آموزش آزمون سوبل و متغیر میانجی
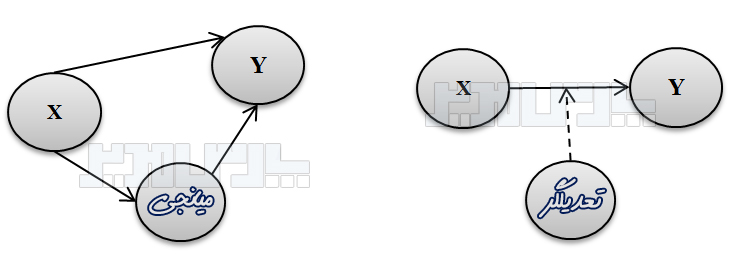
آزمون سوبل Sobel test روشی برای سنجش معتاداری اثر متغیر میانجی در آمار است. این آزمون توسط مایکل سوبل مطرح شده است که از اساتید دانشگاه کلمبیا در آمریکا است. همانطور که توضیح داده شد، متغیر میانجی M به عنوان رابط بین متغیر مستقل و متغیر وابسته قرار میگیرد و به صورت جداگانه میزان رابطه متغیرهای مستقل و وابسته را تحت تاثیر قرار میدهد. در مثال فوق متغیر «اعتماد» در رابطه «رضایت» و «وفاداری» نقش میانجی دارد. بنابراین آنچه در زمینه محاسبه اثر غیرمستقیم توضیح داده شد همان نقش میانجی است. در پژوهشهای دارای فرضیههای میانجی متغیر مستقل X از طریق متغیر M روی متغیر وابسته Y تأثیر میگذارد.
یک مدل میانجی ساده در تصویر زیر نمایش داده شده است. نقش میانجی متغیر M از طریق ضریب اثر غیرمستقیم ab اندازهگیری میشود. هر چند میتوان از راه بررسی معناداری ضرایب a و b به آزمون فرضیه میانجی پرداخت، امّا این روش توان آماری پایینی دارد. روش مناسبتر این است که به صورت مستقیم معناداری ضریب ab آزمون شود. یکی از پرکاربردترین روشها برای این منظور آزمون سوبل (Sobel) است.
متغیر میانجی
محاسبه آزمون سوبل
آزمون سوبل رویکرد حاصلضرب ضرایب، روش دلتا یا رویکرد نظریه نرمال هم نامیده شده است. آزمون سوبل برای انجام استنباط در مورد ضریب اثر غیرمستقیم ab، بر همان نظریه استنباط مورد استفاده برای اثر مستقیم مبتنی است. اثر غیرمستقیم ab یک برآورد خاص نمونه از اثر غیرمستقیم در جامعه (TaTb) است که در معرض واریانس نمونهگیری قرار دارد. با داشتن برآوردی از خطای استاندارد ab و با فرض نرمال بودن داده ها و توزیع نمونهگیری ab میتوان یک p-value برای ab به دست آورد.
بطور کلی در آزمون سوبل میتوان از تخمین نرمال برای بررسی معنیداری رابطه استفاده کرد. با داشتن برآورد خطای استاندارد اثر غیرمستقیم میتوان فرضیه صفر را در مقابل فرض مخالف آزمون کرد. آماره Z برابر است با نسبت ab به خطای استاندارد آن. به عبارت دیگر مقدار Z-Value را از رابطه زیر بدست میآوریم:
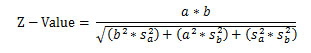
فرمول آزمون سوبل
در این رابطه:
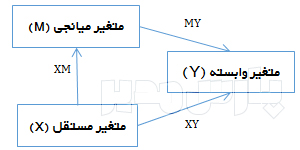
- a: ضریب مسیر میان متغیر مستقل و میانجی
- b: ضریب مسیر میان متغیر میانجی و وابسته
- Sa: خطای استاندارد مسیر متغیر مستقل و میانجی
- Sb: خطای استاندارد مسیر متغیر میانجی و وابسته
برای محاسبه خطای استاندارد در رگرسیون از جدول Model Summary قسمت Std. Error of the estimate استفاده کنید.
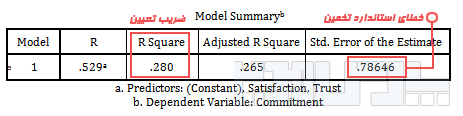
خطای استاندارد تخمین
براساس نتایح این جدول متغیرهای پیش بین توانستهاند ۲۸% از تغییرات در متغیر وابسته را تبیین کنند.
تفسیر نتایج
این برآوردگر حاصلضرب مجذور خطاهای استاندارد را از دو عبارت اول معادله کم میکند. به دلیل این که در برآورد گودمن امکان منفی شدن خطای معیار وجود دارد استفاده از آن توصیه نمی شود. مقادیر a و b و خطاهای استاندارد آنها میتوانند از خروجی تحلیل رگرسیون یا مدل معادلات ساختاری استخراج شوند. در نرم افزار SPSS برای به دست آوردن این مقادیر باید دو تحلیل رگرسیون اجرا شود:
اجرای یک تحلیل رگرسیون که در آن متغیر مستقل X متغیر پیش بین و متغیر میانجی M متغیر ملاک است. این تحلیل مقادیر a و sa رابه شما میدهد.
اجرای یک تحلیل رگرسیون که در آن متغیر مستقل X و متغیر میانجی M متغیر پیش بین و متغیر وابسته Y متغیر ملاک است. این تحلیل مقادیر b و sb رابه شما میدهد.
این محاسبات به سادگی میتواند با دست انجام شود. با در نظر گرفتن سطح خطای ∝=۰.۰۵ اگر مقدار Z از ۱/۹۶ بیشتر باشد، اثر غیرمستقیم مشاهدهشده از نظر آماری معنادار است.
منبع: آزمون سوبل و متغیر میانجی نویسنده آرش حبیبی کتاب آموزش SPSS