

تحلیل عاملی یا آنالیز فاکتور یا Factor Analysis یکی از روشهای آماری چند متغیره است که بین مجموعه فراوانی از متغیرها که به ظاهر بی ارتباط هستند ، رابطه خاصی را تحت یک مدل فرضی برقرار می کند.
در تحلیل عاملی تعداد زیادی از متغیرها برحسب تعداد کمی از ابعاد یا سازه ها بیان می شود ، این سازه ، فاکتور یا عامل نامیده می شود.
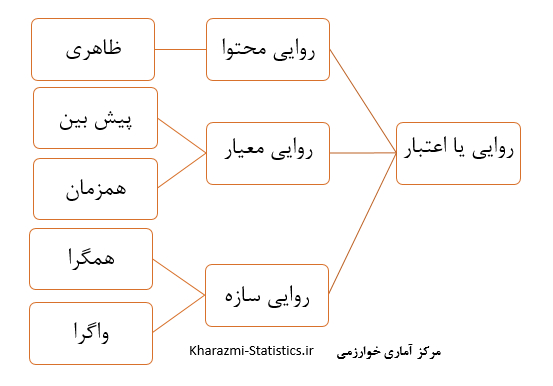
تحلیل عاملىFactor Analysis

تحلیل عاملی یا آنالیز فاکتور یا Factor Analysis یکی از روشهای آماری چند متغیره است که بین مجموعه فراوانی از متغیرها که به ظاهر بی ارتباط هستند ، رابطه خاصی را تحت یک مدل فرضی برقرار می کند.
در تحلیل عاملی تعداد زیادی از متغیرها برحسب تعداد کمی از ابعاد یا سازه ها بیان می شود ، این سازه ، فاکتور یا عامل نامیده می شود.
تحلیل عاملى براى ایجاد ارتباط بین متغیرهاى مشاهد شده و تعداد کمترى از متغیرهاى مفهومى زیرین طراحى شده است . تحلیل عاملى ، سنجه هاى مشاهده شده را برحسب عوامل مشترک ( مشاهده نشده ) به اضافه واریانس یکتا نشان مى دهد . روابط بین عوامل مشاهده نشده و سنجه هاى مشاهد شده تحت عنوان وزن ( براى مثال وزن هاى رگرسیونى ) که عامل ها را به سنجه ها ارتباط مى دهند ، تعریف مى شوند .
آنالیز فاکتور ، چرخه اى را براى حرکت از مدل مسیر مبتنى بر ” سنجه واحد براى هر سازه ” بر چند سنجه براى هر سازه یا مدل مسیر چند معرفه فراهم مى سازد . از این طریق مى توان متغیرهاى نظرى مورد توجه را در تحلیل مسیر آزمود . در این حالت متغیرها به عنوان عامل محسوب مى شوند و براى هر سازه چند سنجه وجود دارد که این عامل سبب بهبود سنجش سازه ها مى شود .
نکتهتحلیل آماری
با گسترش تحلیل مسیر ، با پیوند منطق تحلیل عاملى ، مدل سازى مسیر ، دیگر نمى توان مدل ها را از طریق تکنیک هاى رگرسیونى حداقل مربعات معمولى ( OLS ) حل نمود .

تحلیل عاملی
تحلیل رگرسیونى ما را به یک سنجه واحد که فکر مى کنیم بر متغیر مفهومى مورد نظر نزدیک است محدود مى کند ، در صورت داشتن سنجه هاى مختلف ، بهترین گزینه ما براى تحلیل مسیر معمولاً ترکیب گزینه هاى اندازه گیرى خواهد بود . در اصل آن سنجه باید نشانگر بهترین روایى حتى در صورتى که در برگیرنده خطاهایى از متغیرهاى جمع شده هستند ، باشد .
در مقابل ، در رویکرد تحلیل عاملى بیش از اینکه بر انتخاب بهترین سنجه فکر کنیم ، باید سنجه هاى مختلفى براى ارزیابى متغیرها انتخاب کنیم . سازه عملکرد ( عامل ) به واسطه نقاط مشترک سنجه ها تعریف مى شود . عامل عملکرد ، عاملى است که با دیگر متغیرهاى نظرى روابط درونى دارد و هر کدام از آنها عامل هایى هستند که از طریق چند سنجه تعریف مى شوند . در مدل مسیرى که خطوط یک جهته عامل ها را بر همدیگر وصل مى کند ، همبستگى ها ( کوواریانس ها ) میان عامل ها به ضرایب مسیر تغییر مى یابد ، به همان صورتى که تحلیل رگرسیونى همبستگى ها یا کوواریانس ها را به ضرایب مسیر تغییر مى دهد .
براى خوانندگانى که با تحلیل مسیر آشنا نیستند ؛ مى توان گفت تحلیل عاملى خیلى شبیه رگرسیون است . از آنجایى که آنالیز فاکتور نیز همانند رگرسیون جزء مدل هاى خطى کلى محسوب مى شود ، آن را مى توان به عنوان شکل تغییر یافته رگرسیونى دید .
برجسته ترین تفاوت این دو رویکرد در اینست که در تحلیل عاملى همه متغیرهاى مدل رگرسیونى سنجش نمى شوند . همچنین در تحلیل عاملى ماتریسى که مورد تحلیل قرار مى گیرد ، تحلیل همبستگى است و بنابراین راه حل مشابه رگرسیونى باید بر ضرایب استاندارد شده ( بتا ) توجه داشته باشد .
معادله ى رگرسیونى در شکل ماتریسى Y=BX+E است ، در صورتى که معادله اصلى تحلیل عاملى Y=Pf+U مى باشد . در معادله آخر ، فقط Y ها به طور واقعى سنجیده مى شوند Y ها بر حسب بردار عامل هاى f که بیانگر عامل هاى سنجش نشده مى باشد ، ماتریس وزن ها یا P که بیانگر ماتریس ضرایبى است که عامل ها را بر سنجه هاى مشاهده شده Y وصل مى کنند و بردار باقیمانده ها یعنى U ، تعریف مى شوند .
عناصر P در اصل ضرایب رگرسیونى هستند ؛ اما در واژگان تحلیل عاملى به عنوان عناصر ماتریس الگوى عاملى تعریف مى شوند . عناصر U یعنى باقیمانده هایى که بعد از تجزیه عامل مشترک وجود دارند ، یکتایى در آنالیز فاکتور نامیده مى شوند . معادله تحلیل عاملى از نظر شکل ، معادل تحلیل رگرسیونى است

تحلیل عاملی
آنالیز فاکتور همانند دیگر روشهای آماری راهی برای رسیدن پژوهشگر به اهداف خود می باشد. چنانچه هدف تحقیق کاهش و خلاصه کردن داده ها باشد ، تحلیل عاملی روش مناسبی برای این منظور خواهد بود. در این راستا پژوهشگر برای رسیدن به اهداف خود باید به این سوالات پاسخ دهد :
هنگامى که محققین سنجه ها را در مورد مجموعه اى از ابعاد زیرین اولیه گردآورى مى کنند ، تحلیل عاملى بیشتر براى تأیید آزمون مدل بکار مى رود تا کشف مدل . هر چند که در عمل ، تعیین ماهیت متغیرهاى سنجش نشده همواره به وضوح مشخص نیست تا جایى که تکنیک هاى تحلیل عاملى به عنوان تکنیک هاى اکتشافى بکار گرفته شده اند . بکار بردن تکنیک آنالیز فاکتور براى مشخص سازى ابعاد سنجه هایى که به طور غیر نظرى در هم جمع یا با هم ترکیب شده اند ، مى تواند تفسیر عامل هاى سنجش نشده را دشوار سازد .
طبیعی است که در روش تحلیل عاملی باید دقت زیادی کرد، اگر ناآگاهانه از آن استفاده شود ممکن است بسادگی نتایج ضد و نقیضی به بار آورد.
به طور مشخص تحلیل عاملی چهار وظیف زیر را می تواند انجام دهد:

هدف اغلب تحلیل های عاملی ساده کردن ماتریس همبستگی است، به گونه ای که بتوان آنها را در اغلب عوامل اصلی توصیف کرد؛ به عبارتی بتوان آنها را بر حسب تعدا کمی از عامل های زیر بنایی توضیح داد تا در نتیجه به روابط بین متغیرها پی برد. در واقع، هدف تحلیل عاملی ساده سازی مجموعه ی پیچیده ای از داده ها می باشد. زمانی که اسپرمن در سال ۱۹۰۴ این تکنیک را معرفی کرد، از ساده ترین روشهای محاسباتی استفاده شده بود. امّا با گذشته سالها و با کامل تر شدن رایانه ها، روشهای رایانه ای بسیاری به وجود آمد. در حال حاضر روشهای محاسباتی متفاوتی از تحلیل عاملی وجود دارد، که البته بعضی از آنها از لحاظ فنی نامناسب هستند و نتایج گمراه کننده است.
از تحلیل عاملی می توان بر روابط اساسی بین مقولات یا متغیرها پی برد. تحلیل عاملی مشخص می کند که در بین داده ها چه چیز عامل نامیده می شود، البته منظور از عامل همان ابعاد یا ساختار پنهانی است که محقق در پی کشف و یا آزمون آنهاست. این عامل های سازنده فرضی هستند که غالباً می توانند بین تبین داده ها مورد استفاده قرار گیرند؛ به عبارتی تحلیل عاملی، واریانس موجود در متغیرهای مختلف را بر اساس معدودی از عوامل نشان می دهد.
تحلیل عاملی گویای این سؤال است که عوامل متعدد، چگونه می توانند در یک مجموعه از داده ها قرار گیرند با آن سؤال (گویه) مرتبط شوند. در واقع، تجزیه و تحلیل عاملی روشی برای تعیین تعداد و ماهیت متغیرهای واقعی در میان تعداد زیادی از مقیاس ها می باشد. تحلیل عاملی تعداد متغیرهایی را که می باید پژوهشگر به کار گیرد کاهش می دهد؛ به سخنی دیگر یکی از اهداف اصلی تکنیک تحلیل عاملی، کاهش ابعاد داده هاست، یعنی کاهش دهنده ی تعداد متغیرها به تعداد کمتری از متغیرها یا همان عوامل پنهان است. بنابراین، هدف اصلی تکنیک های تحلیل عاملی، یافتن روش مختصر و مفید کردن اطلاعات بدست آمده از تعداد زیادی متغیر مورد مشاهده و تبدیل آنها به یک مجموعه کوچکتر از ابعاد ترکیبی جدید (عامل ها) با حداقل از دست دادن اطلاعات است. در این روش ابعاد یا سازه های اساسی که فرض می شود از لحاظ مفهومی مبنای مشترک متغیرهای مورد مشاهده هستند، مورد جستجو قرار می گیرد.
به طور مشخص تحلیل عاملی چهار وظیفه ی ذیل را می تواند انجام دهد:

شاخص PGFI در سال ۱۹۸۲ توسط Mulaik and Brett ، James معرفی گردید که میزان پیچیدگی ( تعداد پارامتر های برآورده شده ) مدل تجربی را ارزیابی برازش کلی مدل لحاظ می نماید. این شاخص در راستای بهبود شاخص GFI بر اساس میزان درجه آزادی مدل تجربی و زمانی که هیچ مدلی وجود ندارد معرفی گردید.
شاخص PNFI نیز همانند شاخص NNFI به دنبال بهبود شاخص NFI معرفی گردید ، ولی از راه متفاوت تری بدنبال محاسبه آن برآمد. در واقع شاخص تعدیل یافته مذکور در راستای بهبود شاخص NFI براساس نسبت درجه آازدی مدل تجربی به مدل مستقل معرفی گردید.
برای این دو شاخص دامنه مشخصی که مبین خوب یا ضعیف بودن مدل برازش شده باشد ، ذکر نگردیده است ؛ ولی برخی مقادیر نزدیک ۵ ، ۰ را برای این دو شاخص در نظر گرفته اند.
نکته ۱٫ زمانی که از مدل سازی معادلات ساختاری به روش اندازه گیری انعکاسی یا لیزرل استفاده می نمائید ، برای اینکه مدل شما دقیق تر و با خطای کمتری برآورد گردد ؛ بهتر است حداقل حجم نمونه در نظر گرفته شده ۱۰۰ باشد ؛ تعداد نمونه بیش از ۵۰۰ برازش بهتری را برای مدل شما نمایش می دهد.
نکته ۲٫ زمانی که شرایط غیر نرمال حاکم بوده و تعداد نمونه در دسترس کمتر از ۵۰۰ است ؛ شاخص های NFI ، NNFI و CFI نسبت به شاخص کای اسکوئر برازش بهتری را نشان می دهد.
توجه . در خروجی نرم افزار لیزرل صرف بد بودن ( خوب نبودن ) چند شاخص نمی توان گفت مدل پیشنهاد شده از برازش خوبی برخوردار نیست ، لذا باید چندین شاخص را مد نظر قرار داد تا به یک اجماع کلی درباره خوب یا ضعیف بودن مدل برازش داده شده رسید.

شاخص برازش مقایسه ای ( CFI ) که به عنوان شاخص برازش مقایسه ای بنتلر نیز نامیده می شود ؛ امروزه یکی از پر کاربرد ترین و مناسب ترین شاخص های تفسیری پیرامون تأیید برازش خوب یا ضعیف مدل تجربی است ؛ این شاخص برازش مدل موجود را با مدل مستقل ( Null model ) مقایسه می کند. یکی از مزیت های شاخص CFI عدم حساسیت آن به میزان حجم نمونه بوده و در مواردی که حجم نمونه در دسترس پائین است ، می توان از این شاخص برای تحلیل خوب یا ضعیف بودن مدل برازش داده شده به جای شاخص RMSEA استفاده نمود. دامنه پذیرش این شاخص نیز بین ۹۰ ، ۰ تا ۱ بوده و چنانچه مقدار CFI از ۹۵ ، ۰ بیشتر باشد ، مدل موجود برازش خیلی خوبی را نشان می دهد.

یکی از مفاهیم اساسی که در آمار کاربردی در سطح متوسط دارد اثر انتقال های جمع پذیر و ضرب پذیر در فهرستی از اعداد است. دانشجویان می آموزند که اگر هر یک از اعداد یک فهرست در مقدار ثابت K ضرب شود میانگین اعداد در همان K ضرب می شود و به همین ترتیب ، انحراف استاندارد در مقدار قدر مطلق K ضرب خواهد شد. نکته این است که اگر مجوعه ای از اعداد X با مجموعه دیگری از اعداد Y از طریق معادله Y=4 X مرتبط باشند ، در این صورت واریانس Y باید ۱۶ برابر واریانس X باشد ، و بنابر این از طریق مقایسه واریانسهای X و Y می توانید به گونه غیر مستقیم این فرضیه را که X و Y از طریق معادله Y=4 X با هم مرتبط هستند بیازمایید.
این اندیشه از طریق تعدادی از معادلات خطی از راههای مختلف به چندین متغیر مرتبط با هم تعمیم داده می شود. هر چند قواعد آن پیچیده تر و محاسبات دشوارتر می شود ، اما پیام کلی ثابت می ماند. یعنی با بررسی واریانسها و کوواریانسهای متغیر ها می توانید این فرضیه را که « متغیر ها از طریق مجموعه ای از روابط خطی با هم مرتبط اند » بیازمایید.
آمار دانها برای آزمون این مطلب که آیا مجموعه ای از واریانسها و کوواریانسها در یک ماتریس با ساختار به خصوص و معینی برازش دارد روشهایی را توسعه داده اند.
مقصود آن است که پژوهشگر برای اجرای مقدماتی تحلیل SEM ، ابتدا مدلی را بر پایه تئوری مشخص می سازد. سپس تعیین می کند که چگونه سازه ها را اندازه گیری ، داده ها را گرد آوری و آنها را وارد رایانه کند. درونداد این تحلیل معمولاً ماتریس کوواریانس متغیر های اندازه گیری شده ( مثلاً نمره های مواد یک تست یا پرسشنامه ) است ، هر چند گاهی اوقات ماتریس همبستگیها یا ماتریس کوواریانسها و میانگیها به کاربرده می شود. تحلیلگر داده ها در عمل ، معمولاً برنامه های SEM را با داده های خام تأمین ، و این برنامه ، داده های مذکور را به کوواریانسها و میانگیها برای استفاده لازم تبدیل می کند. این مدل شامل مجموعه ای از روابط بین متغیر های اندازه گیری شده است ، که به عنوان محدودیتهایی در مجموعه کلی روابط ممکن نشان داده می شود. نتایج حاصل ، علاوه بر برآورد پارامتر ها ، خطاهای استاندارد و مشخصه های آزمون برای هر یک از پارامتر های آزاد موجود در مدل ، شامل شاخصهای کلی برازندگی مدل نیز خواهد بود.
درباره این فرایند لازم است چند نکته منطقی و بسیار اساسی را به خاطر بسپارید.
بعید است جهان خطی باشد. روابط حقیقی بین متغیر ها احتمالاً غیر خطی است. علاوه بر این ، بسیاری از مفروضه های آماری نیز تا حدودی زیر سؤال و محل تردید است. پرسش حقیقی این نیست که « آیا این مدل به گونه کامل برازش دارد ؟ » ، بلکه این است که « آیا این مدل به اندازه کافی برازش دارد که تقریب مفیدی برای واقعیت ، و یک تبیین مستدل و منطقی از روند های موجود در داده ها باشد ؟ » . مدلهای SEM را هرگز نمی توان به گونه مطلق پذیرفت ؛ تنها می توان آنها را رد نکرد. این مسئله موجب می شود که پژوهشگران ، یک مدل به خصوص را به گونه موقتی بپذیرند ، زیرا اذعان دارند که در بیشتر موارد ، مدلهای هم ارز و معادلی وجود دارد که به همان اندازه مدلی که به گونه موقت پذیرفته اند ، با داده ها برازش دارد.
بیان این مطلب سفسطه و نتیجه را به غلط تأیید کردن است. مثلاً می توان گفت که « اگر پرویز یک گربه باشد ، پرویز مو دارد. » اما بیان این مطلب که « اگر یک مدل علّی درست باشد ، با داده ها برازش دارد ». اما برازش مدل با داده ها لزوماً دلالت بر این ندارد که آن مدل یک مدل درست است. هنوز ممکن است مدل دیگری وجود داشته باشد که با داده ها به همان اندازه و به همان خوبی برازش داشته باشد.

واژه ی Statistics که به معنای علم آمار است با واژه های State ( =دولت ، دولتی ) و Statist ( = دولتمرد ، سیاستمدار که به معنای آمارگر نیز به کار می رود ) همخانواده است. علت این امر آنست که دولت ها می خواستند از امکانات انسانی و مالی قلمرو حکومت خود آگاه شوند ( مثلاً می خواستند بدانند جمعیت کشور چند نفر است ؟ چه ترکیبی دارد ؟ چند تای آنها استعداد سپاهی شدن را دارند ؟ زمین های قابل کشت چه وسعتی دارند ؟ چند رأس گاو و گوسفند در کشور وجود دارد و … ؟ )
برای بدست آوردن این آگاهی ها با روش هائی که امروزه بسیار ابتدایی به نظر می رسد به آمارگیری می پرداختند. بدین گونه تصور می شد که علم آمار فقط در دستگاه دولت مصرف دارد. بعد ها معلوم شد که آمار دانشی است که افراد و سازمان های غیر دولتی نیز می توانند از آن بهره برداری کنند.
در قرن ۱۷ رواج قمار در میان شاهزادگان و سلاطین اروپا ، موجب پیدایش و رشد تئوری احتمالات شد زیرا آنان با به خدمت گرفتن ریاضیدان هائی مانند پاسکال ، نیوتن ، لایپ نیتز ، فرما و برنولی در شناخت قوانین قمار بسیار کوشیدند.
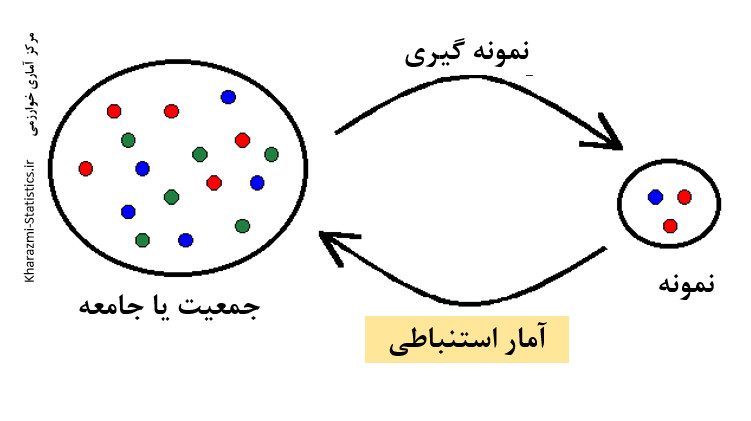
از حدود صد سال پیش ، آماردانان به توسعه ی روش هائی همت گماشتند که امروزه « علم آمار استنباطی » نامیده می شود.
هر بررسی آماری دو هدف دارد :
هدف اول : توصیف ساده ، روشن و قابل فهم مشاهده ها که معمولاً در نمونه ی مناسبی از جامعه صورت می گیرد.
هدف دوم : تعمیم نتایج مشاهده های مزبور به جامعه ای که نمونه از آن برگرفته شده است.
علم آمار ، در تلاش برای تحقق اهداف خود ، شامل سه مبحث اصلی است :
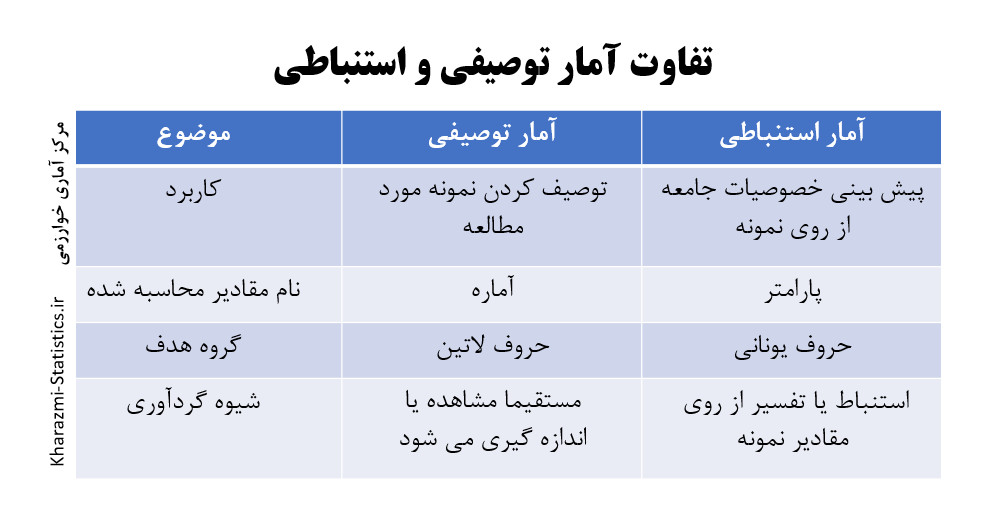
چون نمونه گیری با اشتباه های تصادفی اجتناب ناپذیر همراه است ، نتایج مشاهده ها درباره ی نمونه را نه با قطع و یقین بلکه با درصد اطمینان مشخصی می توان به جامعه تعمیم داد. احتمالات دانشی است برای تعیین این درصد اطمینان . در واقع تئوری احتمالات حالت پلی را دارد که گذشتن از آمار توصیفی و رسیدن به آمار استنباطی را امکان پذیر می سازد. بنابر این آمار توصیفی ، احتمالات و آمار استنباطی سه مبحث مستقل از یکدیگر نیستند. بلکه برای بهتر فهمیدن آمار استنباطی باید ابتدا آمار توصیفی و تئوری احتمالات را بفهمیم.
در مبحث تاریخچه پیدایش علم آمار گفتیم که در گذشته فقط دولت ها ، آن هم به صورت بسیار ابتدائی ، از علم آمار استفاده می کردند با گذشت زمان روش های آماری تکوین و تکامل پیدا کردند ، و علم آمار ، بویژه آمار استنباطی ، به عنوان یک شیوه ی قدرتمند مورد تأیید قرار گرفت. نتایج بسیاری از بررسی علمی با بهره گیری از آمار استنباطی به دست آمده است. مروری بر یک شماره از مجلات علمی برای تأیید این حقیقت کفایت می کند.
امروزه ، به جرأت می توان گفت که بی مساعدت و همراهی علم امار انجام هر گونه تحقیق علمی نا ممکن ( یا دست کم بسیار دشوار ) خواهد بود. به طور کلی هر جا که اثبات صحت مدعائی یا فرضیه ای مورد نظر است آمار حضوری فعال و تعیین کننده دارد.
آمار دانشی است برای تلخیص داده ها مثلاً در قالب یک عدد و ارزیابی تأثیر عوامل تصادفی هنگامی که از نمونه ها برای رسیدن به نتایجی درباره ی جامعه ها استفاده می شود.
منظور از مفاهیم اساسی ، اصطلاحاتی است که به طور مستمر و تکراری در علم آمار مورد استفاده قرار می گیرند. و عبارتند از جامعه و نمونه ؛ پارامتر و آماره ؛ صفت و انواع آن ؛ اندازه گیری و مقیاس های آن ؛ داده ها و اطلاعات. که در این مبحث به تعریف آنها خواهیم پرداخت. هر تعریفی را با دقت و حوصله باید خواند و به خاطر باید سپرد البته هنگامی که این اصطلاح ها به طور مداوم مورد استفاده قرار گیرند مفهوم آنها بیش از پیش ساده تر و قابل فهم تر خواهد شد.
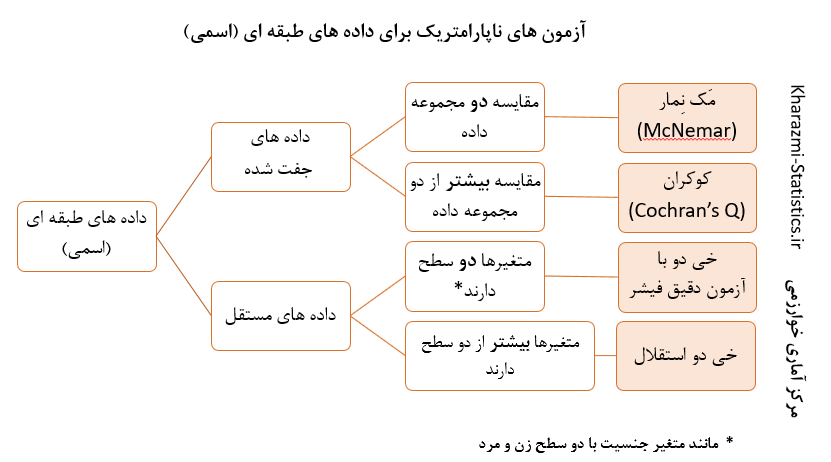
متغیر اسمی
از متغیر اسمی در سادهترین سطح اندازهگیریها، (یعنی زمانی که دادهها براحتی در دستههای مختلف قرار گیرند) استفاده میشود. برای مثال دو متغیر "جنس" و "سابقه ابتلا به بیماری های سیستمیک" اسمی هستند.
متغیرهای اسمی که، پاسخ به آنها یا «بلی» است یا «خیر» را متغیرهای دو حالتی یا dichotomous مینامند.
بسیاری از دستهبندیها در پژوهشهای پزشکی با مقیاس اسمی ارزیابی می شوند. پیامدهای درمان طبی یا روش جراحی اغلب به صورت انجام دادن یا انجام ندادن، مطرح میشود. به همین ترتیب، عاملهای خطر یا عاملهای تماس احتمالی، نیز از این نوع متغیرها می باشند. بدیهی است که در مطالعات، حالت مختلف یک متغیر میتواند بیشتر از دو حالت باشد. برای مثال، متغیر نوع کم خونی به سه دسته تقسیم میشود:
کم خونی میکروسیتیک، کم خونی ماکروسیتیک یا مگالوبلاستیک و کم خونی نرموسیتیک ( پس یک متغیر اسمی سه حالتی می باشد.)
سادهترین راه برای مشخص کردن این که مشاهدات از نوع اسمی میباشد یا خیر، این است که سؤال شود آیا مشاهدات در گروههای مختلف تقسیم شدهاند یا خیر؟
دادههای در بردارندة متغیر اسمی را مشاهدات کیفی یا متغیرهای کیفی گویند؛ زیرا چنین مشاهداتی، کیفیت شخص یا شی یا مشاهدات دستهبندی شده را در گروههای مختلف توصیف میکند. معمولاً دادههای اسمی یا کیفی، به صورت درصد یا نسبت گزارش میگردند. برای مثال اگر ا ز300 فرد مورد مطالعه، 45 نفر زن باشند، می توان اذعان داشت که 15 درصد از افراد مورد مطالعه زن هستند.
متغیر ترتیبی (رتبهای)
اگر بین دستهها ترتیب ذاتی وجود داشته باشد، برای اندازهگیری این مشاهدات از مقیاس ترتیبی استفاده میشود. یعنی متغیر یا مشاهده از نوع رتبهای است. بنابراین در متغیر ترتیبی، دستهبندی با مراعات تقدم و تأخر صورت میگیرد. میزان تحصیلات ( بیسواد، زیر دیپلم، دیپلم و بالاتر از دیپلم) یک متغیر رتبه ای است. همچنین تومورها بر حسب درجة توسعة آنها مرحلهبندی میشوند. دستهبندی بینالمللی برای مشخص کردن مرحلة «سرطان گردن رحم»، شامل یک متغیر ترتیبی پنج گروهی از O تاIV میباشد. در مرحله O سرطان از نوع این سایتو(in situ) میباشد. در مرحله IV سرطان به حفره لگنی پیشرفت کرده یا مخاط مثانه و رکتوم را فرا میگیرد. در این مقیاس همانطوری که ملاحظه میشود، مرحله IV بدترین مرحله نسبت به مرحلهO از نظر پیش آگهی میباشد.
یکی از ویژگیهای مقیاسهای ترتیبی این است که با وجود ترتیب بین دستهها، دامنه دستههای مختلف یکسان نیست. برای آشنایی بیشتر به بررسی نمرات آپگار که مربوط به ارزیابی تکامل نوزادان در موقع تولد میباشد، میپردازیم. در این شیوه ارزیابی، تعداد یازده دسته از صفر تا 10 وجود دارد. نمرات پایین مربوط به نوزادانی است که از نظر عملکرد قلبی ریوی و عصبی وضعیت خوبی ندارند. دستههای بالاتر نشانه سلامت سیستم قلبی ریوی و عصبی میباشد. تفاوت بین دسته 8 و10 از نظر مقدار با تفاوت بین دو گروه صفر و 2 یکسان نمیباشد.
لازم به تذکر است برای گزارش متغیر ترتیبی مانند مقیاس اسمی اکثراً از درصد و نسبت استفاده میشود. برای مثال، در دادههای سرطان کولورکتال، %27 از بیماران دارای تومور در مرحله یک یا دو بودند. در بعضی از مواقع نتایج یک متغیر رتبه ای به صورت میانه ارائه میگردند. نوع جدول و نمودارهایی که برای ارائه دادههای اسمی و دادههای ترتیبی به کار میرود، یکسانند.
متغیر عددی
مشاهداتی را که تفاوت بین اعداد دارای معنا و مفهومی است، متغیر عددی یا مشاهدات کمی گویند، زیرا کمیّت یک شی را اندازهگیری مینمایند. دو نوع متغیر عددی شامل متغیر عددی پیوسته و متغیر عددی گسسته یا ناپیوسته وجود دارند؛ در مقیاس عددی پیوسته، مقادیر عددی کمیّت مورد اندازهگیری به صورت پیوسته (مانند سن، قد، وزن و....) میباشند، در حالی که در مقیاس عددی گسسته، مقادیر عددی کمیّت به صورت ارقام یعنی عدد صحیح میباشند0 مانند تعداد شکستگیهای استخوان، تعداد انگشتان دست).
نکتة مهم این است که در مقیاس عددی با هر اندازه دقّت، اندازهگیری ممکن است، در حالی که با مقیاسهای دیگر چنین امکانی وجود ندارد. برای مثال، سن بیماران در هنگام جراحی برای سرطان کولورکتال مورد بررسی قرار میگیرد. در این نوع بررسی، سن بیمار، متغیر عددی پیوسته است که میتواند بین سن صفر تا سن پیرترین بیمار باشد و بدین ترتیب میتوان سن بیمار را تا آن جا که ضروری است بسیار دقیق (مثلاً بر حسب روز) یادداشت نمود. در ثبت دادههای مربوط به تومور در مطالعات بزرگسالان، دقت در سن بیماران تا نزدیکترین سال کافی است. برای نوجوانان ثبت دادهها مربوط به تومور تا نزدیکترین ماه مناسبتر میباشد. در حالی که برای نوزادان دقت در اندازهگیری سن تا نزدیکترین ساعت و در بعضی اوقات تا نزدیکترین دقیقه مناسب به نظر میرسد و بنابراین دقت در اندازهگیری بستگی به هدف و طرح مطالعاتی دارد. مثالهای دیگری از دادههای پیوسته شامل قد، وزن، طول زمان جراحی، دامنه تحرک مفاصل و بسیاری از مقادیر آزمایشگاهی مانند مقدار گلوکز، سدیم، پتاسیم یا اسید اوریک سرم میباشند.
در صورتی که مشاهدات تنها مقدار رقمی یا عدد صحیح را به خود نسبت دهند، مقیاس اندازهگیری را گسسته گویند. مثلاً تعداد اشیاء از قبیل تعداد حاملگیها، تعداد جراحیهای گذشته، تعداد شکستگیها، تعداد حملات گذران ایسکمیک مغزی(TIA) قبل از یک سکته.
