال های اخیر این وضعیت تغییر کرده است و پژوهشگران می توانند برای مدل یابی به روش PLS از نرم افزارهای مختلفی مانند PLS-Graph، VisualPLS، PLS-GUI و SmartPLS استفاده نمایند. علاوه بر کاربرد آسان این نرم افزارها، نیاز به مدل یابی سازه های تشکیل شونده در علوم اجتماعی، موجب حرکت پژوهشگران به سمت روش های PLS و استفاده از این نرم افزارها شده است.</p>< p dir="RTL" style="text-align:justify"> از بین نرم افزارهای معرفی شده SmartPLS یکی از نرم افزارهای عمده و مهم مدل یابی مسیر با استفاده از PLS می باشد. بنابر گزارش سایت SmartPLS.de بیش از 10000 کاربر در جهان از این نرم افزار استفاده می کنند. این نرم افزار به علت داشتن رابط گرافیکی کاربر بسیار ساده و قابلیت های تحلیلی گسترده به یکی از محبوب ترین نرم افزارها در این زمینه بدل شده است.</p>< p dir="RTL" style="text-align:justify">نگاهی به قابلیت های نرم افزار SmartPLS : SmartPLS در سال 2005 توسط رینگل و همکاران وی در دانشگاه هامبورگ آلمان طراحی شده است. این نرم افزار مبتنی بر جاوا می باشد که باعث می شود کاربران سیستم های عامل مختلف از قبیل ویندوز، اپل مکینتاش و لینوکس به راحتی از آن استفاده نمایند. این نرم افزار قابلیت پردازش و تحلیل داده های خام را داراست. همچنین طراحی و آزمون مدل در آن به صورت کاملا گرافیکی انجام می شود. خروجی نرم افزار را می توان در قالب صفحات وب، اکسل و لاتکس مشاهده نمود. لازم به ذکر است که SmartPLS نیز همانند لیزرل و آموس قابلیت پردازش داده های خام را دارد. این نرم افزار داده های ورودی با فرمت CSV را که توسط SPSS یا Excel ایجاد می شود را دارد.</p>< p dir="RTL" style="text-align:justify">منبع : مقدمه ای بر مدل یابی معادلات ساختاری به روش PLS و کاربرد آن در علوم رفتاری / نوشته دکتر سید محمد سید عباس زاده / انتشارات دانشگاه ارومیه / 1391 .</p>< p dir="RTL" style="text-align:justify">در ادامیه یک جزوه بسیار خوب که توسط جناب یحیی بابایی تهیه شده است را قرار داده ام.</p>< p dir="RTL" style="text-align:justify"> هر گونه مشاوره آماری، تجزیه و تحلیل و آموزش خروجی گرفتن یا تفسیر خروجی در خصوص نرم افزار اسمارت پی ال اس (Smart Pls) را از موسسه آموزشی و پژوهش آمار7 بخواهید.</p>
اهمیت روز افزون تجزیه و تحلیل داده ها در تحقیقات علمی، باعث توجه هر چه بیشتر جامعه علمی به این مقوله شده است. همان گونه که یک پژوهش علمی بدون مروری بر ادبیات موضوع و کنکاش در نظریه ها، ناقص میماند، اضافه نمودن تحقیق میدانی به تئوری های مطالعه شده جلوه ی دیگری به پژوهش داده و اعتبار آن را دوصد چندان می کند. در این راستا،داده هایی که محقق از اعضای نمونه آماری تحقیق خود جمع آوری می نماید، احتیاج به تجزیه و تحلیل دارند تا تفسیر یافته ها و تعمیم نتایج میسر گردد.
در مطالعات حوزه ی علوم انسانی و اجتماعی، تجزیه و تحلیل داده های پژوهش طبق فرآیندی با قالب کلی مشخص و یکسان صورت می پذیرد که مرتبط با آن روش تحلیل آماری متعددی تا به حال معرفی شده است. در این میان، مدل سازی معادلات ساختاری (SEM) که در اواخر دهه شصت میلادی معرفی شد، ابزاری در دست محققین جهت بررسی ارتباط میان چندین متغیر در یک مدل را فراهم می ساخت. قدرت این تکنیک در توسعه نظریه ها باعث کاربرد وسیع آن در علوم مختلف از قبیل بازاریابی، مدیریت منابع انسانی، مدیریت استراتژیک و سیستم اطلاعاتی شده است. یکی از مهمترین دلایل استفاده زیاد پژوهشگران از SEM، قابلیت آزمودن تئوری ها در قالب معادلات میان متغیرهاست. دلیل دیگر لحاظ نمودن خطای اندازه گیری توسط این روش است که به محقق اجازه می دهد تا تجزیه و تحلیل داده های خود را با احتساب خطای اندازه گیری گزارش دهد.
مدل سازی معادلات ساختاری تا این زمان، با دو نسل روش های تجزیه و تحلیل داده ها معرفی شده است. نسل اول روش های مدل سازی معادلات ساختاری روش های کوواریانس محور هستند که هدف اصلی این روش ها تایید مدل بوده و برای کار به نمونه هایی با حجم بالا نیاز دارند. نرم افزارهای LISREL، AMOS، EQS و MPLUS چهار عدد از پرکاربردترین نرم افزارهای این نسل هستند. چند سال پس از معرفی روش کوواریانس محور، به دلیل نقاط ضعفی که در این روش وجود داشت، نسل دوم روش های معادلات ساختاری که مولفه محور بودند، معرفی شدند. روش های مولفه محور که بعدا به روش حداقل مربعات جزئی تغییر نام دادند، برای تحلیل داده ها روش های متفاوتی نسبت به نسل اول ارائه دادند.
پس از معرفی روش حداقل مربعات جزئی، این روش از علاقه مندان بسیاری برخوردار شد و پژوهشگران متعددی تمایل به استفاده از این روش پیدا کردند. مهمترین نرم افزار برای این روش Smart PLS می باشد.
دلایل استفاده از روش پی ال اس PLS و نرم افزار Smart PLS در پژوهش ها:
محققین دلایل متعددی را برای استفاده از روش پی ال اس (PLS) ذکر نموده اند. مهمترین دلیل، برتری این روش برای نمونه های کوچک ذکر شده است. دلیل بعدی داده های غیرنرمال است که محققین و پژوهشگران در برخی پژوهش ها با آن سر و کار دارند در نهایت دلیل آخر استفاده از روش پی ال اس (PLS)، روبرون شدن با مدل های اندازه گیری سازنده است.
دلایل استفاده از روش معادلات ساختاری پی ال اس (PLS – SEM) به شرح زیر است:
- حجم کم نمونه
- داده های غیر نرمال
- مدلهای اندازه گیری از نوع سازنده
- قدرت پیش بینی مناسب
- پیچیدگی مدل ( تعداد زیاد سازه ها و شاخص ها)
- تحلیل اکتشافی
- توسعه تئوری و نظریه
- استفاده از متغیرهای طبقه بندی شده
- بررسی همگرایی
- آزمودن تئوری و فرضیه
- آزمودن فرضیات شامل متغیرهای تعدیلگر
با توجه به موارد بالا، حجم نمونه اندک بهترین دلیل استفاده از PLS است. روش های نسل اول مدل سازی معادلات ساختاری که با نرم افزارهایی نظیر LISREL، EQS و AMOS اجرا می شدند، نیاز به تعداد نمونه زیاد دارند، در حالی که PLS (پی ال اس) توان اجرای مدل با تعداد نمونه خیلی کم را دارا می باشد.
یک مزیت مهم دیگر که محققین به آن استناد می کنند، امکان استفاده از مدل های اندازه گیری با یک شاخص (سوال) در روش PLS-SEM می باشد. این روش به پژوهشگر این امکان را می دهد که بتواند در مدل پژوهشی خود از مدل های اندازه گیری با یک سوال استفاده کند.
هدف ما شناخت شما دوستان بر مبانی تئوریک روش مدل سازی معادلات ساختاری (sem)با رویکرد تحلیل آماری پایان نامه است . مدل سازی معادلات ساختاری یکی از بهترین روش های آماریست که ابزاری در دست پژوهشگران جهت بررسی ارتباط بین متغیرهای مستقل ،وابسته ،میانجی و تعدیلگر در مدل است .
با تقدیم ادب و احترام حضور شما دوستان عزیزم میخواهم با شما دوستان خوبم در خصوص مدل سازی با این نرم افزار و بیان مزیت های اون و آموزش کلیدی جزییاتش صحبت کنم .
ببینید دوستان گلم یکی از مزیت های جالبی که مدل سازی معادلات ساختاری داره بررسی اثر متغیر ها روی هم در آن واحد است .
ضمنا برای شما دوستان در رشته مدیریت که حجم نمونه تحقیقتون پایینه بهتره که ازاین نرم افزار در ارائه فصل ۴ خود استفاده نمایید، چون این نرم افزار به حجم نمونه کم حساسیت نشون نمیده حتی با نمونه 50 تا 80 نفری جواب میده و مورد دیگری که میتونیم در نرم افزار pls اون رو شاخص قلمداد کنیم این است که تحلیل عاملی مرتبه دوم به بالا فقط از طریق این نرم افزار میسر است و امکان انجام تحلیل عاملی مرتبه دوم به بالا از طریق نرم افزار هایی مثل Amos،lisrelمقدور نیست و فقط از طریق نرم افزار plsامکان پذیر است .
شما میتونید با استفاده از نرم افزار pls مدل مفهومی تحقیقتون رو در حالت های مختلف اندازه گیری ،ساختاری و کلی نشون بدید .
برخلاف مدل های مبتنی بر کواریانس، مدل یابی مسیر با استفاده از روش PLS تا سال های اخیر به ندرت در علوم اجتماعی مورد استفاده قرار گرفته است. این در حالیست که الگوریتم اساسی آن در دهه 1970 توسعه یافته و اولین نرم افزار آن با نام LVPLS از دهه 1980 برای استفاده در دسترس بوده است. دلایل استفاده محدود از این نرم افزار را می توان عدم سهولت استفاده و مشکلات روش شناختی آن دانست.
در سال های اخیر این وضعیت تغییر کرده است و پژوهشگران می توانند برای مدل یابی به روش PLS از نرم افزارهای مختلفی مانند PLS-Graph، VisualPLS، PLS-GUI و SmartPLS استفاده نمایند. علاوه بر کاربرد آسان این نرم افزارها، نیاز به مدل یابی سازه های تشکیل شونده در علوم اجتماعی، موجب حرکت پژوهشگران به سمت روش های PLS و استفاده از این نرم افزارها شده است.
از بین نرم افزارهای معرفی شده SmartPLS یکی از نرم افزارهای عمده و مهم مدل یابی مسیر با استفاده از PLS می باشد. بنابر گزارش سایت SmartPLS.de بیش از 10000 کاربر در جهان از این نرم افزار استفاده می کنند. این نرم افزار به علت داشتن رابط گرافیکی کاربر بسیار ساده و قابلیت های تحلیلی گسترده به یکی از محبوب ترین نرم افزارها در این زمینه بدل شده است.
نگاهی به قابلیت های نرم افزار SmartPLS : SmartPLS در سال 2005 توسط رینگل و همکاران وی در دانشگاه هامبورگ آلمان طراحی شده است. این نرم افزار مبتنی بر جاوا می باشد که باعث می شود کاربران سیستم های عامل مختلف از قبیل ویندوز، اپل مکینتاش و لینوکس به راحتی از آن استفاده نمایند. این نرم افزار قابلیت پردازش و تحلیل داده های خام را داراست. همچنین طراحی و آزمون مدل در آن به صورت کاملا گرافیکی انجام می شود. خروجی نرم افزار را می توان در قالب صفحات وب، اکسل و لاتکس مشاهده نمود. لازم به ذکر است که SmartPLS نیز همانند لیزرل و آموس قابلیت پردازش داده های خام را دارد. این نرم افزار داده های ورودی با فرمت CSV را که توسط SPSS یا Excel ایجاد می شود را دارد.
منبع : مقدمه ای بر مدل یابی معادلات ساختاری به روش PLS و کاربرد آن در علوم رفتاری / نوشته دکتر سید محمد سید عباس زاده / انتشارات دانشگاه ارومیه / 1391 .






 از متغیرهای تصادفی مستقل با توزیع یکسان
از متغیرهای تصادفی مستقل با توزیع یکسان  را که بر یک فضای احتمال تعریف شدهاند در نظر بگیرید. فرض کنید میانگین
را که بر یک فضای احتمال تعریف شدهاند در نظر بگیرید. فرض کنید میانگین  و انحراف از معیار آن
و انحراف از معیار آن  است. حالا سری
است. حالا سری 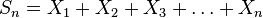 را در نظر بگیرید. میدانیم که میانگین
را در نظر بگیرید. میدانیم که میانگین  برابر
برابر 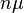 و انحراف از معیار آن
و انحراف از معیار آن 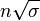 است. بر اساس قضیه حد مرکزی
است. بر اساس قضیه حد مرکزی  میل میکند.
میل میکند.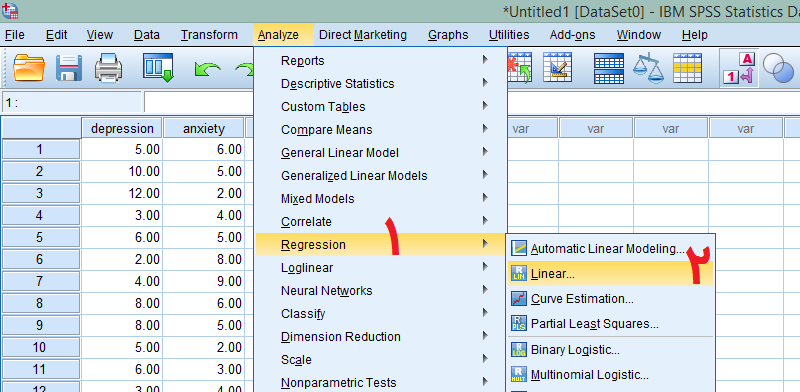 در کادر باز شده، متغیر وابسته یعنی پیشرفت تحصیلی را به کادر Dependent و متغیرهای مستقل یعنی افسردگی، اضطراب و استرس را به کادر Independent وارد میکنیم. سپس در گزینه Method میتوانیم از بین پنج روش یک روش را انتخاب کنیم که توصیه ما استفاده از روش ورود یا Enter و روش گام به گام یا Stepwise است که در اینجا خروجی هر دو مورد و نحوه گزارش آن را آموزش خواهیم داد.
در کادر باز شده، متغیر وابسته یعنی پیشرفت تحصیلی را به کادر Dependent و متغیرهای مستقل یعنی افسردگی، اضطراب و استرس را به کادر Independent وارد میکنیم. سپس در گزینه Method میتوانیم از بین پنج روش یک روش را انتخاب کنیم که توصیه ما استفاده از روش ورود یا Enter و روش گام به گام یا Stepwise است که در اینجا خروجی هر دو مورد و نحوه گزارش آن را آموزش خواهیم داد.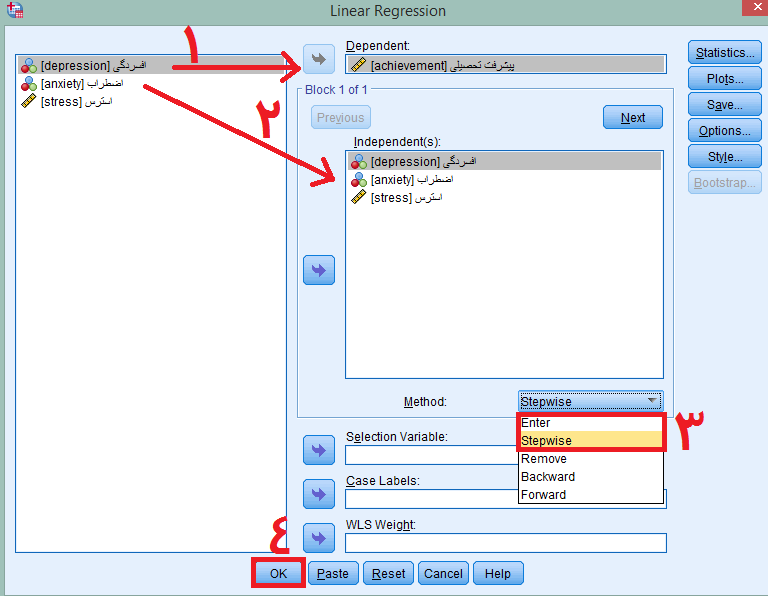 خروجی تحلیل رگرسیون خطی در SPSS به روش ورود یا همزمان
خروجی تحلیل رگرسیون خطی در SPSS به روش ورود یا همزمان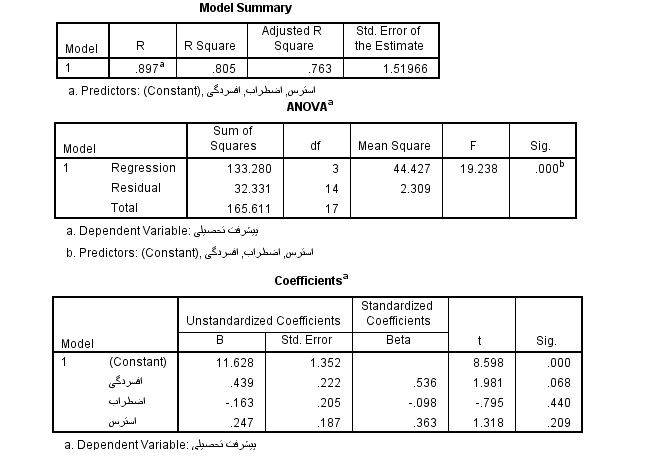 خروجی تحلیل رگرسیون خطی در SPSS به روش گام به گام
خروجی تحلیل رگرسیون خطی در SPSS به روش گام به گام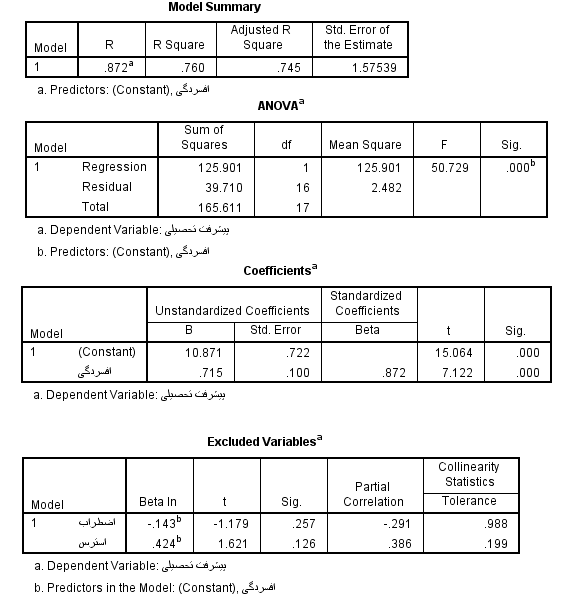 نحوه گزارش خروجی تحلیل رگرسیون خطی در SPSS
نحوه گزارش خروجی تحلیل رگرسیون خطی در SPSS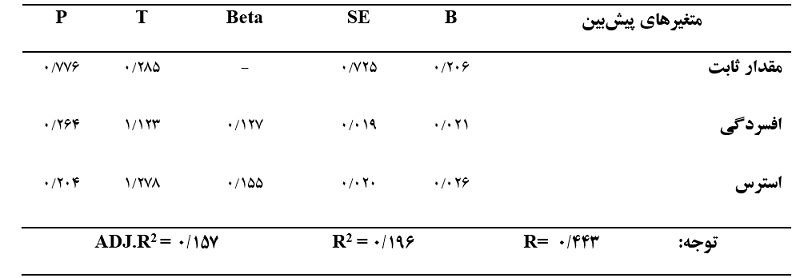 در جدول زیر یک نمونه از نحوه گزارش تحلیل رگرسیون به روش گام به گام آمده است. طبق اطلاعات جدول خروجی بالا باید جدول زیر را کامل نمایید. در روش گام به گام ابتدا متغیر اول براساس بیشترین میزان تاثیر وارد معاله میشود و اگر متغیرهای دیگر هم به صورت معنادار بتوانند بر متغیر وابسته اثرگذار باشند در گامهای بعدی وارد معادله میشوند. اطلاعات وارد شده در جدول زیر براساس خروجی بالا نیست و به عنوان نمونه وارد شده است.
در جدول زیر یک نمونه از نحوه گزارش تحلیل رگرسیون به روش گام به گام آمده است. طبق اطلاعات جدول خروجی بالا باید جدول زیر را کامل نمایید. در روش گام به گام ابتدا متغیر اول براساس بیشترین میزان تاثیر وارد معاله میشود و اگر متغیرهای دیگر هم به صورت معنادار بتوانند بر متغیر وابسته اثرگذار باشند در گامهای بعدی وارد معادله میشوند. اطلاعات وارد شده در جدول زیر براساس خروجی بالا نیست و به عنوان نمونه وارد شده است. نکات مهم در گزارش خروجی تحلیل رگرسیون خطی در SPSS
نکات مهم در گزارش خروجی تحلیل رگرسیون خطی در SPSS




















