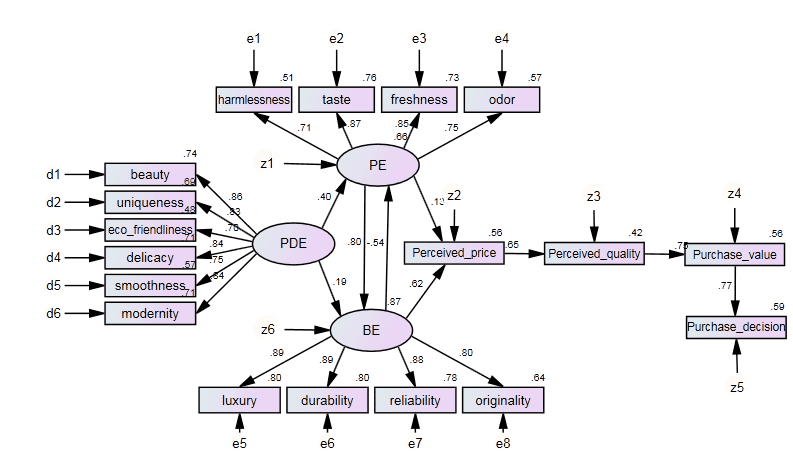
تعیین این که نمونه پژوهشی، تصادفی است تنها با نگاه کردن به آن مشخص نمی شود بلکه باید منطق تصادفی بودن در انتخاب نمونه به کار گرفته شود.
تصادفی بودن یک نمونه فقط از طریق فرایند نمونه گیری آن مشخص می شود. در نمونه گیری های احتمالی یا تصادفی، براساس قوانین احتمالات انتخاب نمونه به عمل می آید.
انتخاب نمونه و جمع آوری داده ها به گونه ای که بتوان نتایج حاصل را با احتساب اندازه های خطا (که با استفاده از روشهای آماری تعیین می شوند) به یک جامعه بزرگ تعمیم داد.
نمونه گیری تصادفی به این علت که اساس آن استفاده از روش های آمار استنباطی است در سایر روش ها ترجیح دارد.
اگر فرایند انتخاب نمونه از جامعه به روش غیر تصادفی انجام شود (یعنی انتخاب نمونه ای که آگاهانه و یا نااگاهانه تحت تأثیر قضاوت انسان باشد) یا نمونه ای قصد شده که همان نمونه گیری در دسترسی است، در این صورت انتخاب تصادفی، معنا و مفهوم خود را از دست می دهد.
انتخاب نمونه، باید از میزان سوداری و خطای انتخاب نمونه از جامعه هدف پژوهشی بکاهد.
انواع نمونه گیری های تصادفی یا احتمالی عبارت است از:
الف) نمونه گیری تصادفی ساده :
ب) نمونه گیری تصادفی منظم یا نظام مند (سیستماتیک ۳۲۱)
ج) نمونه گیری تصادفی متناسب با حجم (طبقه ای)
د) نمونه گیری خوشه ای
ه) نمونه گیری خوشه ای چند مرحله ای
در تمام این روش ها، نمونه به صورت تصادفی انتخاب می شود. J نمونه انتخاب شده تا حد زیادی معرف جامعه بزرگتر بوده و یافته های حاصل مطالعه گروه های نمونه را می توان با میزان قابل قبولی از خطا، به جامعه بزرگتر تعمیم داد.
جهت آشنایی بیشتر، هریک از این روش ها در مقالات دیگر سایت توضیح داده می شود.
۲. نمونه گیری غیر تصادفی (غیر احتمالی)
در فرایند پژوهشی و به منظور انتخاب نمونه، شرایط نمونه گیری تصادفی همیشه امکان پذیر نیست، در نتیجه، پژوهشگر ناگزیر است از روشهای غیر تصادفی استفاده کند.
در نمونه گیری غیر احتمالی یا غیر تصادفی، چون انتخاب هریک از شرکت کنندگان نامشخص است، در این نمونه گیری بر خلاف نمونه گیری تصادفی، پاره ای از افراد شانس بیشتر و یا نامعینی برای انتخاب دارند و نمونه انتخاب شده معرف کمتر بوده و نتایج حاصله نیز قابل تعمیم نمی باشد.
در نتیجه، در روشهای غیر تصادفی، کمتر توان و قابلیت تعمیم دارد و تعمیم هایی که از این طریق صورت می گیرد می بایست از طریق دانش و شناخت فرد از موضوع، مورد پالایش قرار گیرد.
اما با توجه به برخی محدودیتها و موقعیتها در استفاده روش تصادفی، گاهی هم پژوهشگر چاره ای جز نمونه گیری به روش غیر تصادفی ندارد.
نمونه گیری غیر تصادفی، به چند دسته تقسیم می شود:
۱. نمونه گیری در دسترسی یا اتفاقی
۲. نمونه گیری هدفمند (تعمدی) یا قضاوتی
۳. نمونه گیری سهمیه ای
۴. نمونه گیری گلوله برفی یا افزایشی (زنجیرهای)
۵. نمونه گیری موردی (مطالعه موردی شناخته شده)
۶. نمونه گیری منطقه ای
۷. نمونه گیری چند درجه ای
در این نوع نمونه گیری هر یک از اعضای جامعه تعریف شده شانس برابر و مستقلی برای قرار گرفتن در نمونه دارند.
منظور از مستقل بودن این است که انتخاب یک عضو به در انتخاب سایر اعضای جامعه تأثیری ندارد.
نمونه گیری به روشی تصادفی، شانس نماینده بودن نمونه و جامعه بدون سوگیری و جمہت گیری خاصی، افزایش می دهد.
در این روش ابتدا فهرست اسامی تمامی اعضا را به دست آورده، سپس به هر یک از آنها نمره ای یا عددی اختصاص می یابد و با استفاده از جدول اعداد تصادفی تعداد مورد نیاز انتخاب می شود.
اگر جامعه مورد مطالعه کوچک باشد از روش قرعه کشی استفاده می شود، یعنی اسامی افراد را بر روی یک کاغذ نوشته و در داخلی جعبه قرار می گیرد، سپس کاغذها را به طور تک تک خارج تا زمانی که حجم نمونه مورد نظر کامل شود.
مثلاً فرض شود کل جامعه معلمان به تعداد ۶۰۰ نفر لیست شده است.
سپس با استفاده از جدول اعداد تصادفی، ۱۰۰ نفر به عنوان نمونه انتخاب می شوند.
گاه این انتخاب می تواند به صورت قرعه کشی انجام شود که مبین، نمونه گیری تصادفی است.
این روش نام های دیگری چون روش «نمونه گیری مطبق»، «متناسب با حجم» و نیز «نسبتی» دارد.
این روش، وقتی مورد استفاده است که جامعه هدف پژوهش، دارای ساخت ناهمگن و نامتجانس باشد.
لذا، به علت عدم تجانس و ناهمگنی، در چنین مواردی، جامعه پژوهشی به «طبقات» مختلف تقسیم می شود، در واقع با بهره گیری از نمونه گیری طبقه ای جامعه به گروه های همگن تقسیم می شود، به طوری که افراد در هر طبقه شبیه و همگن باشند.
سپس از هر طبقه یک نمونه تصادفی به نسبت تعداد افراد جامعه انتخاب می گردد.
در این روش پژوهشگر مایل است نمونه پژوهشی را به گونه ای انتخاب کند که مطمئن شود زیر گروه ها با همان نسبتی که در جامعه وجود دارند به عنوان نماینده جامعه، در نمونه نیز حضور داشته باشند.
در این روش برای بیشتر کردن شباهت نمونه در جامعه و افزایش دقت نمونه برداری و برای برآورد پارامترهای جامعه و دخالت دادن ویژگی های خاص جامعه در نمونه، جامعه به گروه های متجانس تقسیم می شوند.
در نتیجه هر گروه یا طبقه از افرادی تشکیل می شود که دارای ویژگی های مشابه هستند.
به طوری که درون گروه ها یا طبقات شباهت زیاد است، لیکن بین طبقات، تفاوت وجود دارد.
به عبارت، در این روشی نمونه گیری، واحدهای جامعه مورد مطالعه در طبقه هایی که از نظر صفت متغیر همگن و متجانس هستند گروه بندی شده تا تغییرات و تنوع آن ها در درون گروهها کمتر شود.
در نتیجه، گروهها و طبقاتی که تشکیل شده دارای ویژگی های مشابه هستند، شکل می گیرد.
سپس با این عمل (تقسیم جامعه به گروههای متجانس) تعداد نمونه نسبت به هر گروه مشخص می شود، آن کاه بااستفاده از روش نمونه گیری ساده یا منظم، تعداد افراد مورد نیاز از هر گروه به نسبت انتخاب خواهد شد.
مثلاً اگر جامعه دانشجویان یک دانشگاه از نظر ابعاد مختلف چون جنسیت، دانشکده، دوره تحصیلی، ورودی و غیره متفاوت باشند، پژوهشگر با توجه به متغیرهای اثر گذار بر صفت مورد بررسی، دانشجویان را به گروه های مختلف تقسیم بندی می کند.
مانند دانشجویان دختر و پسر، دانشجویان دانشکده علوم، مهندسی وسایر و یا دانشجویان مقاطع کارشناسی، ارشد و دکتری.
یا در بررسی مسائل و نیازهای زنان شاغل و یا نیازهای کارمندان در سطوح مختلف سازمان، ویا طبقه های دانش آموزان عالی، متوسط و ضعیف یا اعضای یک دانشگاه اعم استاد، دانشجو، کارشناسی و کارمند مثالی هایی از این نوع روش نمونه گیری است.
در این روش، جامعه آماری به دو گروه زنان شاغل متأهل و غیر متأهل و یا در مثال کارمندان کل جامعه به قشرهای چون کارشناسان و کارکنان و... که هر کدام شرایط کاری خاص دارند، تقسیم و طبقه بندی می شود و بعد از درون هر طبقه یا قشر، نمونه گیری به صورت تصادفی انجام می گیرد.
این روش نمونه گیری در پژوهشهایی که پژوهشگر قصد مقایسه زیر گروه های مختلفی را داشته باشد، مناسب است.
اگر درچنین شرایطی از این روش استفاده نشود، هر گونه تجزیه و تحلیل اطلاعات جمع آوری شده از نمونه نامناسب و در نتیجه، موجب نتیجه گیری اشتباه خواهد بود.
به طور خلاصه در این روش پژوهشگر، مطمئن است که نمونه انتخاب شده بر اساس ویژگی ها و عواملی طبقه بندی و انتخاب شده اند، نمونه ای که نماینده واقعی جامعه مورد نظر است.
الف) پژوهشگر، علاقه مند است اطمینان از این موضوع داشته باشد که هر یک از طبقه های موجود در جامعه، در نمونه او حضور دارند.
ب) جامعه، به خرده گروهها یا طبقه هایی تقسیم می شود و نمونه های مستقل از هر طبقه به طور تصادفی انتخاب می شوند. حجم نمونه در درون هر طبقه با توجه به دو روش نمونه گیری نسبتی) و یا نمونه گیری غیر نسبتی ) می تواند تعیین می گردد.
در نمونه گیری نسبتی، نسبت حجم نمونه انتخاب شده در هر طبقه به کل حجم نمونه با نسبت طبقه به کل جامعه برابر است.
مثلا اگر ۲۰٪ دانشجویان یک دانشگاه از دانشکده مهندسی هستند، در گروه نمونه نیز ۲۰٪ دانشجوی این دانشکده خواهند بود.
مثالی که در ادامه آمده است نمونه گیری از نوع نسبتی است.
به عنوان مثال، در پژوهش هدف، بررسی وضعیت عملکرد در واحدهای مختلف سازمان است.
مدیریت سازمانی اعتقاد دارد که میزان عملکرد سازمان تحت تأثیر واحد سازمانی است. در این پژوهش، تعداد کارمندان در هر مرحله براساس واحدهای سازمانی، به این صورت مشخص شده اند: واحد مالی ۱۸۰ نفر، واحد اداری ۲۲۸ نفر، واحد تولید 133 نفر، و واحد خدمات 59 نفر و و کل جامعه 600 می باشد.
به عنوان مثال، بررسی ها نشان میدهد که یک نمونه ۸۰ نفری باید از کل سازمان انتخاب شود (البته تعداد نمونه باید بر اساس منطق قابل دفاع مانند فرمول یا جدول خاصی انتخاب و ارائه شود که در ادامه به آن اشاره شده است).
ابتدا تعداد نمونه ها را برحسب هر گروه (واحد) مشخص کنید.
در مثال فوق، از آنجا که مدیریت تأثیر واحد کاری بر عملکرد را در نظر گرفته است، باید نسبت کارمندان هر واحد به کل کارمندان سازمان در نمونه ۸۰ نفری رعایت شود.
با محاسبه نسبت به دست آمده اگر در تعداد نمونه ضرب شود، تعداد افراد نمونه در هر گروه مشخصی خواهد شد.
بطور کلی نمونه گیری طبقه ای، یک فرایند دو مرحله ای است:
در مرحله اول جامعه معیارهای خاص به گروههای همگن تقسیم می شود، این روش تشکیل گروههای همگن برای انتخاب نمونه مناسب، اهمیت زیادی دارد .
در مرحله دوم با بهره گیری از نمونه گیری تصافی ساده یا منظم نمونه مورد نظر در هر طبقه از چارچوب نمونه گیری تهیه شده برای آن طبقه به صورت نسبتی یا غیر نسبتی انتخاب می شود.
شرایط استفاده از نمونه گیری به روش طبقه ای:
۱. این روش در موقعیت هایی استفاده می شود که نمونه خیلی بزرگ نباشد؛
۲. این روش به منطقی تصادفی بودن نمونه از جامعه توجه دارد.
یعنی قبل از انتخاب، جامعه به طبقه هایی تقسیم می شود، سپس به نسبت هر طبقه به طور تصادفی، نمونه انتخاب می شوند؛
۳. در صورتی که نسبت نمونه گیری در تمام طبقات یکسان باشد، این روش می تواند موجب اصلاح نمونه گیری تصادفی شود، چرا که اطمینان از حضور همه طبقات جامعه هست؛
۴. طبقات باید به گونه ای تعریف و تفکیک شوند که تا حد امکان طبقات از یکدیگر متفاوت (تفاوت بین طبقات) و در عین حال در درون هر طبقه تجانس و همگنی لازم (تشابه در درون) وجود داشته باشد.
به عبارت دیگر، طبقات از هم مستقل و لیکن در درون هر گروه یا طبقه، افراد همگن وجود داشته باشد.
در نمونه گیری خوشه ای واحد اندازه گیری فرد نیست، بلکه گروهی از افراد (یا همان خوشه ها) هستند که به صورت طبیعی شکل گرفته است.
این روش وقتی به کار می رود که فهرست کامل افراد جامعه در دسترسی نباشد.
به این منظور افراد را در دسته هایی خوشه بندی می کنند، سپس از میان خوشه ها نمونه گیری به عمل آورند و زمانی به کار می رود که انتخاب گروهی از افراد امکان پذیر و آسان تر از انتخاب افراد در یک جامعه تعریف شده باشد.
به عبارتی، اگر در نمونه گیری طبقه ای برای رسیدن به همگنی بیشتر جامعه به چند «طبقه» تقسیم می شد و نمونه از درون طبقات تشکیل شده انتخاب می گردید، در نمونه گیری خوشه ای، «خوشه ها» در برگیرنده گروه های ناهمگن از قبل تشکیل شده، هستند.
روش های نمونه گیری خوشه ای، بر اساسی انتخاب یک «فرد» یا «عضو» مبتنی بود، اما گاه امکان انتخاب فرد نیست و باید «گروه» انتخاب شود.
به خصوص زمانی که فهرستی از جامعه به علت گستردگی آن در دسترس نباشد.
لذا پژوهشگر باید به جای فرد، سراغ «خوشه ها» برود.
نمونه گیری خوشه ای زمانی استفاده می شود که چارچوب نمونه گیری (فهرست اعضای جامعه) در دسترس نیست.
هم چنین گاه به علت پراکندگی و گسترده بودن جامعه مورد نظر انتخاب نمونه با استفاده از سه روش قبلی مقرون به صرفه نیست.
در نتیجه، در این روش، به جای افراد، گروهها است که به صورت تصادفی انتخاب می شوند.
برعکس روش نمونه گیری تصادفی طبقهای که در آن گروهها همگن هستند، در نمونه گیری خوشه ای، گروهها ناهمگن می باشند.
نکته برجسته این روش این است که واحد نمونه گیری فرد نیست، بلکه یک دسته یا خوشه است.
به عنوان مثال فرض شود جامعه مورد نظر و تعریف شده عبارت است از کلیه افراد یک شهر که بیشتر از ۱۸ سال سن دارند، باشد.
در این جامعه نمونه گیری تصادفی ساده و نمونه گیری منظم زمانی میسر است که فهرست کامل تمام افراد یک شهر را با سن آنها در دست داشته باشد، در غیر این صورت به جای انتخاب فرد به عنوان واحد نمونه گیری، منطقه را واحد نمونه گیری قرار می گیرد و سپس به روش نمونه گیری تصادفی ساده از بین مناطق، منطقه یا مناطق مورد نظر را انتخاب می شود.
این روش در موقعیت هایی کاربرد دارد که:
الف) جامعه مورد پژوهشی از دسته های جداگانهای تشکیل شده و عناصر آن در دستههایی توزیع شده باشند؛
ب ) انتخاب گروه آسان تر از انتخاب تک تک افراد باشد .
این روش نمونه گیری، درباره جامعه هایی که دارای توزیع جمعیتی پراکنده و گسترده است، کاربرد دارد، یعنی زمانی که فهرست کاملی از افراد جامعه در دسترسی نباشد.
در این صورت، انتخاب نمونه از نظر اجرایی دشوار است.
در نتیجه، با وجود چنین پراکندگی، جامعه پژوهش باید دسته بندی و به عبارتی خوشه بندی شود، به این معنا که به جای انتخاب فرد به عنوان یک واحد، نمونه گیری از جامعه، کلاسی، مدرسه و یا منطقه به عنوان «خوشه» می شود.
فرد به عنوان یا خلف واحد، نمونه کبیری از سی، مدرسه و عنوان «خوشه» می شود مثلا برای انتخاب یک نمونه ۵۰۰۰ نفری از دانش آموزان راهنمایی سراسر کشور، در مرحله اول به صوت تصادفی پنج استان و از میان شهرستان های هر استان دو شهرستان، از میان شهرها یا بخشهای هر شهرستان دو مدرسه و از هر مدرسه یک کلاس به عنوان نمونه به صورت تصادفی انتخاب می شوند.
و یا برای بررسی میزان تحصیلات کارمندان یک شهر بزرگ که افراد پراکنده اند، با استفاده از نمونه گیری خوشه ای می توان واحد نمونه گیری (خوشه) را «سازمان» تعریف نمود.
سپس چند سازمان یا خوشه را به صورت تصادفی انتخاب و سپس کارمندان مورد نیاز را از بین این سازمان ها انتخاب نمود.
دقت شود درون خوشه ها هر چه تجانس بیشتر باشد، بهتر خواهد بود.
یا این که اگر پژوهشگری قصد دارد توانایی استعداد فضایی دانش آموزان سوم متوسطه یک استان را برآورد کند (برآورد متوسط توانایی درک فضایی دانش آموزان پایه سوم متوسطه) می تواند با انتخاب پایه مورد نظر، مثلاً کلاس سوم را به عنوان «خوشه» در نظر گیرد و سپس فهرست کلاس های سوم متوسطه را فراهم نماید.
بعد از میان کلاس ها به تصادف نمونه گیری کند و در نهایت با انتخاب تمام دانش آموزان آن کلاس ها، تا میزان نمونه مورد نظر انتخاب نمود و متغیر مورد نظر یعنی توانایی فضایی را مورد بررسی قرار داد.
به طور خلاصه در این روش، واحد نمونه گیری یک گروه از افراد یا «خوشه» است که به طور طبیعی تشکیل شده اند.
لذا، وقتی فهرست کامل افراد جامعه مورد مطالعه در دسترس نیست، افراد جامعه در دسته هایی (خوشه ها) دسته بندی می شوند، سپس از میان خوشه ها، نمونه گیری به عمل می آید.
در این جا فهرستی از خوشه ها (نه افراد) به عنوان چارچوب نمونه گیری معرفی و ملاک عملی پژوهشگر قرار می گیرد.
این روش در مقایسه سایر روش ها نیاز به وقت اجرایی کمتری دارد.
لیکن ضعف عمده آن این است که ممکن است نمونه انتخاب شده به صورت کامل معرف نماینده واقعی جامعه نباشد.
در این روش، نکته مهم این روش آن است که چگونه باید دسته بندی انجام گیرد تا منطقی ترین خوشه ها منظور شوند.
بدین لحاظ، روش نمونه گیری خوشه ای از نظر وضعیت خوشه گیری به دو نوع تقسیم می شود:
الف) نمونه گیری منطقه ای یا نمونه گیری خوشه ای جغرافیایی
در این روش چون جامعه از نظر جغرافیایی پراکنده است، افراد نمونه در یک منطقه محلی یا مناطق شهر بزرگ، به عنوان خوشه در نظر گرفته می شوند آنگاه وارد نظام تصادفی می شود.
ب) نمونه گیری خوشه ای متناسب با حجم
زمانی که خوشه های تشکیل شده از نظر حجم نابرابر باشد، از این روش استفاده می شود.
در نتیجه، احتمال انتخاب هر خوشه بسته به حجم خوشه فرق می کند
نمونه گیری خوشه ای چند مرحله ای
نمونه گیری خوشه ای از نظر اجرا بر دو نوع است.
یک مرحله ای و چند مرحله ایی.
۱. نمونه گیری خوشه ای یک مرحله ای
در نمونه گیری خوشه ای یک مرحله ای، عمل نمونه گیری با استفاده از خوشه فقط یک مرتبه و در مرحله اولی، انتخاب و از همه عناصر خوشه های انتخاب شده استفاده می شود.
۲. نمونه گیری خوشه ای چند مرحله ای
نمونه گیری خوشه ای چند مرحله ای، شکل گسترش یافته نمونه گیری خوشه ای است.
در این روش، جامعه مورد نظر به چندین لایه مرتبه بندی تقسیم می شود، به طوری که لایه های بزرگتر لایه های کوچکتر را در بر می گیرد.
پژوهشگر از میان لایه های بزرگتر چند لایه را به صورت تصادفی انتخاب می کند ودر مرحله بعدی از زیر مجموعه های لایه های انتخاب شده، چند زیر مجموعه را به صورت تصادفی انتخاب می کند.
عمل نمونه گیری از لایه ها تا رسیدن به کوچکترین واحد نمونه گیری ادامه می یابد.
بطور خلاصه در این روش، افراد و عناصر اصلی بیش از یک مرحله (چند مرحله) انتخاب می شود و در طی مرحله ها برای انتخاب عناصر هر یک از خوشه های انتخاب شده از فن نمونه گیری تصادفی استفاده می شود.
در نمونه گیری خوشهای چند مرحله ای، در مرحله اول «خوشه ها» انتخاب و بعد در مرحله دوم داخلی هر خوشه «افراد» به تصادف انتخاب می شوند.
مثلاً در مثال قبلی می توان ابتدا چند سازمان (خوشه) را به طور تصادفی انتخاب و سپس از بین هر سازمان، چند «واحد سازمانی» را معین کرد و سپس از بین واحدهای سازمانی، «افراد نمونه» از هر واحد را به طور تصادفی انتخاب نمود.
دقت شود در این جا همان رویکرد نمونه گیری خوشه ای انجام شده، لیکن نحوه عمل به صورت مرحله به یا اگر پژوهشگر بخواهد از میان نواحی جمعیتی یک شهر بزرگ، نمونه انتخاب کند، چون فهرستی از همه جمعیت شهروندان وجود ندارد و آنان در بلوکهای شهری یا بلوکهای سرشماری جداگانه ای سکونت دارند، ابتدا می تواند نمونه ای از بلوک ها را انتخاب نماید، سپس فهرستی از افرادی که در هریک از بلوکهای انتخاب شده زندگی می کنند تهیه نموده و آنگاه از ساکنان هر یک از بلوک ها، به طور تصادفی نمونه گیری کند.
در نمونه گیری یک مرحله ای، چندین خوشه به عنوان نمونه انتخاب می شوند و لیکن در نمونه گیری خوشه ای چند مرحله ای، نمونه منتخب بهتر معرف جامعه است و از این جهت دقت برآورد آن در مقایسه با نمونه گیری خوشه ای یک مرحله ای افزایش مییابد.
هر چند ممکن است به جهت مراحل متعدد نمونه گیری، خطای نمونه گیری افزایش یابد.
در نمونه گیری خوشهای چند مرحله ای، در نهایت این افراد (اشخاص) هستند که به عنوان نمونه انتخاب می شوند و نه خوشه ها.
نمونه گیری خوشه ای چند مرحله ای، نوع دیگری از نمونه گیری خوشه ای است.
زمانی که منطقه به صورت تصادفی انتخاب شد، می توان نمونه گیری را در داخل منطقه نیز ادامه داد.
به عنوان مثال، مطالعه کننده ممکن است آدرس کلیه افرادی را که در یک منطقه زندگی می کنند داشته باشد، بنابراین از بین این افراد، ۱۰ نفر را به صورت تصادفی انتخاب می شود.
در روش نمونه گیری خوشهای چند مرحله ای، فهرست نمونه گیری دوبار و در بعضی مواقع بیش از دو بار تهیه می شود.
نمونه گیری خوشه ای برخی از مواقع در پژوهشهای آموزشی به کار می رود در این نوع پژوهش ها از کلاس به عنوان واحد نمونه گیری استفاده می شود.
از مزایای عمده نمونه گیری خوشهای جلوگیری از اتلاف وقت و صرفه جویی در منابع مالی است.
۱. دقت آن از نمونه گیری تصادفی ساده کمتر است، زیرا در نمونه گیری تصادفی ساده فقط یک اشتباه وجود دارد در صورتی که در نمونه گیری خوشه ای در هر مرحله یک اشتباه نمونه گیری وجود خواهد داشت یعنی به تعداد مراحل، خطای نمونه گیری وجود دارد.
۲. برای داده های جمع آوری شده از این نوع نمونه گیری فرمول آسانی را نمی توان به کار برد، زیرا به کار بردن یک نوع ابزار آماری در جامعه های مختلف دقت آن リ کاهش میدهد.
در تقسیم انواع نمونه گیری خوشهای از نظر وضعیت خوشه گیری، می توان به نمونه گیری خوشه ای طبقه ای (منطقه ای) ونیز نمونه گیری خوشه ای متناسب با حجم، اشارہ کرد.
در نوع نمونه گیری طبقه ای، از ترکیب طبقه بندی و خوشه بندی می توان به نمونه کارآمدی رسید، به ویژه هنگامی که طبقه بندی یا خوشه بندی مبتنی بر ویژگیهای جغرافیایی باشد که نمونه گیری منطقه ای یا نمونه گیری خوشه ای جغرافیایی نامیده می شود.
در این نوع نمونه گیری، هر منطقه یک خوشه در نظر گرفته می شود.
نمونه گیری منطقه ای، پیچیدگی تهیه فهرست نمونه گیری را کاهش می دهد و امکانی را فراهم می نماید که خوشه بندی افراد مورد پژوهش، به گونه ای صورت گیرد که به صورت خوشه و دسته درآیند .
نمونه گیری خوشه ای متناسب با حجم، زمانی استفاده می شود که خوشه های تشکیل شده از نظر حجم نابرابر باشد.
در نتیجه، احتمال انتخاب هر خوشه بسته به حجم خوشه فرق می کند که در آن به خوشه های بزرگتر احتمال بیشتر و به خوشه های کوچکتر احتمالی کمتری انتخاب می شوند .
این روش زمانی استفاده می شود که تمام اعضای جامعه تعریف شده قبلاً به صورت تصادفی فهرست شده باشند.
در این روش نمونه گیری، فاصله و نظم نمونه گیری از تقسیم حجم جامعه بر حجم نمونه به دست می آید.
بدین معنا که در آن هر یک از افراد یک فهرست غیر رتبه بندی و بر اساس فاصله ای منظم و بر طبق نظم و ترتیبی مشخص به طور نظام دار انتخاب می شوند.
مثلاً در جامعه آماری ۱۰۰۰ نفری دانش آموزان، فهرستی از تمام آنان تهیه، سپس از هر ده نفر یک نفر به صورت تصادفی انتخاب می شود.
فرض کنید این انتخاب عدد ۴ باشد.
لذا دانش آموزان شماره های ۴، ۱۴، ۲۴، ۳۴ و... به طور منظم انتخاب خواهند شد.
این عمل تا انتخاب نمونه مورد نظر مثلاً ۱۰۰ نفر ادامه خواهد یافت.
این روش آسان تر از روش نمونه گیری تصادفی ساده است و تفاوت آن با روش نمونه گیری ساده در این است که در این روش، انتخاب هر عضو مستقل از انتخاب سایر اعضای جامعه نیست.
هنگامی که اولین عضو انتخاب شد، بقیه اعضای نمونه مورد نظر به صورت خودکار و نظام مند تعیین می شوند.