- موضوع انتخابی تکراری نباشد.
- عنوان نباید خیلی طولانی یا خیلی کوتاه باشد.
- از به کار بردن اصطلاحات غیر رایج یا کلمات انگلیسی که معادل فارسی دارند پرهیز گردد.و از عنوانهای اختصاری استفاده نشود.
- موضوع بایستی به صورت خبری نوشته شود.
- در صورتی که عنوان مربوط به زمان و مکان خاصی است مکان و سال انجام تحقیق مشخص باشد.
- موضوع قابلیت اجراء داشته باشد.مثلا در مکان انتخابی تمامی شرایط و امکانات جهت انجام تحقیق موجود است یا خیر؟در غیر این صورت موضوع انتخابی مناسب نیست.
- موضوع باید کاربردی و مقرون به صرفه باشد.کار کردن روی موضوعی که با حداقل هزینه انجام گیرد و نتیجه ی آن برای رفع نیازهای اجتماعی مفید باشد موضوعی مناسب است.
- از لحاظ سیاسی و فرهنگی مورد تایید باشد.
- موضوع بایستی منع اخلاقی نداشته باشد.

تحلیل آماری یک ابزار بسیار مفید برای دستیابی به راهکارهای مناسب در زمانی که فرآیندهای واقعی تحلیل به شدت پیچیده یا در شکل واقعی آن ناشناخته است. میباشد. تحلیل آماری، فرآیند جمع آوری، بررسی، خلاصه سازی و تفسیر اطلاعات کمّی را برای ارائه ی دلایل زیربنایی، الگوها، روابط، و فرآیندها پوشش می دهد.
*********
اینجانب سیدسعید انصاری فر دارای لیسانس و فوق لیسانس مهندسی صنایع، فوق لیسانس مدیریت دولتی گرایش MIS و دانشجو دکترا مدیریت دولتی گرایش تصمیمگیری و خط مشیگذاری عمومی میباشم. برخی از سوابق علمی پژوهشی به شرح زیر است:
1- دارای بیش از 40 مقاله در موضوعات مختلف (کنفرانس های بین المللی و مجلات علمی پژوهشی و ژورنال ISC)
2- مولف سه کتاب (مبانی سازمان و مدیریت، آموزش مدل سازی معادلات ساختاری و SPSS، نگهداری کارکنان، چالش ها و نظریه ها)
3- مشاوره آماری و انجام تجزیه و تحلیل آماری در بیش از 700 پایان نامه ارشد و 50 پایان نامه دکترا
4- رتبه 7 کنکور دکترا
5- تدریس خصوصی آمار توصیفی و استنباطی و نرم افزارهای SPSS، AMOS، Smart PLS، LISREL
6- کسب رتبه پژوهشگر برتر و برگزیده در جشنواره علمی پژوهشی شهرداری اصفهان
*********
تماس با ما:
ایمیل: ansarifar2020@gmail.com
شماره همراه: 09131025408
شبکه اجتماعی ایتا: 09131025408
*********
گروه علمی آموزشی پژوهشگران برتر:
این گروه با بهره مندی از کادری مجرب آمادگی تجزیه و تحلیل کیفی و داده های کمی آماری در موضوعات مختلف با استفاده از نرم افزارهای مختلفی چون SPSS ، Smart PLS، LISREL،R ، AMOS، Nvivo، Max QDA را دارد.
همکاران:
1-مجید دادخواه
دکتری مدیریت از دانشگاه آزاد اصفهان
2- مرسا آذر:
دکتری مدیریت از دانشگاه آزاد اصفهان
3- زهرا وحیدی:
دکتری مدیریت آموزشی، مدرس تحلیل کیفی
4-محمد مهدی مقامی:
دکتری آمار از دانشگاه اصفهان
5- طناز فریدنی:
کارشناسی ارشد آمار و ریاضی از دانشگاه اصفهان
6- زینب احمدی:
کارشناسی ارشد روان شناسی از دانشگاه اصفهان
***********
از دلایلی که پژوهشگران انجام تحلیل آماری را به ما می سپارند:
- تیم حرفه ای و با تجربه
- متخصص در زمینه انواع نرم افزارهای تحلیل آماری با بیش از 10 سال تجربه
- پشتیبانی و آموزش حضوری به صورت رایگان
بایگانی
- آبان ۱۴۰۲ (۱)
- شهریور ۱۴۰۲ (۲)
- تیر ۱۴۰۱ (۲)
- دی ۱۴۰۰ (۱)
- شهریور ۱۴۰۰ (۲)
- مرداد ۱۴۰۰ (۲)
- تیر ۱۴۰۰ (۱)
- خرداد ۱۴۰۰ (۲)
- ارديبهشت ۱۴۰۰ (۲)
- فروردين ۱۴۰۰ (۲)
- بهمن ۱۳۹۹ (۳)
- دی ۱۳۹۹ (۴)
- آذر ۱۳۹۹ (۱)
- آبان ۱۳۹۹ (۴)
- مهر ۱۳۹۹ (۲۱)
- شهریور ۱۳۹۹ (۴)
- مرداد ۱۳۹۹ (۹)
- تیر ۱۳۹۹ (۸)
- خرداد ۱۳۹۹ (۲)
- ارديبهشت ۱۳۹۹ (۴)
- فروردين ۱۳۹۹ (۸)
- اسفند ۱۳۹۸ (۲)
- بهمن ۱۳۹۸ (۹)
- دی ۱۳۹۸ (۲)
- آذر ۱۳۹۸ (۵)
- آبان ۱۳۹۸ (۱۱)
- مهر ۱۳۹۸ (۳)
- شهریور ۱۳۹۸ (۲۷)
- مرداد ۱۳۹۸ (۱۳)
- تیر ۱۳۹۸ (۴)
- خرداد ۱۳۹۸ (۵)
- ارديبهشت ۱۳۹۸ (۱۶)
- فروردين ۱۳۹۸ (۶)
- اسفند ۱۳۹۷ (۲۶)
- دی ۱۳۹۷ (۱)
- مهر ۱۳۹۷ (۳۳)
- شهریور ۱۳۹۷ (۲۶)
آخرین مطالب
- ۰۲/۰۸/۱۱آزمون های آماری
- ۰۲/۰۶/۰۷تکنیک تحلیل مضمون
- ۰۱/۰۴/۲۹نمونه گیری نظری و کفایت نظری
- ۰۰/۱۰/۲۹روایی همگرا چیست؟ AVE
- ۰۰/۰۶/۰۲چولگی و کشیدگی
- ۰۰/۰۵/۱۰نحوه محاسبه اندازه اثر کوهن
پربیننده ترین مطالب
- ۹۸/۰۱/۲۳جامعه آماری و نمونه آماری چیست؟
- ۹۸/۱۲/۱۹آماره و پارامتر چیست؟
- ۹۹/۰۷/۰۶واریانس و انحراف معیار به زبان ساده
- ۹۸/۰۵/۰۶آزمون پارامتریک و ناپارامتریک چیست؟
- ۹۸/۰۳/۱۲آمار توصیفی، آمار استنباطی
- ۹۸/۰۶/۰۵آزمون T تک نمونه ای
- ۹۸/۰۶/۰۵انواع روش های نمونه گیری
- ۹۷/۰۷/۰۷منظور از p-value چیست ؟
محبوب ترین مطالب
- ۹۷/۰۶/۱۰تاریخچه مدل یابی معادلات ساختاری
- ۹۹/۰۵/۲۹رگرسیون لجستیک و انواع آن
- ۹۹/۰۶/۲۱آمار پارامتری و ناپارامتری
- ۹۷/۱۲/۰۲آزمون تحلیل کواریانس ANCOVA
- ۹۸/۰۶/۰۵فرایند انجام تحقیق علمی
- ۹۸/۰۱/۱۵متغیر تعدیل گر Moderation چیست؟
- ۹۸/۰۶/۱۴آموزش تحلیل رگرسیون خطی در SPSS
- ۹۸/۰۵/۰۶آزمون پارامتریک و ناپارامتریک چیست؟
مطالب پربحثتر
- ۹۷/۰۷/۰۷منظور از p-value چیست ؟
- ۹۸/۰۶/۱۴آموزش تحلیل رگرسیون خطی در SPSS
- ۹۹/۰۷/۰۶واریانس و انحراف معیار به زبان ساده
- ۹۸/۰۱/۲۳جامعه آماری و نمونه آماری چیست؟
- ۹۷/۰۶/۱۳مفهوم درجه آزادی در آمار چیست؟
- ۰۰/۰۲/۱۷تحلیل مضمون چیست؟
پیوندهای روزانه

اگر قرار نیست کارهای مطالعاتی و تحقیقاتی پیچیده انجام دهید و فقط میخواهید در هنگام مطالعهی متنهای عمومی مدیریتی، درک درستی از ضریب همبستگی داشته باشید، احتمالاً توضیحات زیر برای شما کافی خواهد بود:
- اگر ضریب همبستگی دو پارامتر با یکدیگر مثبت باشد، به این معناست که در فضایی که مطالعه و بررسی انجام شده، افزایش یک پارامتر با افزایش پارامتر دیگر و نیز کاهش آن پارامتر با کاهش پارامتر دیگر همراه است.
- اگر ضریب همبستگی دو پارامتر با یکدیگر منفی باشد، به این معناست که در فضایی که مطالعه و بررسی انجام شده، افزایش یک پارامتر با کاهش پارامتر دیگر و کاهش آن پارامتر با افزایش پارامتر دیگر همراه است.
- صفر بودن ضریب همبستگی به این معناست که دو پارامتر – در فضایی که مورد بررسی قرار گرفته – مستقل از یکدیگر بودهاند و بر اساس اطلاعات موجود از کاهش یا افزایش یکی، نمیتوان در مورد کاهش یا افزایش دیگری اظهار نظر کرد.
- ضریب همبستگی بین منفی یک و مثبت یک است. هر چه این ضریب از صفر دورتر شود (و به مثبت یا منفی یک نزدیکتر شود) میتوان نتیجه گرفت که روند هم جهت بودن یا مخالف بودن دو پارامتر مورد بررسی، جدیتر است.
- ضریب همبستگی هیچ ارتباطی با رابطهی علت و معلول ندارد. احتمال دارد در یک جامعهی آماری، بین حجم موتور ماشین و درآمد مالک ماشین، ضریب همبستگی مثبت وجود داشته باشد. اما این بدان معنی نیست که اگر ماشینی بخرید که حجم موتور بالاتری دارد، ثروتمندتر میشوید یا اگر سپردهی بانکی شما افزایش یابد، حجم موتور ماشین شما رشد خواهد کرد.
http://s3.picofile.com/file/8222422534/Excel_2010.pdf.html
محققین عزیز که بصورت جدی تری درگیر نرم افزار های آماری مثل spss، amos، smart pls، lisrel و …..هستند صد در صد در صفحات مختلف با گزینه ای به نام Bootstrap برخورد کرده اند. دانشجویانی که در در دوره های smart pls شرکت کرده اند عملا با آن درگیر بوده و آن را مورد بحث قرار داده اند. اما براستی Bootstrapping (بوت استراپینگ) چیست؟
ترجمه ای که برای آن در ادبیات آماری صورت گرفته است دستور خودگردان یا خودکار و یا خودگردان سازی بوده است. اما خودگردان سازی چیست؟ خودگردان سازی یا Bootstrap را می توان انجام نمونه گیری با جایگذاری از یک نمونه اصلی به دفعات زیاد دانست. یعنی ما از یک نمونه ثابت با حجم محدود به دفعات زیاد نمونه گیری مجدد البته با جایگذاری انجام می دهیم تا در نهایت بتوان با استفاده از نتایج کلیه ی دفعات نمونه گیری، در مجموع به یک توزیع نمونه ای دست یافت. دقت شود که هدف از نمونه گیری با جایگذاری این است که اقلام نمونه گیری شده پس از انتخاب به جامعه بازگردند تا بتوانند شانس حضور در نمونه های دیگر را پیدا کنند. در نهایت توزیع نمونه ای ایجاد شده مبنایی برای انجام تخمین ها، بویژه تخمین خطای معیار برای پارامتر های مختلف است.
در خودگردان سازی به جای آن که بر مبنای یک نمونه(نمونه اصلی) به تخمین خطای معیار دست بزنیم با انجام نمونه گیری های فرعی متعدد که اغلب بیشتر از ۲۰۰ بار است به یک توزیع نمونه ای تجربی دست میابیم که مبنای محاسبه خطای معیار قرار داده می شود. به این توزیع نمونه ای تجربی ، توزیع نمونه ای خودگردان یا Bootstrap گفته می شود(ژو، ۱۹۹۷)
مهمترین تفاوتی که باید گفته شود این است که در روش بدون Bootstrap شرط نرمال بودن توزیع داده ها وجود دارد اما در استنباط از طریق نمونه گیری خودگردان یا Bootstrap چنین شرطی وجود ندارد. یعنی اگر توزیع داده های ما نرمال نبود می توانیم از این روش برای استنباط و بررسی معناداری ضرایب آماری خود بهره ببریم(مرادی، ۱۳۹۵)
فراموش نشود که براین در مقاله خود در سال ۲۰۱۴ پیرامون مقایسه روش های مختلف با روش خودگردان سازی بحث نموده است و بیان کرده در نرم افزار های کواریانس محور مثل لیزرل و ایموس علی رغم وجود روش های خودگردان سازی بهتر است از قلب تپنده روش های کواریانس محور یعنی حداکثر درست نمایی که نیاز به حجم نمونه بالا و توزیع داده های نرمال است استفاده شود و روش خودگردان سازی را برای تحقیقات خاص با حجم نمونه کم و توزیع غیر نرمال و در جهت رویکرد های واریانس محور پیشنهاد می نماید(مرادی، ۱۳۹۵)
یکی از مفروضات مهم اکثر آزمونها به خصوص در آزمون های مربوط به فرضیه های علی این است که نباید بین متغییرها رابطه هم خطی وجود داشته باشد. بدین معنی که هیچ یک از متغییرهای مستقل نباید رابطه خطی با همدیگر داشته باشند. رابطه هم خطی وضعیتی است که نشان می دهد یک متغییر مستقل تابع خطی از سایر متغییرهای مستقل است. اگر هم خطی در یک معادله رگرسیون بالا باشد، بدین معنی است که بین متغییرهای مستقل همبستگی بالایی وجود دارد و در چنین حالتی با وجود بالا بودن R2 مدل اعتبار بالایی ندارد. به عبارت دیگر با وجود آنکه مدل خوب به نظر می رسد ولی دارای متغییرهای مستق معنی داری نمی باشد.
برای تشخیص هم خطی متغییرهای مستقل باید هنگام محاسبه رگرسیون غیر از برآورد model fit و Estimate،collinearity diagnostic را نیز انتخاب کنیم ؛ با این شیوه در جدولی شاهد نتایج آزمونهای تولرانس و عامل تورم واریانس نیز هستیم. تولرانس نسبتی از واریانس یک متغییر مستقل است که توسط سایر متغییرهای مستقل تبیین نشده است. ضریب تولرانس که بین صفر و یک نوسان دارد،نشان می دهد که متغییرهای مستقل تا چه اندازه رابطه هم خطی با همدیگر دارند. بنابراین هرچه مقدار تولرانس بیشتر نزدیک به عدد ۱ باشد، میزان هم خطی کمتر است و برعکس هر چه مقدار تولرانس کم تر(نزدیک تر به عدد ۰) باشد، نشان می دهد که میزان هم خطی بالاست و خطای استاندارد ضرایب رگرسیونی از تورم بالایی برخوردار خواهد بود.بنابراین در هنگام اجرای رگرسیون با مشکلاتی مواجه هستیم.
شاخص دیگر عامل تورم واریانس یا VIF است که از تقسیم عدد یک بر تولرانس حاصل می شود ، هرچه مقدار عامل تورم واریانس از عدد ۲ بزرگ تر باشد میزان هم خطی بیش تر است. نتیجه و تفسیر عامل تورم واریانس، معکوس تولرانس است یعنی هر چه مقدار تولرانس بیش تر باشد، مقدار عامل نورم واریانس کم تر است و بر عکس. به عبارتی هر چه مقدار این ضریب افزایش یابد باعث می شود که واریانس ضرایب رگرسیونی افزایش یافته و در نتیجه مدل رگرسیون را برای پیش بینی نامناسب جلوه می دهد. بنابراین هر چه مقدار عمل تورم واریانس برای یک متغییر مستقل بیش تر باشد نتیجه می گیریم که که آن متغییر نقش زیادی در مدل ، نسبت به بقیه متغییرها ندارد(محسن مرادی)

فرضیه علّی قضیه ای است که باید آزمون شود یا گزاره شرطی از روابط میان متغیر دو متغیر است. فرضیهها ، حدس و گمان ها درباره کارکرد جهان اجتماعی هستند. ، آن ها عاری از ارزش بیان می شود کرلینجر ۱۹۷۹ در کتاب خود پیرامون فرضیه ها بیان می کند که:
اهمیت فرضیه ها در پژوهش علمی ، فراتر از شناخت آنها و شیوه تدوین آنها است. فرضیه ها هدف بسیار مهم و ژرفی برای برانگیختن تفکر انسان ها دارند فرضیه ها ابزارهای توانمندی برای توسعه دانش می باشند که توسط انسان ها خلق میشوند ، ولی میتوانند آزمون نشده و درستی یا نادرستی آنها فارغ از ارزش ها و باورهای انسان نشان داده شود.
فرضیه علّی: گزاره هایی از تببین های علّی یا قضیه ای است که حداقل دارای یک متغیر مستقل و یک متغیر وابسته بوده و در عین حال باید به طور تجربی آزمون شود.
یک فرضیه علّی دارای پنج ویژگی است به این مثال دقت نمایید: شرکت در آیین های عبادی احتمال طلاق را کاهش میدهد ، میبینیم که به عنوان یک پیش بینی شرکت در آیین های عبادی رفتار متغییر وابسته ی طلاق در میان زوج هایی که در آیین های عبادی شرکت کنند می تواند به پیش بینی تجربی گذارد. فرضیه باید از لحاظ منطقی به یک سوال پژوهشی و یک نظریه مرتبط باشد. پژوهشگر ها به منظور پاسخ به سوال های پژوهش یا یافتن شواهد تجربی برای یک نظریه ، فرضیه ها را به آزمون می گذارند. گزارههایی که منطقا درست می باشد و یا سوال هایی که پاسخ به آنها توسط شواهد تجربی ناممکن است برای مثال زندگی خوب چیست؟ آیا خدا وجود دارد ؟ نمی توانند فرضیههای علمی تلقی شوند.
پنج ویژگی فرضیه های علّی :
- حداقل دارای دو متغیر است.
- یک رابطه علّی یا علت و معلولی میان متغیرها بیان می کند
- . میتواند به عنوان یک پیش بینی یا پیامد مورد انتظار بیان شود.
- از لحاظ منطقی به یک سوال پژوهشی و یک نظریه مرتبط است
- ابطال پذیر است ، یعنی می تواند در برابر شواهد تجربی آزمایش گردد و درستی یا نادرستی آن نمایان شود.
فرضیههای علّی به شکل های مختلفی بیان می شوند،گاهی اوقات از واژه علت استفاده می شود در حالیکه الزامی ندارد برای مثال ، یک فرضیه علّی درباره رضایت مشتری و وفاداری او می تواند به صورت زیر بیان شود
- رضایتمندی مشتری باعث افزایش سطح وفاداری مشتریان میشود.
- رضایتمندی مشتری منجر به بالا رفتن سطح وفاداری مشتریان میشود.
- رضایتمندی مشتری با وفاداری مشتریان رابطه ای علی دارد.
- رضایتمندی مشتری بر وفاداری مشتریان تاثیر می گذارد.
- رضایت مندی مشتریان با افزایش سطح وفاداری آن ها همراه است.
- رضایتمندی مشتری وفاداری او را ایجاد می کند.
- رضایتمندی مشتری به وفاداری مشتریان می انجامد.
- اگر مشتریان راضی باشند احتمال وفاداری مشتریان افزایش خواهد یافت.
- رضایت مندی مشتریان رفتار وفادارانه آن ها را پیش بینی می کند.
و …….(مرادی، ۱۳۹۷)
پژوهشگر ها هنگام آزمون فرضیه ها از به کار بردن واژه ثابت شده اجتناب میورزند. معمولا این واژه در روزنامهنگاری، دادگاهها و یا تبلیغات تجاری مورد استفاده قرار می گیرد. اما پژوهشگر ها به ندرت آن را به کار میبرد بر اساس نظر هیئت منصفه یک مدرک می تواند گناه فردی را اثبات کند و یا یک تبلیغ تجاری میگوید مطالعات ثابت کردهاند که برخی آسپرین ها به سرعت سردرد را درمان میکند. این زبانی نیست که در پژوهش علمی کاربرد داشته باشد و خلق دانش یک فرآیند مستمر است که از نتیجه گیری پیش از موعد جلوگیری می کند.. بحث اثبات، بر قطعیت قول و اطمینان قاطع یا عدم لزوم بررسی های آتی متکی است. به کارگیری واژه اثبات در دنیای علم باید با احتیاط به کار رود . با این که شواهد و فرضیات از آن ها حمایت می کنند اما آنها را اثبات نمی کنند. حتی پس از سالها مطالعه با نتایج یکسان در مورد موضوع چون ارتباط میان استعمال سیگار و سرطان ریه دانشمندان ادعایی مبنی بر اثبات آن نکرده اند و فقط می توانند پژوهشها تاکنون این فرضیه را حمایت کرده اند.
مهم ترین هدف تحلیل عاملی تاییدی تعیین میزان توان مدل عامل از قبل تعریف شده با مجموعه ای از داده های مشاهده شده است. به عبارتی تحلیل عاملی تاییدی درصدد تعیین این مساله است که آیا تعداد عامل ها و بارهای متغییرهایی که روی این عامل ها اندازه گیری شده اند با آنچه بر اساس تئوری و مدل نظری انتظار می رفت انطباق دارد. به عبارتی، این نوع تحلیل عاملی به آزمون میزان انطباق و همنوایی بین سازه نظری و سازه تجربی تحقیق می پردازد. در این روش ابتدا متغییرها و شاخص های مربوطه بر اساس تئوری اولیه انتخاب می شوند و سپس ازتحلیل عاملی استفاده می شود تا ببینیم که آیا این متغییرها و شاخص ها آن طوری که پیش بینی می شد روی عامل های پیش بینی شده بار(لود) شده اند یا این که ترکیب آنها عوض شده و روی عامل های دیگری بار شده اند؟
در این نوع تحلیل عاملی پیش فرض اساسی محقق این است که هر عاملی با زیرمجموعه خاصی از شاخص ها ارتباط دارد. حداقل شرط لازم برای تحلیل عاملی تاییدی این است که محقق قبل از هر چیزی تعداد عامل های مدل را فرض کند اما در عین حال معمولا این محقق انتظارات خود را مبنی بر این که کدام عامل ها بار خواهند شد دخیل می کند. برای مثال محقق سعی می کند تا تعیین کند که آیا متغییرهایی که برای ساخت و نمایش یک متغییر پنهان به کار می روند واقعا متعلق به هم هستند یا خیر؟ کاربردهای دیگری هم برای تحلیل عاملی تاییدی قابل ترسیم است که عبارتند از:
۱-تعیین اعتبار یک مدل عاملی
۲-مقایسه توان دو مدل متفاوت که مسئول مجموعه مشابهی از داده ها هستند.
۳-آزمون معنی داری یک بار عاملی خاص
۴-آزمون رابطه بین دو یا چند بار عاملی
۵-آزمون این که آیا مجموعه عاملها با یکدیگر همبستگی دارند یا خیر؟
۶-ارزیابی میزان اعتبار هم گرای مجموعه ای از متغییرها(میزان تجانس داخلی بین آنها)
۷-سنجش اعتبار یک مقیاس یا شاخص از طریق نمایش این موضوع که گویه های همساز بر روی یک عامل بار می شوند. بنابراین به کمک این روش می توان گویه های ناهمساز مقیاس را که بر روی چندین عامل بار بسیار بالا یا پایینی دارند از مقیاس حذف کرد.چون این متغییرها را نمی توان به یک عامل مشخص انتساب داد.
نکته ۱: بسیاری از روان شناسان بر این عقیده اند که تحلیل عامل تاییدی بر تحلیل عامل اکتشافی برتری دارد زیرا روش تحلیل تاییدی، فرضیه ها را مورد آزمون قرار می دهد و این آزمون فرضیه برای هر روش علمی امری اساسی است.
نکته ۲: دستور تحلیل عامل تاییدی بر خلاف تحلیل عامل اکتشافی در نرم افزار spss وجود ندارد و انجام آن توسط نرم افزارهایی مانند لیزرل، ایموس و …انجام می شود.
محسن مرادی
نکات مهمی که باید در تنظیم یک پرسش نامه رعایت گردد:
1. پرهیز از سوالهای نامفمهوم و مبهم (درباره ... چه فکر میکنید).
2. پرهیز از طرح سوالات هدایت کننده (آیا شما ... را ترجیح میدهید یا ... را که آزادی عمل بیشتری دارد ؟).
3. بیان ساده پرسشها (نظر شما درباره تاثیرات سیستم ... که بخشی از سیستم ... در مکانیزم ... چیست ؟).
4. از سوالهای چند وجهی که شامل چند سوال در یک پرسش است اجتناب شود. (آیا مدیر شرکت قادر به برقراری ... و برقراری ... و .... میباشد).
5. تا حد ممکن از ارایه سوالهای منفی خودداری شود (آیا شما با ... موافق نیستید؟).
6. از بیان سوالهایی که باعث ایجاد حساسیت شده و ایجاد مقاومت میکند پرهیز شود.
نکته : حتیالمقدور سؤالات تشریحی نبوده و چند گزینهای باشند.
نسبت دادن اعداد برای بیان ویژگیهای یک پدیده را اندازه گیری (Measurment) مینامند.
سطوح اندازه گیری:
1. اسمی (کیفی / مقولهای) Nominal
_ طبقه بندی براساس دارا بودن یا نبودن یک صفت یا ارزش میباشد (کارمندان زن – کارمندان مرد).
_ فقط میتوان محاسبات مربوط به نما و فراوانی را در مورد آنها انجام داد
2. ترتیبی (رتبهای)Ordinal
_ به طور نسبی شدت و ضعف و اندازه صفت یا ترجیحشان مشخص میگردد. طبقه بندی مدیران براساس سطح تحصیلات 1، 2، 3، ...
_ فراوانی، نما، میانه و ضریب همبستگی اسپیرین و چارک متوسط.
3. فاصلهای Interral
_ فاصله بین واحدهای اندازه گیری مشخص است. درآمد کارکنان در مقایسه با کمترین درآمد.
_ فراوانی، نما، میانه، میانگین، واریانس، انحراف معیار و ضریب همبستگی رتبهای و پیرامون.
4. نسبی Ratio
_ میتوان تفاوت میان مقولات آن را به طور دقیق کمی کرده و با عدد نشان داد. (وزن، سن، میزان درآمد).
_ کلیه عملیات آماری و ریاضی.
در مقوله ی سطوح اندازه گیری، نکات ذیل مهم می باشد:
_ وقتی یک پژوهشگر ناگریز به مقایسه پدیدهها است، اندازه گیری در سطح اسمی، کمتر از همه سودمند است.
_ اندازه گیری ترتیبی سودمندتر از اندازهگیری اسمی است.
_ اندازه گیری فاصلهای بسیار مطلوب است.
فرضیه یک حدس و احتمال زیرکانه مبتنی بر دانش یا تجربه در مورد حل یک مسأله یا پاسخ یک سؤال است. در واقع بیان حدسی و فرضی در مورد روابط احتمالی بین دو یا چند متغیر است.
تلاش نکنید تا فرضیه خود را اثبات نمایید، سعی کنید غلط بودن آنرا مطرح نمایید. (پاستور)
فرضیه ی آزموده شده = نظریه = علم
از آن جایی که هر پژوهش علمی باید آزمون پذیر باشد، در تحقیقات علوم اجتماعی باید از فرضیههای پژوهشی، فرضیههای آماری ساخت. که هدف توانمند سازی محقق در آزمون کردن فرضیه است.
فرضیه صفر Ho : نبود هیچ رابطه مهم بین دو متغیر _هدف رد کردن آن است. (ضعف آموزشی خلبان موجب سقوط هواپیما نمی باشد)
فرضیه صفر(فرضیه تحقیق) H1 : منطبق بر ادعای مطرح شده در فرضیه پژوهشی بوده و بیان کننده ی انتظار پژوهشگر درباره نتایج تحقیق است. (احتمالا ضعف آموزشی خلبان موجب سقوط شده است)
مثالی از یک فرضیه پژوهشی :
زنان نسبت به مردان، انگیزه کاری بیشتری دارند.

در این قسمت سعی داریم روشهای نمونه گیری و تعریف هریک از روشهای نمونه گیری احتمالی یعنی
1)نمونه گیری تصادفی ساده(Simple Random Sampling)
2)نمونه گیری تصادفی سیستماتیک (منظم)(Systematic Sampling)
3)نمونه گیری تصادفی طبقه بندی(Stratified Sampling)
4)نمونه گیری تصادفی خوشه ای (چند مرحله ای)(Cluster Sampling)
را فارغ از تئوری های ریاضیاتی و فرمولهای محاسباتی ارائه نماییم.
الف) نمونه گیری تصادفی ساده :در این روش نمونه گیری واحدهای مورد انتخاب دارای شانس مساوی برای انتخاب شدن هستند. در اینجا قوانین احتمال است که معین می کند کدام واحدها یا افراد از جمعیت مادر انتخاب خواهند شد. انتخاب یا از طریق قرعه کشی است ویا از طریق استفاده از جدول اعداد تصادفی. در روش قرعه کشی ابتدا کلیه واحدها یا افراد شماره بندی شده و یا اسامی آنها تهیه می شود و سپس به قید قرعه از بین آنها تعداد لازم برای نمونه انتخاب می شود. این نمونه گیری معمولا به یکی از روشهای زیر پیاده سازی می شود:
- نمونه گیری تصادفی ساده بدون جایگذاری :یک ویژگی مهم نمونه گیری تصادفی ساده بدون جایگذاری این است که احتمال استخراج هر واحد مشخص از جامعه در هر استخراجی مساوی با احتمال استخراج آن واحد مشخص در استخراج اول است .
- نمونه گیری تصادفی ساده با جایگذاری:اگر در انتخاب nواحد نمونه پس از انتخاب هر واحد آن را به جامعه بر گردانیم و انتخاب بعدی انجام دهیم نمونه گیری تصادفی ساده با جایگذاری می نامند در این روش انتخاب هر واحد مستقل از انتخاب واحدهای دیگر است. همچنین در این طرح نمونه گیری احتمال انتخاب مجدد و دوباره نمونه ها وجود دارد.
ب) نمونه گیری تصادفی سیستماتیک(منظم):نمونه گیری سیستماتیک مشتمل بر گزینش واحدها به روشی سیستماتیک و در نتیجه به صورتی غیر تصادفی است. منظور از این فن نمونه گیری معمولا پخش کردن واحدها به طور یکنواخت بر روی چارچوب است عنصر تصادفی بودن اغلب به این ترتیب دخالت داده می شود که اولین واحد را به طور تصادفی انتخاب می کنند . در این صورت گزینش اولین واحد، بقیه واحدهای نمونه را معین می کنند .
ج) نمونه گیری طبقه ای:در این روش نمونه گیری برای اجتناب از اشکالاتی که ممکن است در روش قبلی با آن مواجه شویم، افراد جامعه آماری را بسته به خصوصیاتی که آنها را از یکدیگر متمایز می سازد به طبقات مختلف تقسیم می کنیم. سپس به تعداد مورد نیاز و متناسب با جمعیت هر یک از طبقات افراد نمونه را انتخاب می کنیم .انتخاب افراد می تواند هم به روش تصادفی باشد و هم به روش تصادفی سیستماتیک. در جمعیتهای نا همگن که توزیع جمعیت در گروهها و طبقات مختلف متفاوت است، از روش نمونه گیری طبقه ای استفاده می شود .
د) نمونه گیری خوشه ای:در بسیاری از مواقع می توان بوسیله اجرای یک وسیله با انتخاب تصادفی گروهها یا خوشه هایی از واحدهای نمونه گیری به جای گرفتن نمونه تصادفی ساده از جامعه است. یکی از مزیت های این طرح نمونه گیری این می باشد که در میزان هزینه به طور اساسی صرفه جویی صورت می پذیرد. نمونه گیری خوشه ای ما را از ساختن چارچوب برای تمامی جامعه بی نیاز می کند که این چارچوب خود اغلب یک کار پر خرج و خسته کننده ای است. به علاوه چون واحدهای یک خوشه ,مجاور هم هستند و بنابراین دسترسی به آنها آسان است, فرایند نمونه گیری بطور قابل توجهی به صرفه است.

نقاط سبز رنگ، نمونههایی از توزیع نرمال دومتغیرهاند و محور آبی رنگ، مختصات جدید در راستای قرار گرفتن بیشترین تغییرات نمونه بر روی مؤلفههای اصلی است.
تحلیل مولفههای اصلی (Principal Component Analysis – PCA) تبدیلی در فضای برداری است، که غالباً برای کاهش ابعاد مجموعهٔ دادهها مورد استفاده قرار میگیرد.
تحلیل مولفههای اصلی در سال ۱۹۰۱ توسط کارل پیرسون ارائه شد. این تحلیل شامل تجزیه مقدارهای ویژهٔ ماتریس کواریانس میباشد.
جزئیات
تحلیل مولفههای اصلی در تعریف ریاضی یک تبدیل خطی متعامد است که داده را به دستگاه مختصات جدید میبرد به طوری که بزرگترین واریانس داده بر روی اولین محور مختصات، دومین بزرگترین واریانس بر روی دومین محور مختصات قرار میگیرد و همین طور برای بقیه. تحلیل مولفههای اصلی میتواند برای کاهش ابعاد داده مورد استفاده قرار بگیرد، به این ترتیب مولفههایی از مجموعه داده را که بیشترین تاثیر در واریانس را دارند حفظ میکند. برای ماتریس داده 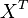 با میانگین تجربی صفر، که هر سطر یک مجموعه مشاهده و هر ستون دادههای مربوط به یک شاخصه است، تحلیل مولفههای اصلی به صورت زیر تعریف میشود:
با میانگین تجربی صفر، که هر سطر یک مجموعه مشاهده و هر ستون دادههای مربوط به یک شاخصه است، تحلیل مولفههای اصلی به صورت زیر تعریف میشود:

به طوری که  تجزیه مقدارهای منفرد ماتریس میباشد.
تجزیه مقدارهای منفرد ماتریس میباشد.
محدودیتهای تحلیل مولفههای اصلی
استفاده از تحلیل مولفههای اصلی منوط به فرضهایی است که در نظر گرفته میشود. از جمله:
- فرض خطی بودن
ما فرض می کنیم مجموعه داده ترکیب خطی پایههایی خاص است.
- فرض بر این که میانگین و کواریانس از نظر احتمالاتی قابل اتکا هستند.
- فرض بر این که واریانس شاخصه اصلی داده است.
محاسبه مولفههای اصلی با استفاده از ماتریس کواریانس
بر اساس تعریف ارائه شده از تحلیل مولفههای اصلی، هدف از این تحلیل انتقال مجموعه داده X با ابعاد M به داده Y با ابعاد L است. بنابرین فرض بر این است که ماتریس X از بردارهای  تشکیل شده است که هر کدام به صورت ستونی در ماتریس قرار داده شده است. بنابرین با توجه به ابعاد بردارها (M) ماتریس دادهها به صورت
تشکیل شده است که هر کدام به صورت ستونی در ماتریس قرار داده شده است. بنابرین با توجه به ابعاد بردارها (M) ماتریس دادهها به صورت  است.
است.
محاسبه میانگین تجربی و نرمال سازی دادهها
نتیجه میانگین تجربی، برداری است که به صورت زیر به دست میآید:
![u[m]=\frac{1}{N}\sum^{N}_{i=1}{X[m,i]}](http://upload.wikimedia.org/math/4/6/e/46e2db0b9336e9e61fb19691ff7bf2da.png)
که به طور مشخص میانگین تجربی روی سطرهای ماتریس اعمال شده است.
سپس ماتریس فاصله تا میانگین به صورت زیر به دست میآید:

که h برداری با اندازه 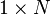 با مقدار ۱ در هرکدام از درایهها است.
با مقدار ۱ در هرکدام از درایهها است.
محاسبه ماتریس کواریانس
ماتریس کواریانس C با ابعاد  به صورت زیر به دست میآید:
به صورت زیر به دست میآید:
![C=\mathbb{E}[B\otimes B]=\mathbb{E}[B\cdot B^{\ast}]=\frac{1}{N}B\cdot B^{\ast}](http://upload.wikimedia.org/math/5/0/c/50c241be5d8692a9b08d288293bda0c5.png)
- به طوری که:
-
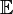 میانگین حسابی است.
میانگین حسابی است. -
 ضرب خارجی است.
ضرب خارجی است. -
 ماتریس ترانهاده مزدوج ماتریس
ماتریس ترانهاده مزدوج ماتریس  است.
است.
محاسبه مقادیر ویژه ماتریس کواریانس و بازچینی بردارهای ویژه
در این مرحله، مقادیر ویژه و بردارهای ویژه ماتریس کواریانس،  ، به دست میآید.
، به دست میآید.
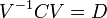
V ماتریس بردارهای ویژه و D ماتریس قطری است که درایههای قطر آن مقادیر ویژه هستند. آنجنان که مشخص است، هر مقدار ویژه متناظر با یک بردار ویژه است. به این معنا که ماتریس V ماتریسی است که ستونهای آن بردارهای ویژه میباشند و بردار ویژه 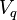 در ستون qام قرار دارد و مقدار ویژه qام یعنی درایهٔ
در ستون qام قرار دارد و مقدار ویژه qام یعنی درایهٔ  متناظر با آن است. بازچینی بردارهای ویژه بر اساس اندازهٔ مقادیر ویژه متناظر با آنها صورت میگیرد. یعنی بر اساس ترتیب کاهشی مقادیر ویژه، بردارهای ویژه بازچینی میشوند. یعنی
متناظر با آن است. بازچینی بردارهای ویژه بر اساس اندازهٔ مقادیر ویژه متناظر با آنها صورت میگیرد. یعنی بر اساس ترتیب کاهشی مقادیر ویژه، بردارهای ویژه بازچینی میشوند. یعنی 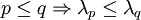
انتخاب زیرمجموعهای از بردارهای ویژه به عنوان پایه
 تحلیل مقادیر ویژه ماتریس کواریانس
تحلیل مقادیر ویژه ماتریس کواریانس
انتخاب زیرمجموعهای از بردارهای ویژه با تحلیل مقادیر ویژه صورت میگیرد. زیرمجموعه نهایی با توجه به بازچینی مرحله قبل به صورت  انتخاب میشود. در اینجا میتوان از انرژی تجمعی استفاده کرد که طبق آن
انتخاب میشود. در اینجا میتوان از انرژی تجمعی استفاده کرد که طبق آن
![g[m]=\sum_{q=1}^m{\lambda_q}](http://upload.wikimedia.org/math/0/f/f/0ffcd51a85da753ef5957da5f814ec00.png)
انتخاب l باید به صورتی باشد که حداقل مقدار ممکن را داشته باشد و در عین حال g مقدار قابل قبولی داشته باشد. به طور مثال میتوان حداقل l را انتخاب کرد که
![g[m=l] \leq 90%](http://upload.wikimedia.org/math/0/a/1/0a1298560bae33fd6440eae1b50e626c.png)
بنابرین خواهیم داشت:
![W[p,q] = V[p,q], p=1\dots M ,q = 1\dots l](http://upload.wikimedia.org/math/3/c/7/3c704fbbc9ab643526f2c54b4e932713.png)
انتقال داده به فضای جدید
برای این کار ابتدا تبدیلات زیر را انجام می دهیم: ماتریس  انحراف معیار مجموعه داده است که میتواند به صورت زیر به دست بیاید:
انحراف معیار مجموعه داده است که میتواند به صورت زیر به دست بیاید:
![s[i] =\sqrt{C[i,i]}](http://upload.wikimedia.org/math/0/8/6/086f1df445a97de8439854dcf5c631cc.png)
سپس داده به صورت زیر تبدیل میشود:
-
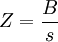 ‘
‘
-
که ماتریسهای و در بالا توضیح داده شده اند. دادهها میتوانند به ترتیب زیر به فضای جدید برده شوند:

نرمافزارها
در نرمافزار متلب تابع princomp مولفههای اصلی را باز می گرداند.
تجزیه مقدارهای منفرد
به عنوان یک تجزیه و فاکتورگیری ماتریسی، تجزیۀ مقدارهای منفرد یا تجزیۀ مقدارهای تکین (Singular value decomposition) قدمی اساسی در بسیاری از محاسبات علمی و مهندسی بهحساب میآید.
مثالها
ماتریس زیر را در نظر میگیریم:
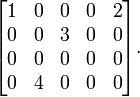
یکی از تجزیۀ مقدارهای منفرد این ماتریس به صورت زیر است:

یعنی داریم که
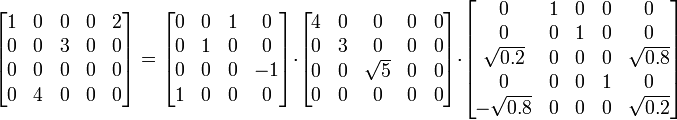
-
مقدار ویژه و بردار ویژه
مسأله مقادیر ویژه (Eigenvalue problem) (یا مسأله مقادیر ذاتی) مربوط به ماتریسها و عملگرها از جمله اساسیترین و ذاتیترین، و به همین جهت، پرکاربردترین مباحث و ابزار در بسیاری از زمینهها و میدانهای علوم و فنون قدیم و جدید میباشد.
فضای برداری با بعد متناهی
مسأله اول در مورد فضاهای برداری با بعد متناهی است. ماتریس مربعی
 را در نظر میگیریم. بردار غیر صفر
را در نظر میگیریم. بردار غیر صفر  را بردار ویژه ، و اسکالر
را بردار ویژه ، و اسکالر  را مقدار ویژه نظیر آن بردار میگوییم، چنانچه معادله ماتریسی زیر اقناع شود:
را مقدار ویژه نظیر آن بردار میگوییم، چنانچه معادله ماتریسی زیر اقناع شود:
در معادله ماتریسی حاضر دو مجهول وجود دارد: بردار ویژه
و مقدار ویژه . پس حل یکتایی برای آن وجود ندارد.مثال:
ماتریس زیر را در نظر میگیریم:

معادله ماتریسی بالا خواهد شد:
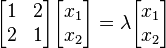
ابتدا معادله را به صورت همگن درآورده و بردار
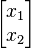 را که قرار است بردار ویژه ما باشد در فاکتور قرار میدهیم:
را که قرار است بردار ویژه ما باشد در فاکتور قرار میدهیم:
در واقع ما از ماتریس همانی (یکه) دوبعدی بهخاطر حفظ طبیعت ماتریسی جملهها استفاده کردهایم. پس از ضرب
 در ماتریس همانی و تفریق دو ماتریس داریم:
در ماتریس همانی و تفریق دو ماتریس داریم: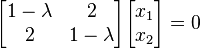
معادله ماتریسی حاصل حالتی خاص دارد. به منظور مقایسه و جهت وضوح در ادامه، معادله اسکالر بسیار ساده زیر را در نظر میگیریم:

که در اینجا
 عددی ثابت است. متغیر مجهول
عددی ثابت است. متغیر مجهول 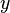 ، تنها و تنها، زمانی جواب غیر از صفر اختیار میکند که داشته باشیم:
، تنها و تنها، زمانی جواب غیر از صفر اختیار میکند که داشته باشیم:
که در این صورت، هر عددی جواب این معادله است.
برای معادله ماتریسی هم درست همین حالات را داریم. یعنی، برای وجود جوابهای غیر صفر به بردار ویژه
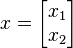 لازم است که دترمینان ماتریس ضرایب صفر شود، و اقناع همین شرط است که به شکلیابی معادله مشخصه ماتریس میانجامد. پس، داریم:
لازم است که دترمینان ماتریس ضرایب صفر شود، و اقناع همین شرط است که به شکلیابی معادله مشخصه ماتریس میانجامد. پس، داریم: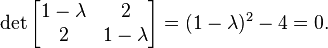
با حل این معادله درجه دوم دو جواب زیر برای دو مقدار ویژه ماتریس مفروض بهدست میآیند:

نکات و اشارات
تجزیه مقادیر ویژه را میتوان تکنیکی بسیار مؤثر و قوی در تبدیل پیچیدگی به سادگی دانست. با نگاهی دقیق به این معادله میشود رمز این توانائی را تا حدودی دید:
ضرب ماتریس
در بردار در سمت چپ (عملی سنگین) به ضرب تنها و تنها یک اسکالر ساده در همان بردار (عملی سبک و سریع) در سمت راست تقلیل یافته است.فضاهای بینهایت بعدی
توابع پیوسته ریاضی را میتوان بردارهایی با تعداد بینهایت مؤلفه در نظر گرفت، که در فضایی بینهایت بعدی جای گرفته باشد. عملگرهای قابل اعمال بر اینگونه بردارها هم بینهایت بعدی بوده و استفاده از مقدار ویژههای آنها نقشی کارسازتر و پراهمیتتر به خود میگیرد.
عملگر مشتقگیری
به عنوان یک مثال ساده و بسیار پر استفاده، عملگر مشتقگیری از توابع مشتقپذیر ریاضی را در نظر میگیریم:
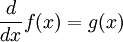
در این جا عملگر
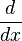 بر روی تابع مشتقپذیر
بر روی تابع مشتقپذیر 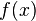 عمل نموده و تابع
عمل نموده و تابع 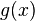 را به دست داده است.
را به دست داده است.مقدارهای ویژه مرتبط با آن به همان صورتی که در مورد ماتریسها دیدیم معرفی میشوند:

در اینجا به سبب بینهایت بودن بعد فضا، به جای بردار ویژه، عبارت تابع ویژه را داریم. در واقع در جستجوی توابعی هستیم که مشتق مرتبه اول آنها مضربی از خودشان است. با اندکی توجه در مییابیم که عمومیترین پاسخ در اینجا عبارت است از:

چرا که داریم:
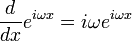
از همین نقطه است که مهمترین و فراگیرترین تبدیل فیزیک ریاضی — تبدیل فوریه — تولد مییابد.
در تحلیل واریانس یک راهه(ANOVA) متغیرهای مستقل کمّی می توانند به عنوان متغیرهای کمکی درنظر گرفته شوند. در این صورت این طرحها به عنوان تحلیل کواریانس در نظر گرفته می شوند. از تحلیل کوواریانس به عنوان یک کنترل آماری نام برده می شود. این تحلیل ترکیبی از تحلیل واریانس و تحلیل رگرسیون است و زمانی قابل استفاده است که در آن متغیر وابسته کمی بوده ، چند متغیر مستقل کمی و کیفی وجود داشته باشد. تحلیل کوواریانس در چارچوب رگرسیون تفاوتی با تحلیل واریانس ندارد جز آن که اثر متغیر کمکی از متغیر وابسته حذف می شود. متغیر کمکی را در چارچوب رگرسیون می توان یک متغیر مستقل دانست که در تبیین تغییرات متغیر وابسته بر سایر متغیر های مستقل پیشی می گیرد. در تحلیل رگرسیون می توان به راحتی با کنترل برخی از متغیرها اثرات سایر متغیرهای مستقل را در تبیین متغیر وابسته بدست آورد. فرض این است که متغیر کمکی منبع تغییراتی در متغیر وابسته علاوه بر متغیر مستقل باشدو از طریق تحلیل کواریانس اثرات ناشی از متغیرهای کمکی تعدیل شود. متغیر کمکی موثر در تحلیل کواریانس متغیری است که همبستگی بالایی با متغیر وابسته داشته ولی با متغیرهای مستقل همبستگی نداشته باشد چون متغیرهای کمکی پارامتری یا کمّی در طرح های تجربی و مطالعه پیمایشی به منظور حذف و از بین بردن اثرات خارجی بر متغیر وابسته و افزایش دقت اندازه گیری مورد استفاده قرار میگیرند. می دانیم که رد یک فرض نادرست توان آزمون نامیده می شودو به چندین عامل بستگی دارد از جمله: حجم نمونه، میزان تغییر پذیری در متغیر وابسته، طرح پژوهش و روش تحلیل آماری و سطح معناداری انتخاب شده توسط پژوهشگر. برخی از این روش ها در اختیار پژوهشگر نیست یا مستلزم صرف وقت و هزینه بالایی است، ولی انتخاب طرح آزمایشی، تحلیل آماری یا هر دو می تواند توان آماری را بدون صرف هزینه زیاد افزایش دهد. تحلیل کوواریانس موثرترین وسیله برای این منظور است و کل پراش را به سه بخش، پراش تبیین شده توسط کاربندی، پراش تبین شده توسط همپراش و پراش پسماند تقسیم می کند. اگر متغیر کمکی با پیامد همبستگی قوی داشته باشد پراش پسماند کوچک خواهد بود و توان آماری به شکل اساسی افزایش خواهد یافت.
پیش فرضهای لازم برای اجرای آزمون تحلیل کواواریانس عبارتند از:
۱- نرمال بودن.
۲- همگنی واریانس ها.
۳- رابطه بین متغیر وابسته با متغیر کمکی خطی فرض شود و یا رابطه بین متغیر وابسته و متغیر کمکی معنادار باشد.
۴- ضرایب خطوط رگرسیون با هم برابر باشند. و یا متغیر مستقل و کمکی با هم تعامل نداشته باشند.
آزمون t تک نمونه ای زمانی مورد استفاده قرار می گیرد که یک نمونه از جامعه داریم و می خواهیم میانگین آن را با یک حالت معمول و رایج استاندارد و یا حتی یک عدد مورد انتظار مقایسه کنیم. در این آزمون فرض بر این است که نمونه ای به حجم n و میانگین m از یک جامعه انتخاب کردهایم و می خواهیم بدانیم که آیا می توان این نمونه را یک نمونه تصادفی از جامعه دانست یا خیر؟
به عنوان مثال میتوان مقایسه میزان شوری آب یک دریاچه با میانگین معمول شوری آب دریاچه ها، مقایسه میانگین درآمد مردم یک شهر در مقایسه با میانگین درآمد کل کشور، مقایسه مقدار روغن موجود در یک کنسرو تن ماهی تولید شده توسط یک کارخانه با مقدار استاندارد تعریف شده روغن در یک کنسرو تن ماهی و مقایسه میانگین معدل دانش آموزان یک کلاس با یک میانگین مورد انتظار را نام برد.
مثال :
پژوهش گری در تحقیقی با عنوان "عوامل موثر بر پیشرفت تحصیلی دانش آموزان شهر تهران" فرضیه زیر را مطرح و به آزمون آن پرداخت.
"به نظر می رسد میانگین معدل های دانش آموزان شهر تهران از میانگین معدل های دانش آموزان در سراسر کشور بالاتر است".
نکته: برای اجرای آزمون t تک نمونه ای (one sample t test) دانستن مقدار مفروض و نظری ( در اینجا میانگین معدل های دانش آموزان در سراسر کشور ) ضروری است. در این مثال این مقدار برابر با 17 می باشد.
در این مثال یک نمونه 20 نفری از دانش اموزان شهر تهران تهیه شده و میانگین معدل هر کدام از دانش آموزان به شرح زیر بدست آمده است. نحوه وارد کردن داده ها به شرح زیر است.

پس از اجرا کردن دستور one sample t test مطابق با تصویر بالا، متغیر مورد را از کادر سمت چپ انتخاب کرده و به کادر سمت راست انتقال می دهیم. مقابل کادر Test Value میانگین مفروض (در اینجا 17) را تایپ کرده و OK را فشار می دهیم.

در قسمت نتایج Mean میانگین نمونه و Std deviation انحراف معیار نمونه و std error mean میزان اشتباه معیار میانگین را نشان می دهد. در جدول دوم t میزان تی محاسبه شده را نمایش می دهد، df درجه آزادی و sig. 2-tiled سطح معنی داری را نشان می دهد. مهمترین مطلب در این جدول میزان sig. می باشد که اگر این میزان از 05. کوچکتر باشد با اطمینان 95% و اگر از 01. نیز کوچکتر باشد با احتمال 99% تفاوت آماری معنی دار بین دو میانگین واقعی و مفروض وجود دارد. در مثال فوق به دلیل اینکه sig نه از 01. و نه از 05. کوچکتر نیست پس می توان نتیجه گرفت که میانگین معدل های دانش آموزان شهر تهران از میانگین معدل های دانش آموزان در سراسر کشور بالاتر نیست و همگی میانگین معدل مشابهی دارند.
وقتی محققین عزیز مدل سازی معادلات ساختاری می آموزند بعد از جمع آوری داده های پژوهش خویش به سراغ اجرای مدل در نرم افزار های مختلف مدل سازی معادلات ساختاری می روند و مدل خویش را بر اساس متغیر ها و شاخص های مختلف پژوهش خود نام گذاری می کنند. این عزیزان نباید فراموش کنند که همانطور که در دوره های مختلف آموزشی به آن ها توصیه شده، باید مقالات مختلفی که در کلاس ها به آن ها ارائه شده را مطالعه نمایند. نکته اینجاست که برای مطالعه این کتاب ها و مقالات باید نامگذاری یونانی پارامتر های یک مدل را بدانند زیرا تمامی کتاب ها و مقالات مرجع این حوزه بر اساس همین نامگذاری ها شروع به بحث پیرامون موارد مختلف کرده اند. در این مقاله تلاش شده نامگذاری صحیح تمامی پارامتر های مدل سازی معادلات ساختاری را با روش علمی بیان نماییم. البته علائم یونانی همه در شکل این مقاله مشخص هستند.
- متغیر مکنون برونزا: متغیر های مکنون برونزا ، متغیر های مکنونی هستند که در نقش علت( متغیر مستقل) بر متغیر های دیگر اثر می گذارند. در مدل سازی معادلات ساختاری آن ها را کسای(xi) یا ξ نامگذاری می کنند.
- متغیر مکنون درونزا: متغیر های مکنونی هستند که تحت اثر متغیر های مکنون برونزا می باشند. در مدل سازی معادلات ساختاری آن ها را اتا(eta) یا η نامگذاری می کنند.
- متغیر های آشکار اندازه گیری کننده متغیر های مکنون برونزا: این متغیر های آشکار در مدل به متغیر های مکنون برونزا متصل هستند. در مدل سازی معادلات ساختاری آن ها را ایکس یا X نامگذاری می کنند.
- متغیر های آشکار اندازه گیری کننده متغیر های مکنون درونزا: این متغیر های آشکار در مدل به متغیر های مکنون درونزا متصل هستند. در مدل سازی معادلات ساختاری آن ها را وای یا Y نامگذاری می کنند.
- خطاهای اندازه گیری شاخص های متغیر های مکنون برونزا: هر یک از سوالات متصل به متغیر های مکنون برونزا دارای خطای اندازه گیری هستند که به صورت عام فارغ از برونزا و یا درونزا بودن متغیر مکنون مربوطه در تحقیقات مختلف آن ها را با e نشان می دهند اما به صورت علمی در مدل سازی معادلات ساختاری آن ها را دلتا(delta) یا δ نامگذاری می کنند.
- خطاهای اندازه گیری شاخص های متغیر های مکنون درونزا: هر یک از سوالات متصل به متغیر های مکنون درونزا دارای خطای اندازه گیری هستند که به صورت عام فارغ از برونزا و یا درونزا بودن متغیر مکنون مربوطه در تحقیقات مختلف آن ها را با e نشان می دهند اما به صورت علمی در مدل سازی معادلات ساختاری آن ها را اپسیلون (xi) یا ε نامگذاری می کنند.
- بار عاملی: یک ضریب همبستگی بین متغیر های مکنون و متغیر های آشکار است که به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را لاندا(lambda) یا λ نامگذاری می کنند.
- کواریانس ها: همواره بین متغیر های برونزا در مدل به جهت اینکه این متغیر ها نباید با هم همخطی داشته باشند کواریانس وجود دارد. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را فی(phi) یا φ نامگذاری می کنند.
- ضرایب مسیر از متغیر های مکنون برونزا به درونزا: معمولا در حالت معمول بین این ضرایب مسیر با ضرایب مسیری که از یک متغیر درونزا به متغیر درونزای دیگر است تفاوتی قائل نمی شوند. اما در کتاب های مرجع معادلات ساختاری این دو نوع ضریب مسیر متفاوت نامگذاری می شوند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را گاما(Gamma) یا γ نامگذاری می کنند.
- ضرایب مسیر از متغیر های مکنون درونزا به درونزا: معمولا در حالت معمول بین این ضرایب مسیر با ضرایب مسیری که از یک متغیر برونزا به متغیر درونزای دیگر است تفاوتی قائل نمی شوند. اما در کتاب های مرجع معادلات ساختاری این دو نوع ضریب مسیر متفاوت نامگذاری می شوند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را بتا(Beta) یا β نامگذاری می کنند.
- خطای باقی مانده: در نهایت باید گفت که هدف از مدل سازی معادلات ساختاری پیش بینی رفتار یا واریانس متغیر های درونزا در مدل است. میزان این پیش بینی را شاخص R2 مشخص می کند و میزان عدم تبیین واریانس این متغیر ها را خطای باقی مانده مشخص می کند. به صورت علمی در مدل سازی معادلات ساختاری این پارامتر را زتا(Zeta) یا ζ نامگذاری می کنند.
البته در پایان خاطر نشان می شوم که نامگذاری به صورت های ساده دیگر یا هر نام گذاری دیگری در محاسبات تفاوتی ایجاد نمی کند اما اگر شما عزیزان قصد مطالعه کتاب ها و مقالات مرجع را داشته باشید باید این نامگذاری علمی را بدانید.
محسن مرادی
بعد از اجرای مدل در نرم افزار لیزرل( اعم از مدل اندازه گیری یا ساختاری)، در قسمت پایین نرم افزار دو شاخص برازش chi square و RMSEA توسط نرم افزار گزارش می شود. همچنین مقدار df درجه آزادی و نیز p value برای مقدار chi square گزارش می گردد. p value همان سطح معناداری یا خطایی است که محقق در رد فرض H0 مرتکب می شود و آن را در آژمون های آماری با sig نیز نمایش می دهند که اگر این مقدار کوچکتر از ۰٫۰۵ باشد در سطح اطمینان ۹۵ درصد و اگر کمتر از ۰٫۰۱ باشد در سطح اطمینان ۹۹ درصد فرض H0 رد و فرض H1 پذیرفته می شود.
اگر به فرض آماری آزمون chi square که مهمترین آزمون نیکویی برازش در مدل سازی معادلات ساختاری است توجه نماییم، می بینیم که:
H0: توزیع فراروانی مشاهده شده = توزیع فراوانی مورد نظر
H1: توزیع فراروانی مورد نظر≠ توزیع فراروانی مشاهده شده
بطور کلی نیز برازش مدل به این معنا است که تا چه اندازه مدل تخمین زده شده ما در نمونه آماری بر اساس مشاهدات با مدل مورد انتظار در جامعه تطابق دارد. بنابراین همانطور که از مفهوم برازش بر می آید بر خلاف اکثر آزمون های آماری که در آن آنچه محقق به دنبال آن است در فرض H1 قرار دارد، در آزمون chi square چیزی که محقق به دنبال آن است این است که مدل برازش داشته باشد.
یعنی توزیع فراروانی مشاهده شده = توزیع فراوانی مورد نظر
که این جمله در فرض H0 قرار دارد. بنابراین در اینجا بر خلاف بسیاری از آزمون ها ایده آل این است که p value یا همان sig بزرگتر از ۰٫۰۵ باشد و نه کوچکتر از آن.
اما دقیقا مسئله اینجاست که در بسیاری از مواقع مقدار p value کمتر از ۰٫۰۵ می شود و دوستان توجه نمی کنند که در حقیقت در این هنگام فرض H1 پذیرفته شده است و مؤید این امر است که بین مدل مشاهده شده در نمونه و مدل مورد انتظار در جامعه اختلاف معناداری وجود دارد. چگونه به این سوال باید در جلسات دفاع و یا در طرح های پژوهشی پاسخ داد؟
کلاین در سال ۲۰۰۵ در کتاب خود بیان نمود که نتایج آزمون chi square به حجم نمونه ها و نرمال بودن توزیع داده ها بسیار حساس است و زمانی که حجم نمونه ها چندان بزرگ نباشد اغلب عدم اختلاف بین مدل مشاهده شده در نمونه و مدل مورد انتظار در جامعه را حتی اگر انطباق بسیار بالایی وجود داشته باشد تشخیص نمی دهد و همچنین برعکس اگر نمونه ها بسیار بزرگ باشد اختلاف بین مدل مشاهده شده در نمونه و مدل مورد انتظار در جامعه را حتی اگر انطباق بسیار پایین وجود داشته باشد را تشخیص نمی دهد.
اساسا بخاطر همین مشکل بوده این شاخص توسط درجه آزادی تعدیل شده تا اثر حجم نمونه در آن کاسته شود و ما بجای خود کای دو شاخصی تحت عنوان کای دو به درجه آزادی را گزارش می کنیم. همچنین سایر شاخص های برازش در مدل سازی معادلات ساختاری اساسا بخاطر همین موضوع پدید آمدند.
محسن مرادی
مدل MIMIC که مخفف Multiple Indicators and MultIple Causesمی باشد و به مدل های ساختاری با معرف های چند گانه و علل چند گانه معروف می باشد. باید همین ابتدای بحث بیان کنیم که این مدل ها، مدل های خاصی هستند که مطابق با نظر هنسلر ۲۰۰۹ باید حتما ادبیات نظری قوی استفاده از آن ها را حمایت نماید. یعنی برای پژوهش هایی استفاده شود که در آن یک متغیر تحت تاثیر عوامل موثری باشد که این عوامل با یکدیگر هم خطی نداشته باشند. همچنین متغیر مکنون خود توسط گویه ها و معرف هایی در قالب یک مدل اندازه گیری انعکاسی مورد اندازه گیری قرار می گیرند و این گویه ها یا متغیر های آشکار باید با یکدیگر همبستگی داشته باشند.
به بیان دیگر عوامل موثر متغیر های آشکاری با تبعیت از الگوی ترکیبی و معرف ها یا شاخص ها متغیر های آشکاری با تبعیت از الگوی انعکاسی باشند. اما متاسفانه بسیاری اوقات در تحقیقات داخل کشور مشاهده می شود که از این مدل استفاده شده اما این اصل اساسی در نظر گرفته نمی شود.
یکی از مزایای اصلی این مدل این است که متغیر های اثر گذار بر متغیر مکنون می توانند کیفی(اسمی، ترتیبی) نیز باشند. دانشجویان آکادمی تحلیل آماری اطلاع دارند که در مدل سازی معادلات ساختاری با نرم افزار هایی مثل ایموس و لیزرل یا پی ال اس شرط اصلی حضور متغیر ها در مدل این است که متغیر ها کمی باشند و متغیر های اسمی و رتبه ای نمی توانند به عنوان متغیر های برونزا در مدل حضور داشته باشند(مگر در حالتی که تعدیلگر باشند) اما این در این نوع مدل ساختاری خاص این امکان وجود دارد(مرادی، ۱۳۹۶)
به شکل زیر توجه شود. دو متغیر مکنون مدل تحت تاثیر دو متغیر سن و جنسیت می باشند که هر دو نیز به صورت کیفی هستند و رابطه کواریانس بین آن ها جهت بررسی عدم هم خطی آن ها ترسیم شده است. از طرفی متغیر های آشکار اندازه گیری کننده دو متغیر مکنون باید دارای روایی همگرا و واگرا باشند و کلیه آزمون های بیان شده در دوره ها برای آن ها اجرا گردد.
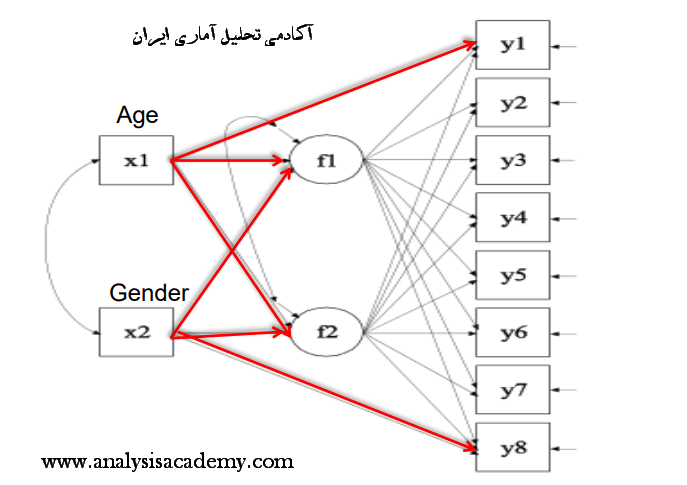
دکتر مرادی
در کارگاه های مختلف معادلات ساختاری بعضا محققین عزیز تصویر درستی از ماتریس کواریانس و ماتریس همبستگی ندارند و بسیاری اوقات این دو ماتریس و یا حتی این دو مفهوم را با هم اشتباه می گیرند. در این مقاله سعی دارم که خیلی ساده این دو مفهوم را مورد بحث قرار دهم تا محققین عزیز در تحلیل های خود با درکی دقیقتر جداول مربوطه در نرم افزار های SPSS، AMOS، LISREL و ……تحلیل و تفسیر نمایند.
قبل از باز کردن بحث ماتریس کواریانس و ماتریس همبستگی با مثالی فرق کواریانس و همبستگی را بیان می کنم. شما نرم افزار ایموس را که در دوره های مختلف بر آن تسلط پیدا کردید را باز کنید و دو متغیر آشکار را در آن رسم کرده و داده های SPSS آن را فراخوانی کرده و روی شکل رسم شده درگ کنید.
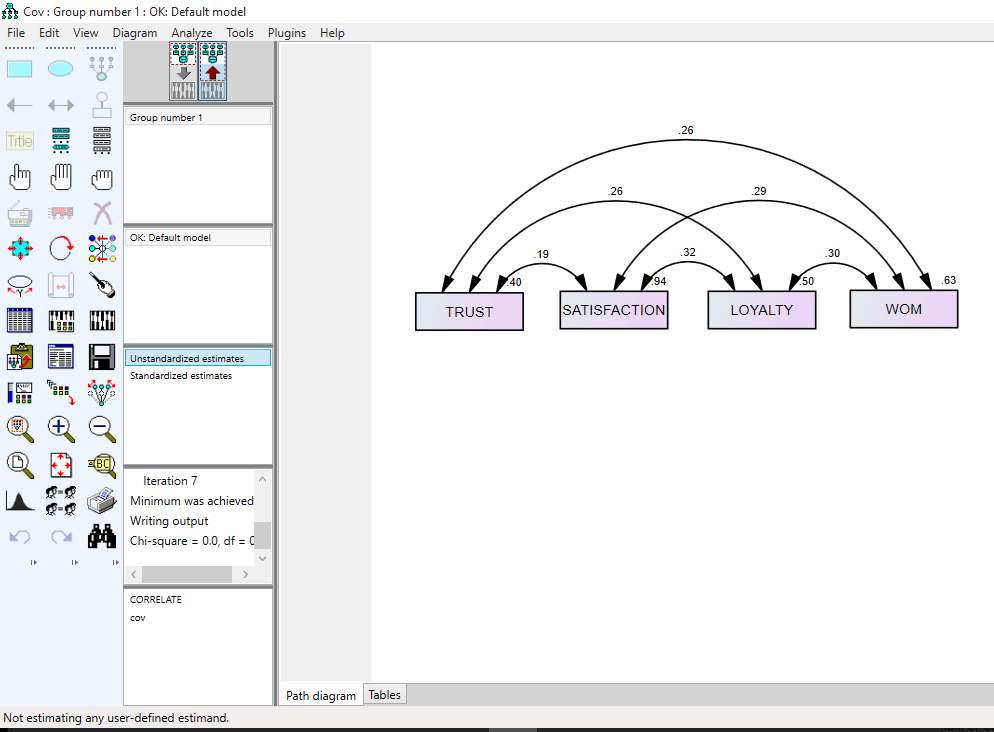
می بینیم که دو متغیر وفاداری(LOYALTY) و تبلیغات شفاهی(WOM) در صفحه رسم قرار داده شده اند و یک فلش دو طرفه بین دو متغیر قرار دارد. وقتی این مدل ساده و ابتدایی ران می شود عددی روی فلش دو طرفه در دو حالت تخمین غیر استاندارد و استاندارد قرار می گیرد.
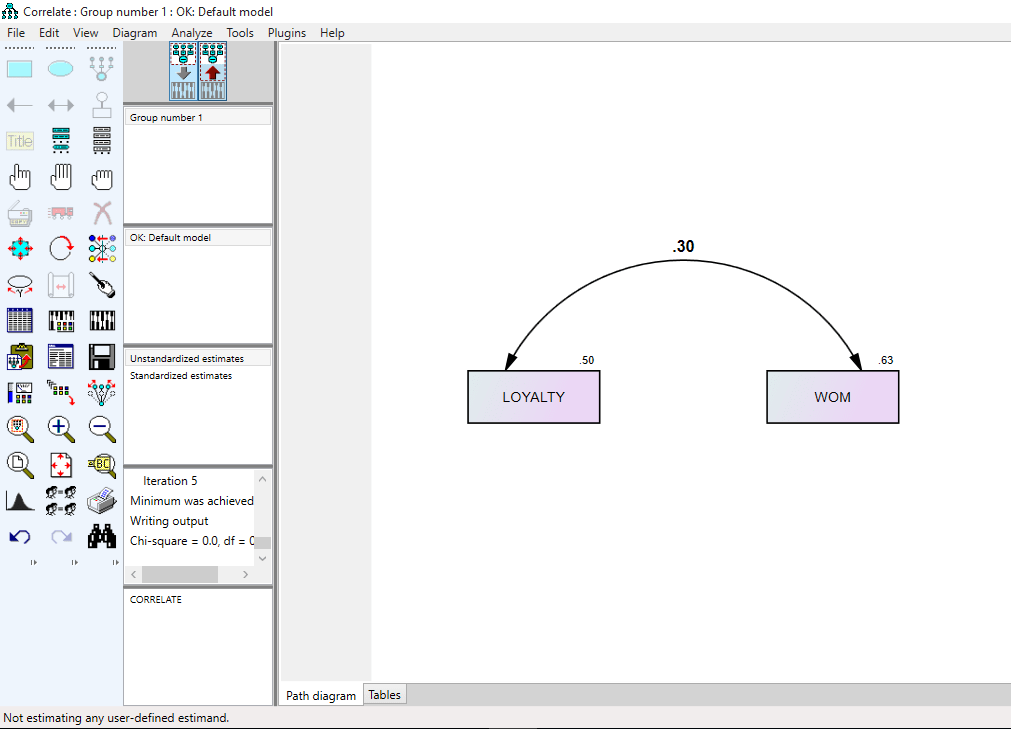
در شکل بالا عدد روی فلش کواریانس بین دو متغیر است و اعداد روی هر متغیر واریانس هر متغیر می باشد که نرم افزار در حالت تخمین غیر استاندارد گزارش می کند
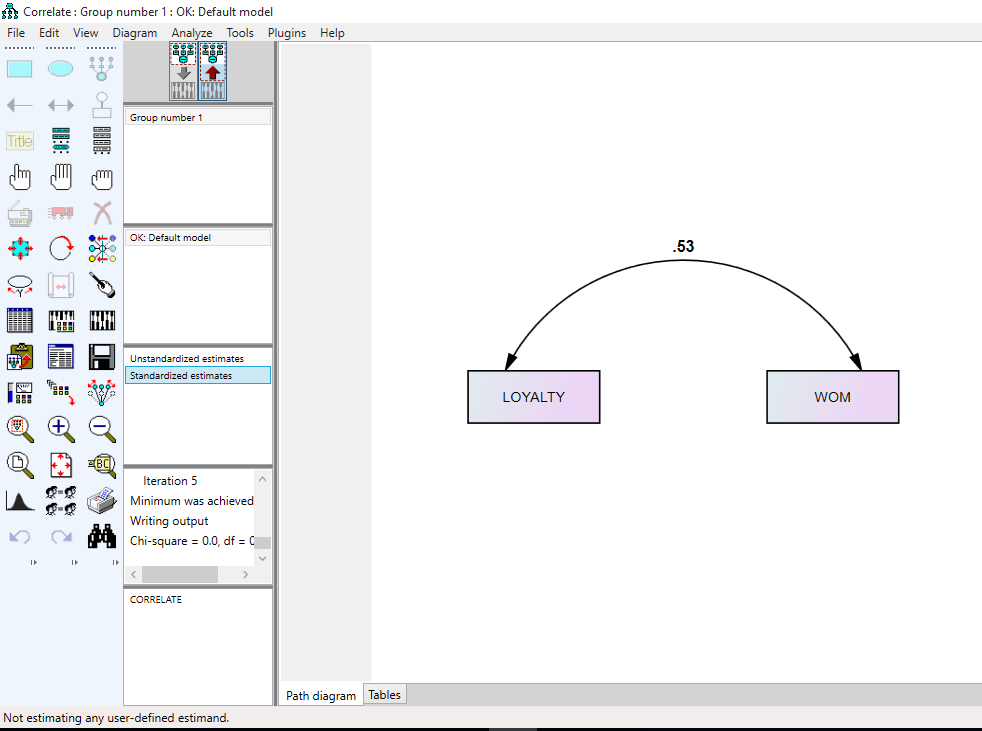
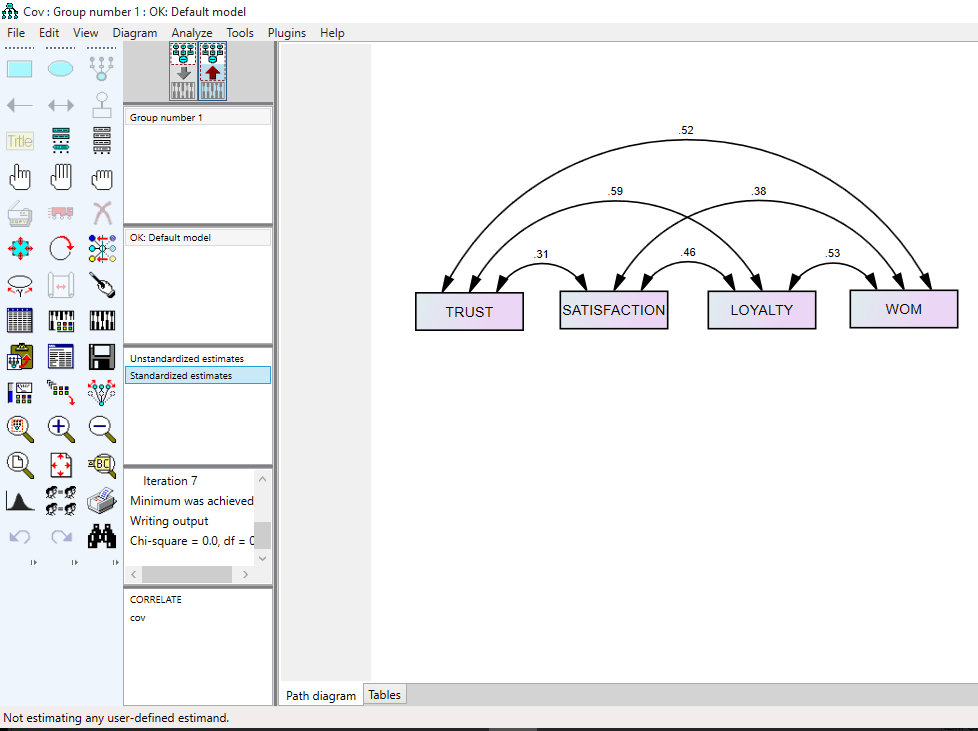
در حالت تخمین غیر استاندارد این ضریب ۰٫۳۰ و در حالت تخمین استاندارد این ضریب ۰٫۵۳ است. اما این اعداد چه معنایی می دهند؟ در حالت غیر استاندارد تخمین رابطه دو متغیر در حقیقت کواریانس بین دو متغیر است و در حالت تخمین استاندارد آن ضریب همبستگی بین دو متغیر است. بنابراین ضریب همبستگی بین دو متغیر را در واقع همان کواریانس بین دو متغیر است که استاندارد شده است. یعنی کواریانس استاندارد شده ضریب همبستگی بین دو متغیر گفته می شود.
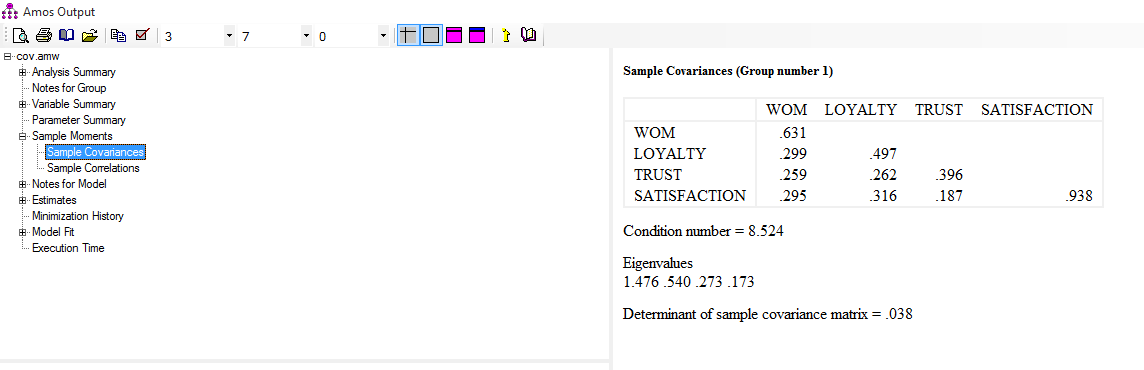
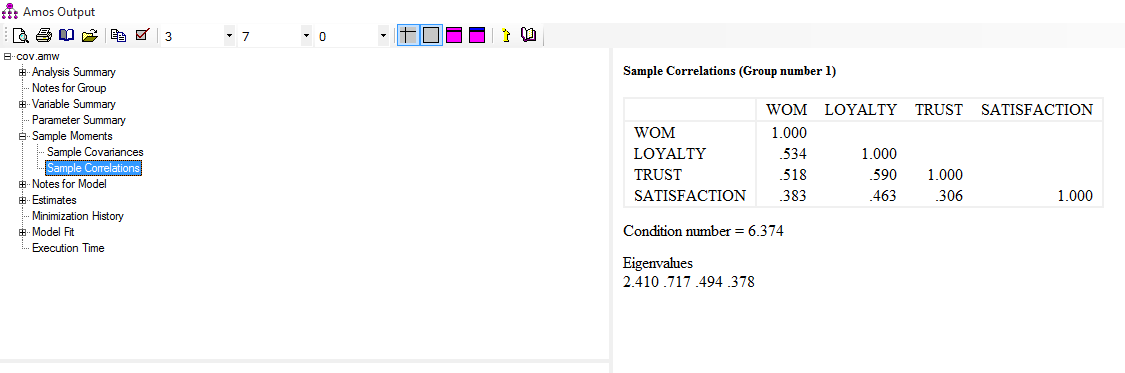
خوب همین بحث کوتاه را می توان به جداول یا ماتریس های کواریانس و همبستگی تعمیم داد. ماتریس کواریانس که در حقیقت همان اسم کوتاه شده ی ماتریس واریانس-کواریانس است در حقیقت جدولی است که روی قطر اصلی آن واریانس های هر متغیر و روی خانه های دیگر کواریانس بین متغیر ها به صورت دو به دو قرار دارد. ماتریس همبستگی در حقیقت همان استاندارد شده ی ماتریس کواریانس است که روی قطر اصلی آن عدد یک و روی خانه های دیگر همان ضرایب همبستگی بین متغیر ها، دو به دو قرار دارد.(مرادی، ۱۳۹۵)
در این مقاله آموزش می دهیم که این دو جدول را چگونه توسط SPSS و AMOS بدست آوریم و آن ها را با هم مقایسه کنیم. فایل داده ای وجود دارد که چهار متغیر اعتماد، رضایت، وفاداری و تبلیغات شفاهی را در آن مشاهده می کنیم. برای تشکیل جداول کواریانس و همبستگی راه های زیادی وجود دارد. اما یکی از ساده ترین روش ها از آدرس زیر صورت می گیرد.
Analyze > Scale > Reliability analysis
سپس در پنجره دیالوگ باز شده باید چهار متغیر را به پنجره سمت راست منتقل کنیم و بعد گزینه statistics را در سمت راست می زنیم.
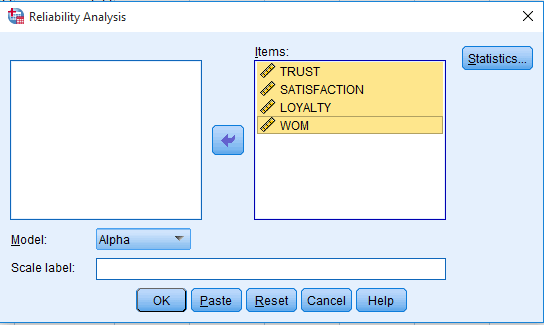
سپس در پنجره inter-item باید دو تیک مربوط به covariances و correlations را می زنیم. سپس continue زده و در پنجره بعد ok را می زنیم. در خروجی کار دو جدول کواریانس و همبستگی را که توضیحات آن را ارائه کردیم می بینیم.
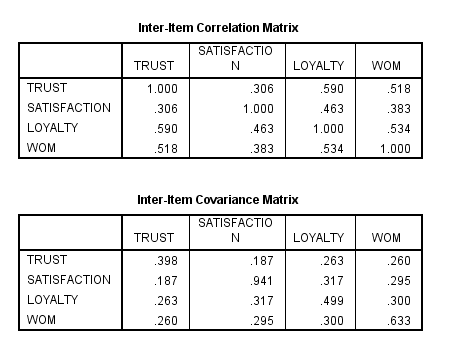
فراموش نکنیم در هر دو جدول تقارن وجود دارد یعنی اعداد پایین قطر اصلی و بالای قط اصلی یکی هستند زیرا رابطه ی دو متغیر در حالت غیر استاندارد و استاندارد در جداول قرار گرفته است. همچنین اعداد روی قطر اصلی در جدول کواریانس همان واریانس های متغیر هستند و اعداد روی قطر اصلی جدول همبستگی یک می باشد.
اگر بخواهیم همین جداول را در خروجی ایموس داشته باشیم باید چهار متغیر آشکار که فلش های دو طرفه بین تمام آن ها دو به دو متصل شده را رسم کنیم و بعد همین فایل spss را روی آن درگ کنیم. محققین عزیز طبق مطالب کلاس ها عمل کنند. فقط در اینجا باید در قسمت output حتما تیک sample moment و satandard estimate زده شود. زیرا اگر تخمین استاندارد را نداشته باشیم جدول همبستگی که همان حالت استاندارد جدول کواریانس است را نخواهیم داشت(مرادی، ۱۳۹۵)
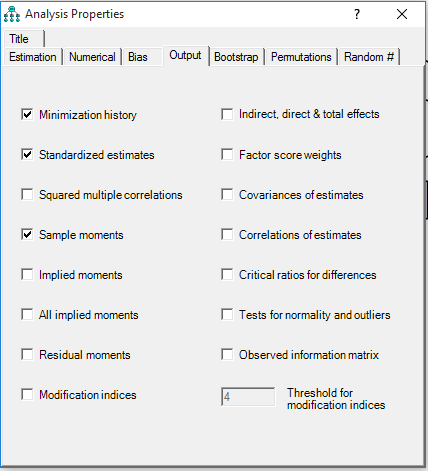
بعد از run مدل شکل را در حالت تخمین غیر استاندارد و استاندارد خواهیم داشت. تخمین غیر استاندارد ضرایب کواریانس است و حالت تخمین استاندارد ضرایب همان ضرایب همبستگی بین متغیر ها است.
بعد از مشاهده دو شکل غیر استادارد و استاندارد که ضرایب کواریانس و همبستگی بین هر کدام از آن ها قابل مشاهده است به سراغ خروجی ها از قسمت View Text میرویم و قسمت sample moment را میزنیم و دو جدولی که قبلا در خروجی spss دیدیم در اینجا نیز عینا مشاهده می کنیم. فراموش نشود بسیاری از عملیات نرم افزار spss در نرم افزار ایموس به صورت ترسیمی و بروز تر قابل انجام است.
https://analysisacademy.com/5125/correlation-covariance.html
دکتر محسن مرادی
این نمودار به صورت گرافیکی، هم بستگی بین دو متغیر کمی را در قالب نقاطی روی محور های عمودی و افقی نمایش می دهد. از طرفی از بخش correlate هم می توانستیم به ضریب همبستگی این دو متغیر دست یابیم.
اما گاهی محقق قصد دارد درست مانند ماتریس های همبستگی که حالت استاندارد شده ی ماتریس کواریانس می باشند رابطه چند متغیر کمی را با هم در نمودار های پراکنش نمایش دهند. یعنی همانطور که مثلا در یک ماتریس همبستگی رابطه ی همبستگی چند متغیر با یکدیگر و هم خطی تک تک متغیر ها و ضرایب همبستگی آن ها با یکدیگر در ماتریس بررسی می شود، در قالب نمودار های گرافیکی هم بتوان این مورد را نمایش داد.
بنابراین محققین به دستورات زیر برای رسم نمودار ماتریس پراکنش بین مثلا ۵ متغیر ارزش درک شده، اعتماد، رضایت، وفاداری و تبلیغات شفاهی که در کلاس های آکادمی انواع آزمون ها را روی آن ها اجرا کردیم، توجه نمایند.
ابتدا دستور زیر را در نرم افزار spss می رویم
سپس پنجره زیر باز می شود. در این پنجره بجای گزینه ی simple scatter که برای دو متغیر استفاده می شود از گزینه ی Matrix scatter استفاده می شود و سپس گزینه define زده می شود تا به پنجره دیالوگ اصلی وارد شویم
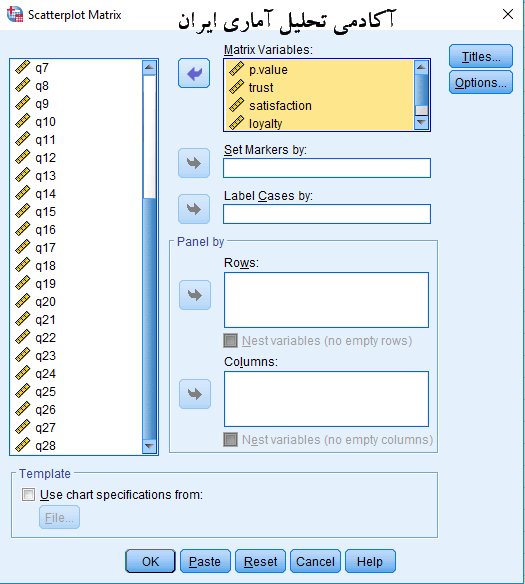
در پنجره زیر با عنوان scatterplot matrix که در حقیقت پنجره دیالوگ اصلی کار شما است ۵ متغیر کمی ارزش درک شده، اعتماد، رضایت، وفاداری و تبلیغات شفاهی را از سمت چپ به پنجره ی Matrix variables منتقل می کنیم و در پایان ok را کلیک می کنیم.
مشاهده می شود که درست مثل ماتریس های همبستگی نموداری گرافیکی از همبستگی متغیر های وارد شده در ماتریس داریم که دو به دو با هم رسم شده اند.بر اساس این نمودار ها پراکنش می توان شدت و جهت همبستگی بین متغیر ها را مشاهده نمود و درست مثل قطر اصلی ماتریس همبستگی که عدد ۱ می باشد می توان دید قطر اصلی نمودار ماتریس پراکنش بین چند متغیر خالی است که همان رابطه هر متغیر با خود می باشد.
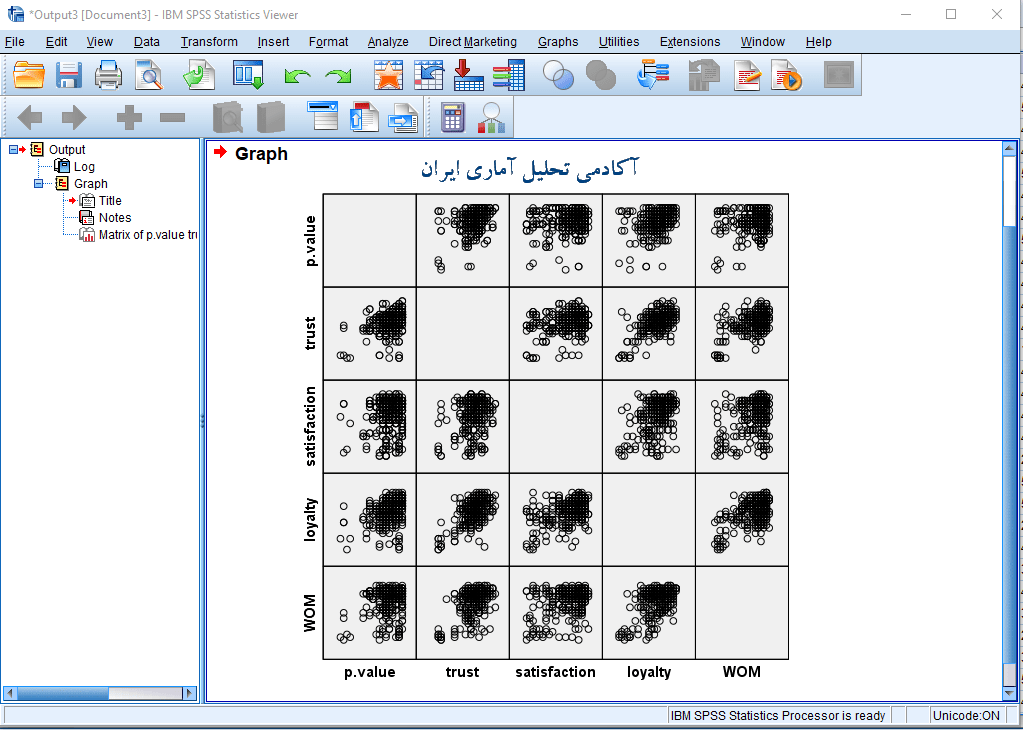
به دانش پژوهان عزیز پیشنهاد می شود که در پروژه های خود که دارای فرضیات رابطه ای و یا علی هستند از این نمودار ها در کنار ماتریس های همبستگی استفاده نمایند.
محسن مرادی