
مدل سازی معادلات ساختاری (SEM) مجموعه ای از روش های آماری است که به روابط پیچیده بین یک یا چند متغیر مستقل و یک یا چند متغیر وابسته اشاره می نماید. اگر چه روشهای متعددی برای توصیف SEM وجود دارد، بیشتر به عنوان ترکیبی بین برخی از اشکال تجزیه و تحلیل واریانس (ANOVA) / رگرسیون و بعضی از انواع تحلیل عاملی در نظر گرفته شده است.
مدل سازی معادلات ساختاریStructural Equation Modeling

مدل سازی معادلات ساختاری
مدل سازی معادلات ساختاری (SEM) مجموعه ای از روش های آماری است که به روابط پیچیده بین یک یا چند متغیر مستقل و یک یا چند متغیر وابسته اشاره می نماید. اگر چه روشهای متعددی برای توصیف SEM وجود دارد، بیشتر به عنوان ترکیبی بین برخی از اشکال تجزیه و تحلیل واریانس (ANOVA) / رگرسیون و بعضی از انواع تحلیل عاملی در نظر گرفته شده است. به طور کلی می توان گفت که مدل سازی معادلات ساختاری اجازه می دهد یک نوع رگرسیون چند متغیر / ANOVA را بر روی عوامل انجام دهیم. بنابراین باید کاملا با رگرسیون چند متغیره / ANOVA و همچنین مبانی تحلیل عاملی برای اجرای Structural Equation Modeling برای تحلیل آماری پایان نامه خود آشنا باشید.
اصطلاحات اولیه مفید در مدل سازی معادلات ساختاری
بعضی اصطلاحات اولیه نیز مفید خواهد بود. تعاریف زیر در مورد انواع متغیرهایی که در SEM اتفاق می افتد، برای توضیح دقیق تر استفاده از معادلات ساختاری مفید خواهند بود:
متغیر های بیرونی
متغیرهایی که تحت تاثیر متغیرهای دیگر در یک مدل قرار نمی گیرند، متغیرهای بیرونی (Exogenous) نامیده می شوند. به عنوان مثال، فرض کنید ما دو عامل داریم که باعث تغییر در GPA، ساعت مطالعه در هفته و IQ می شوند. فرض کنید هیچ رابطه علی بین ساعت مطالعه و IQ وجود ندارد. پس هر دو متغیر IQ و ساعت مطالعه متغیرهای بیرونی در مدل خواهد بود.
متغیرهای دورنی
متغیرهایی که تحت تاثیر متغیرهای دیگر در یک مدل قرار می گیرند، متغیرهای درونی (Endogenous) هستند. GPA یک متغیر درونی در مثال قبلی است .
متغیر آشکار
یک متغیر که به طور مستقیم مشاهده و اندازه گیری می شود، یک متغیر آشکار (همچنین متغیر شاخص در برخی حلقه ها نامیده می شود). در مثال اول، تمام متغیرها می توانند مستقیما مشاهده شوند و بنابراین به عنوان متغیرهای آشکار ساز واجد شرایط می شوند. یک نام خاص برای یک مدل معادلات ساختاری وجود دارد که تنها متغیرهای آشکار را بررسی می کند که تجزیه و تحلیل مسیر نامیده می شود .
متغیر پنهان
متغیری که مستقیما اندازه گیری نمی شود یک متغیر پنهان (Latent) است. “عوامل” در یک تحلیل عاملی، متغیرهای پنهان هستند. به عنوان مثال، فرض کنید ما همچنین به بررسی تاثیر انگیزه در GPA نیز علاقه مند بودیم. انگیزه، به عنوان یک متغیر درونی و غیر قابل مشاهده، به صورت غیرمستقیم توسط پاسخ دانشجویی بر روی یک پرسشنامه ارزیابی می شود و در نتیجه یک متغیر پنهان است.
نقش متغیرهای پنهان در مدل معادلات ساختاری
متغیرهای پنهان پیچیدگی یک مدل معادلات ساختاری را افزایش می دهند، زیرا باید تمام آیتم های پرسشنامه و پاسخ های اندازه گیری شده را که برای تعیین “عامل” یا متغیر پنهان استفاده می شود، مورد توجه قرار دهند. در این مثال، هر آیتم در پرسشنامه یک متغیر واحد خواهد بود که به طور قابل توجهی یا ناچیز در یک ترکیب خطی متغیرهایی که بر تغییرات در عامل پنهان انگیزه تأثیر می گذارند ، وارد می شود.
تعدیل یا اصلاح در مدلسازی معادلات ساختاری
به طور خاص، به منظور اهداف SEM، تعدیل یا اصلاح به وضعیتی اطلاق می شود که شامل سه یا چند متغیر است. به طوری که حضور یکی از این متغیرها رابطه بین دو دیگر را تغییر می دهد. به عبارت دیگر، تعدیل زمانی وجود دارد که ارتباط بین دو متغیر در تمام سطوح یک متغیر سوم یکسان نیست. یک راه برای فکر کردن به اصلاح زمانی است که شما در تعامل بین دو متغیر در ANOVA مشاهده می کنید. به عنوان مثال، تنش و تنظیم روانشناختی ممکن است در سطوح مختلف حمایت اجتماعی متفاوت باشد (به عنوان مثال، این تعریف یک تعامل است).
به عبارت دیگر، استرس ممکن است تحت شرایط کم رویی اجتماعی در مقایسه با شرایط حمایت اجتماعی، بر میزان تعدیل بیشتر تأثیر بگذارد. اگر یک ANOVA انجام شود، این امر به معنای تعامل دو طرفه بین استرس و حمایت روانی است. شکل ۱ نمودار مفهومی تعدیل را نشان می دهد. این نمودار نشان می دهد که سه اثر مستقیم وجود دارد که فرضیه ای برای ایجاد تغییرات در تنظیم روانشناسی وجود دارد – یک اثر اصلی استرس، یک اثر اصلی حمایت اجتماعی و یک اثر متقابل استرس و حمایت اجتماعی.
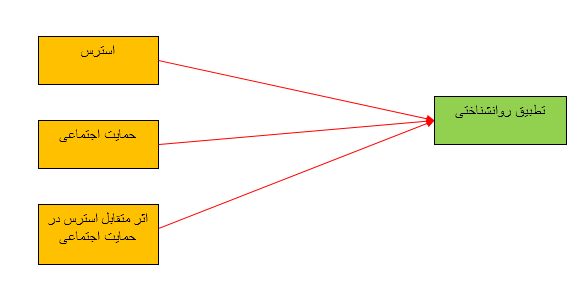
میانجی در مدل سازی معادلات ساختاری
به طور خاص، برای اهداف SEM، میانجی به وضعیتی اطلاق می شود که شامل سه یا چند متغیر است، به نحوی که یک فرآیند علی بین هر سه متغیر وجود دارد. توجه داشته باشید که این مجزای از میانجی است. در مثال قبلی در می توانیم بگوییم که در مدل سه چیز جداگانه وجود دارد که باعث تغییر در تنظیم روانشناختی می شوند: استرس، حمایت اجتماعی، و تاثیر متقابل استرس و حمایت اجتماعی که هر شخص به آن متغیر توجه نمی کند.
در یک رابطه میانجی، یک متغیر مستقل بین یک متغیر مستقل و یک متغیر وابسته وجود دارد. همچنین اثرات غیر مستقیم بین یک متغیر مستقل و یک متغیر واسطه و بین متغیر واسطه و یک متغیر وابسته وجود دارد. مثال بالا را می توان دوباره به یک فرآیند میانجی، به شکل زیر نشان داده شده است. تفاوت عمده ای از مدل تعدیل شده ، این است که ما اکنون می توانیم روابط علی میان استرس و حمایت اجتماعی و حمایت اجتماعی و تعدیل روانی را بیان کنیم.
تصور کنید که حمایت اجتماعی در مدل قرار نگرفته است – ما فقط می خواستیم تاثیر مستقیم استرس و تعدیل روانی را ببینیم. ما می توانیم با استفاده از رگرسیون یا ANOVA اندازه گیری اثر مستقیم را بدست آوریم. هنگامی که از حمایت اجتماعی به عنوان میانجی استفاده می کنیم، اثر مستقیمی در نتیجه تحلیل روند علیت به اثرات غیر مستقیم تأکید بر حمایت اجتماعی و حمایت اجتماعی از تنظیم روانشناختی تغییر خواهد کرد.
میزان تاثیر مستقیمی که در نتیجه شامل متغیر میانجی حمایت اجتماعی مطرح می شود، به عنوان اثر مداخله گر شناخته می شود. آزمون برای عامل میانجی شامل اجرای یک سری تحلیل های رگرسیون برای همه مسیرهای علمی و برخی از روش های تخمین تغییر در اثر مستقیم است. این تکنیک در واقع در مدل سازی معادلات ساختاری دخیل است که شامل متغیرهای میانجی است .
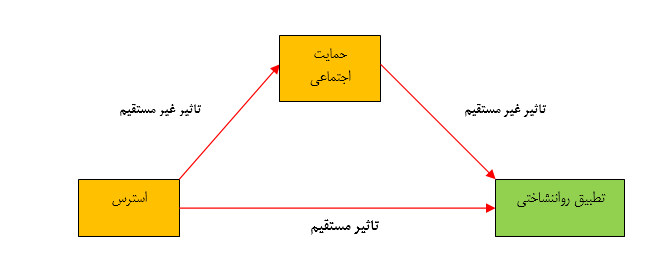
مدل سازی معادلات سارختاری
کواریانس و همبستگی
کوواریانس و همبستگی، بلوک های ساختاری از نحوه ارائه داده ها به نرم افزار برای اجرای مدل سازی معادلات ساختاری هستند. ماتریس کوواریانس در عمل به عنوان مجموعه داده های شما مورد تجزیه و تحلیل قرار می گیرد. در بستر SEM، کوواریانسها و همبستگی بین متغیرها ضروری هستند، زیرا آنها به شما اجازه می دهند رابطه بین دو متغیر که لزوما وابسته نیستند را بررسی کنید . در عمل، بیشتر مدل های معادلات ساختاری شامل روابط علیت و غیر علیت است. بدست آوردن تخمین کوواریانس بین متغیرها می تواند به منظور تخمین بهتر اثرات مستقیم و غیر مستقیم با متغیرهای دیگر، به ویژه در مدل های پیچیده با پارامترهای زیاد استفاده گردد.
مدل ساختاری
یک مدل ساختاری بخشی از کل نمودار مدل معادلات ساختاری است که شما برای هر مدل پیشنهاد می کنید. مدل ساختاری برای ارتباط همه متغیرها (پنهان و آشکار) مورد نیاز است .
مدل اندازه گیری
یک مدل اندازه گیری بخشی از کل نمودار مدل معادلات ساختاری است که شما برای هر مدل پیشنهاد می کنید. ضروری است که متغیرهای پنهان در مدل خود را داشته باشید. در این قسمت از نمودار که مشابه تحلیل عاملی است؛ شما باید تمام متغیرها یا مشاهدات را که «بار» بر روی متغیر پنهان، روابط، واریانس و خطاها قرار می دهید را شامل شود.
مدل سازی معادلات ساختاری
مدل ساختاری و مدل اندازه گیری، کل مدل معادلات ساختاری را تشکیل می دهند. این مدل شامل همه چیزهایی است که در مجموعه متغیرهایی که مورد بررسی قرار گرفته اند، اندازه گیری، مشاهده شده یا در غیر این صورت دستکاری شده اند.
معادله ساختاری بازگشتی
یک مدل معادله ساختاری بازگشتی، مدلی است که در آن یک رابطه در یک جهت واحد هدایت می شود.
منبع : stat.purdue
