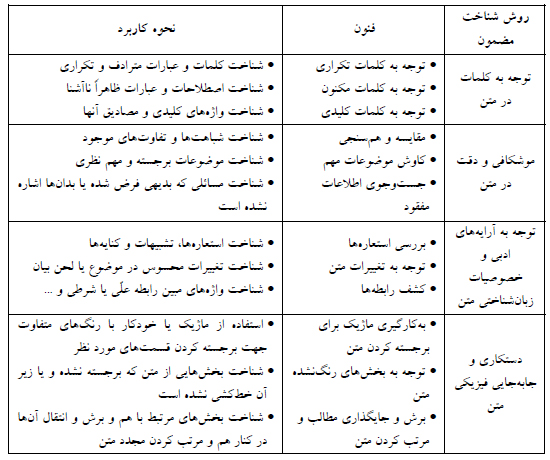
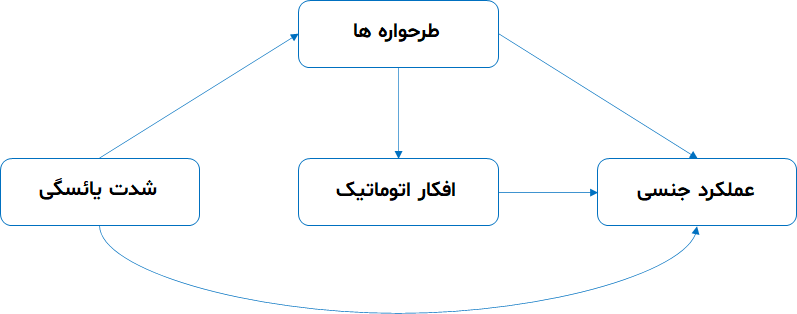
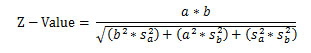SmartPLS multigroup analysis: Chean, J./ Ramayah, T./ Memon, M.A./ Chuah, F./ Ting, H.: Multigroup Analysis using SmartPLS: Step-by-Step Guidelines for Business Research, Asian Journal of Business Research, Volume 10 (2020), Issue 3, pp. 1-19
PLS-SEM and future time perspectives: Chaouali, W./ Souiden, N./ Ringle, C.M.: Elderly Customers’ Reactions to Service Failures: The Role of Future Time Perspctive, Wisdom and Emotional Intelligence, Journal of Services Marketing, forthcoming.
Predictive model selection test: Liengaard, B./ Sharma, P N./ Hult, G.T.M./ Jensen, M.B./ Sarstedt, M./ Hair, J.F./ Ringle, C.M.: Prediction: Coveted, Yet Forsaken? Introducing a Cross-validated Predictive Ability Test in Partial Least Squares Path Modeling, Decision Sciences, forthcoming.
Prediction Metrics: Hair, J.F.: Next-generation Prediction Metrics for Composite-based PLS-SEM, Industrial Management & Data Systems, forthcoming.
No need for PROCESS: Sarstedt, M./ Hair, J.F./ Nitzl, C./ Ringle, C.M./ Howard, M.C.: Beyond a Tandem Analysis of SEM and PROCESS: Use of PLS-SEM for Mediation Analyses!, International Journal of Market Research, forthcoming.
Weighted PLS-SEM (WPLS): Cheah, J.-H./ Roldán, J. L./ Ciavolino, E./ Ting, H./ Ramayah, T.: Sampling Weight Adjustments in Partial Least Squares Structural Equation Modeling: Guidelines and Illustrations, Total Quality Management & Business Excellence, forthcoming.
PLS-SEM in Higher Education: Ghasemy, M./ Teeroovengadum, V./ Becker, J.-M./ & Ringle, C. M.: This Fast Car Can Move Faster: A Review of PLS-SEM Application in Higher Education Research. Higher Education, forthcoming.
Predictive model selection: Sharma, P.N./ Shmueli, G./ Sarstedt, M./ Danks, N./ Ray, S.: Prediction-oriented Model Selection in Partial Least Squares Path Modeling, Decision Sciences (2020), forthcoming.
Causal-predictive PLS-SEM: Chin, W./ Cheah, J.-H./ Liu, Y./ Ting, H./ Lim, X.-J./ & Cham Tat, H.: Demystifying the Role of Causal-predictive Modeling Using Partial Least Squares Structural Equation Modeling in Information Systems Research, Industrial Management & Data Systems, Volume 120 (2020), Issue 12, pp. 2161-2209.
Necessary condition analysis (NCA) and PLS-SEM: Richter, N.F./ Schubring, S./ Hauff, S./ Ringle, C.M./ Sarstedt, M.: When Predictors of Outcomes are Necessary: Guidelines for the Combined Use of PLS-SEM and NCA, Industrial Management & Data Systems, Volume 120 (2020), Issue 12, pp. 2243-2267.
PLS-SEM results assessment: Sarstedt, M./ Ringle, C.M./ Cheah, J.H./ Ting, H./ Moisescu, O.I./ Radomir, L.: Structural Model Robustness Checks in PLS-SEM, Tourism Economics, Volume 26 (2020), Issue 4, pp. 531-554.
Fit criteria: Cho, G./ Hwang, H./ Sarstedt, M./ Ringle, C.M.: Cutoff Criteria for Overall Model Fit Indexes in Generalized Structured Component Analysis, Journal of Marketing Analytics, Volume 8 (2020), Issue 4, pp. 189-202.
PLS-SEM and GSCA: Hwang, H./ Sarstedt, M./ Cheah, J. H./ Ringle, C.M.: A Concept Analysis of Methodological Research on Composite-Based Structural Equation Modeling: Bridging PLSPM and GSCA, Behaviormetrika, Volume 47 (2020), pp. 219-241.
IPMA application in hospitality management: Nunkoo, R./ Teeroovengadum, V./ Ringle, C.M./ Sunnassee, V.: Service Quality and Customer Satisfaction: The Moderating Effects of Hotel Star Rating, International Journal of Hospitality Management, Volume 91(2020), Issue 102414.
More common factor issues: Rhemtulla, M./ van Bork, R./ Borsboom, D.: Worse Than Measurement Error: Consequences of Inappropriate Latent Variable Measurement Models, Psychological Methods, Volume 25 (2020), Issue 1, pp. 30-45.
Different views on CCA: Crittenden, V., Sarstedt, M., Astrachan, C., Hair, J., and Lourenco C. E.: Guest Editorial: Measurement and Scaling Methodologies. Journal of Product & Brand Management, Volume 29 (2020), Issue 4, pp. 409-414.
CCA: Hair, J.F./ Howard, M.C./ Nitzl, C.: Assessing Measurement Model Quality in PLS-SEM Using Confirmatory Composite Analysis, Journal of Business Research, Volume 109 (2020), pp. 101-110. Also take a look here: https://www.unibw.de/ciss-en/methodpaper-nitzl-et-al
PLS-SEM and GSCA: Hwang, H./ Sarstedt, M./ Cheah, J.H./ & Ringle, C.M.: A Concept Analysis of Methodological Research on Composite-based Structural Equation Modeling: Bridging PLSPM and GSCA, Behaviormetrika, Volume 47 (2020), pp. 219–241.
PLS-SEM in HRM: Ringle, C.M./ Sarstedt, M./ Mitchell, R./ Gudergan, S.P.: Partial Least Squares Structural Equation Modeling in HRM Research, The International Journal of Human Resource Management, Volume 31 (2020), Issue 12, pp. 1617-1643.
Common factor issue: Rigdon, E.E., Becker, J.-M./ Sarstedt, M.: Factor Indeterminacy as Metrological Uncertainty: Implications for Advancing Psychological Measurement, Multivariate Behavioral Research, Volume 54 (2019), Issue 3, 429-443.
PLS-SEM software review: Sarstedt, M./ Cheah, J.-H.: Partial Least Squares Structural Equation Modeling Using SmartPLS: A Software Review, Journal of Marketing Analytics, Volume 7 (2019), Issue 3, pp 196–202.
Higher-order models: Sarstedt, M./ Hair, J.F./ Cheah, J.-H./ Becker, J.-M./ Ringle, C.M.: How to Specify, Estimate, and Validate Higher-order Constructs in PLS-SEM, Australasian Marketing Journal, Volume 27 (2019), Issue 3, pp. 197-211.
How to use PLSpredict?! Shmueli, G./ Sarstedt, M./ Hair, J.F./ Cheah, J.-H./ Ting, H./ Vaithilingam, S./ Ringle, C.M.: Predictive Model Assessment in PLS-SEM: Guidelines for Using PLSpredict, European Journal of Marketing, Volume 53 (2019), Issue 11, pp. 2322-2347.
PLS-SEM research networks: Khan, G.F./ Sarstedt, M./ Shiau, W.L., Hair, J.F./ Ringle, C.M./ Fritze, M.P.: Methodological Research on Partial Least Squares Structural Equation Modeling (PLS-SEM): An Analysis Based on Social Network Approaches, Internet Research, Volume 29 (2019), Issue 3, pp. 407-429.
Some rethinking of the PLS-SEM rethinking: Hair, J.F. / Sarstedt, M. / Ringle, C.M.: Rethinking Some of the Rethinking of Partial Least Squares, European Journal of Marketing, Volume 53, Issue 4, pp. 566-584.
More on predictive model selection: Sharma, P.N./ Shmueli, G./ Sarstedt, M./ Thiele, K.O.: PLS-based Model Selection: The Role of Alternative Explanations in MIS Research, Journal of the Association for Information Systems, Volume 20 (2019), Issue 4, pp. 346-397.
PLS-SEM in marketing: Ahrholdt, D.C./ Gudergan, S./ Ringle, C.M.: Enhancing Loyalty: When Improving Consumer Satisfaction and Delight Matters, Journal of Business Research, Volume 94 (2019), Issue 1, pp. 18-27.
PLS-SEM in environmental management: Kotilainen, K./ Saari, U.A./ Mäkinen, S.J./ Ringle, C.M. Exploring the Microfoundations of End-user Interests Toward Co-creating Renewable Energy Technology Innovations, Journal of Cleaner Production, Volume 229 (2019), pp. 203-212.
Something for PLS-SEM haters: Petter, S.: “Haters Gonna Hate”: PLS and Information Systems Research, ACM SIGMIS Database: the DATABASE for Advances in Information Systems, Volume 49, Issue 2, “Haters Gonna Hate”: PLS and Information Systems Research, May 2018.
Data from Experiments and PLS-SEM: Hair, J.F./ Ringle, C.M./ Gudergan, S.P./ Fischer, A./ Nitzl, C./ Menictas, C.: Partial Least Squares Structural Equation Modeling-based Discrete Choice Modeling: An Illustration in Modeling Retailer Choice, Business Research (2018).
Convergent valdity: Cheah, J.-H./ Sarstedt, M./ Ringle, C. M./ Ramayah, T./ Ting, H.: Convergent Validity Assessment of Formatively Measured Constructs in PLS-SEM: On Using Single-item versus Multi-item Measures in Redundancy Analyses, International Journal of Contemporary Hospitality Management, Volume 30 (2018), Issue 11, pp. 3192-3210.
Patient satisfaction: Rosenbusch, J./ Ismail, I.R./ Ringle, C.M.: The Agony of Choice for Medical Tourists: A Patient Satisfaction Index Model, Journal of Hospitality and Tourism Technology, Volume 9 (2018), Issue 3, pp. 267-279.
Endogeneity in PLS-SEM: Hult, G.T.M./ Hair, J.F./ Proksch, D./ Sarstedt, M./ Pinkwart, A./ Ringle, C.M.: Addressing Endogeneity in International Marketing Applications of Partial Least Squares Structural Equation Modeling, Journal of International Marketing, Volume 26 (2018), Issue 3, pp. 1-21.
Moderation: Becker, J.-M./ Ringle, C.M./ Sarstedt, M.: Estimating Moderating Effects in PLS-SEM and PLSc-SEM: Interaction Term Generation x Data Treatment, Journal of Applied Structural Equation Modeling, Volume 2 (2018), Issue 2, pp. 1-21.
PLS-SEM in hospitality research: Ali, F./ Rasoolmanesh, S.M./ Sarstedt, M./ Ringle, C.M./ Ryu, K.: An Assessment of the Use of Partial Least Squares Structural Equation Modeling (PLS-SEM) in Hospitality Research, The International Journal of Contemporary Hospitality Management, Volume 30 (2018), Issue 1, pp. 514-538.
PLS-SEM in finance: Avkiran, N.K./ Ringle, C.M. (2018): Partial Least Squares Structural Equation Modeling: Recent Advances in Banking and Finance. Berlin: Springer.
Handbook article on PLS-SEM: Sarstedt, M./ Ringle, C.M./ Hair, J.F. (2017): Partial Least Squares Structural Equation Modeling. In Homburg, C., Klarmann, M., and Vomberg, A. (Eds.), Handbook of Market Research. Heidelberg: Springer, 1-40.
Mediation: Cepeda Carrión, G./ Nitzl, C./ Roldán, J.L. (2017): Mediation Analyses in Partial Least Squares Structural Equation Modeling: Guidelines and Empirical Examples. In H. Latan & R. Noonan (Eds.), Partial Least Squares Path Modeling: Basic Concepts, Methodological Issues and Applications. Cham: Springer, pp. 173-195.
Segmentation: Sarstedt, M./ Ringle, C.M./ Hair, J.F. (2017): Treating Unobserved Heterogeneity in PLS-SEM: A Multi-method Approach. In H. Latan & R. Noonan (Eds.), Partial Least Squares Path Modeling: Basic Concepts, Methodological Issues and Applications. Cham: Springer, pp. 197-217.
CB-SEM and PLS-SEM: Rigdon/ E. E./ Sarstedt, M./ Ringle, C. M. (2017). On Comparing Results from CB-SEM and PLS-SEM. Five Perspectives and Five Recommendations. Marketing ZFP, 39(3), 4-16.
PLS-SEM performance: Hair, J.F./ Hult, G.T.M./ Ringle, C.M./ Sarstedt, M./ Thiele, K.O. Mirror, Mirror on the Wall: A Comparative Evaluation of Composite-based Structural Equation Modeling Methods, Journal of the Academy of Marketing Science, Volume 45 (2017), Issue 5, 616-632.
Prediction: Shmueli, G./ Ray, S./ Velasquez Estrada, J.M./ Chatla, S.B. The Elephant in the Room: Evaluating the Predictive Performance of PLS Models, Journal of Business Research, Volume 69 (2016), Issue 10, pp. 4552–4564.
PLS-SEM: Richter, N.F./ Cepeda Carrión, G./ Roldán, J.L./ Ringle C.M.: European Management Research Using Partial Least Squares Structural Equation Modeling (PLS-SEM): Editorial, European Management Journal, Volume 34 (2016), Issue 6, pp. 589-97.
CB-SEM and PLS-SEM: Sarstedt, M./ Hair, J.F./ Ringle, C.M./ Thiele, K.O./ Gudergan, S.P. Estimation Issues with PLS and CBSEM: Where the Bias Lies!, Journal of Business Research, 69 (2016), Issue 10, pp. 3998-4010.
Mediation: Nitzl, C./ Roldán, J.L./ Cepeda Carrión, G.: Mediation Analysis in Partial Least Squares Path Modeling: Helping Researchers Discuss More Sophisticated Models, Industrial Management & Data Systems, Volume 119 (2016), Issue 9, pp. 1849-1864.
Importance-performance map (IPMA): Ringle, C.M./ Sarstedt, M.: Gain More Insight from Your PLS-SEM Results: The Importance-Performance Map Analysis, Industrial Management & Data Systems, Volume 119 (2016), Issue 9, 1865-1886.
Measurement invariance: Henseler, J./ Ringle, C.M./ Sarstedt, M.: Testing Measurement Invariance of Composites Using Partial Least Squares, International Marketing Review, Volume 33 (2016), Issue 3, pp. 405-431.
Weigthed PLS: Becker, J.-M./ Ismail, I. R. Accounting for Sampling Weights in PLS Path Modeling: Simulations and Empirical Examples, European Management Journal, Volume 34 (2016), Issue 6, pp. 606-617.
FIMIX-PLS segmentation: Hair, J.F./ Sarstedt, M./ Matthews, L./ Ringle, C.M.: Identifying and Treating Unobserved Heterogeneity with FIMIX-PLS: Part I – Method, European Business Review, Volume 28 (2016), Issue 1, pp. 63-76.
FIMIX-PLS tutorial: Matthews, L./ Sarstedt, M./ Hair, J.F./ Ringle, C.M.: Identifying and Treating Unobserved Heterogeneity with FIMIX-PLS: Part II – A Case Study, European Business Review, Volume 28 (2016), Issue 2, pp. 208-224.
Dynamic PLS: Schubring, S./ Lorscheid, I./ Meyer, M./ Ringle, C.M.: The PLS Agent: Predictive Modeling with PLS-SEM and Agent-based Simulation, Journal of Business Research, Volume 69 (2016), Issue 10, pp. 4604–4612.
Weighted regression segmentation: Schlittgen, R./ Ringle, C.M./ Sarstedt, M./ Becker, J.-M.: Segmentation of PLS Path Models by Iterative Reweighted Regressions, Journal of Business Research, Volume 69 (2016), Issue 10, pp. 4583–4592.
HTMT: Henseler, J./ Sarstedt, M./ Ringle, C.M. A New Criterion for Assessing Discriminant Validity in Variance-Based Structural Equation Modeling. Journal of the Academy of Marketing Science, Volume 43 (2015), Issue 1, pp. 115-135.
Uncovering heterogeneity and prediction-oriented segmentation: Becker, J.-M./ Rai, A./ Ringle, C.M./ Völckner, F. Discovering Unobserved Heterogeneity in Structural Equation Models to Avert Validity Threats, MIS Quarterly, Volume 37 (2013), Issue 3, pp. 665-694.
The future of PLS-SEM! Sarstedt, M./ Ringle, C.M./ Henseler, J./ Hair, J.F. On the Emancipation of PLS-SEM: A Commentary on Rigdon (2012), Long Range Planning, 47 (2014), Issue 3, pp. 154-160.
Creating myths when chasing myths! Rigdon, E.E./ Becker, J.-M./ Rai, A./ Ringle, C.M./ Diamantopoulos, A./ Karahanna, E./ Straub, D.W./ Dijkstra, T.K. Conflating Antecedents and Formative Indicators: A Comment on Aguirre-Urreta and Marakas, Information Systems Research, Volume 25 (2014), Issue 4, pp. 780-784.
The silver bullet! Hair, J.F./ Ringle, C.M./ Sarstedt, M. PLS-SEM: Indeed a Silver Bullet, Journal of Marketing Theory and Practice, 19 (2011), Issue 2, pp. 139-152.
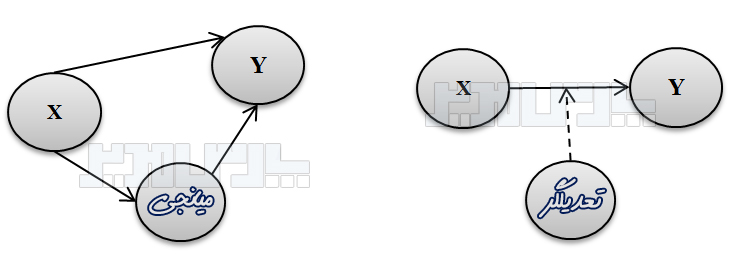
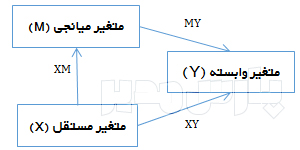
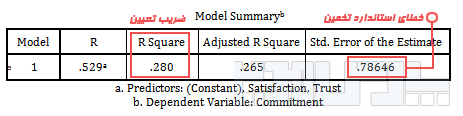
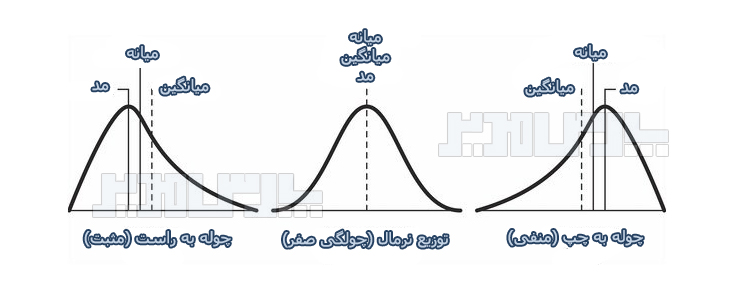
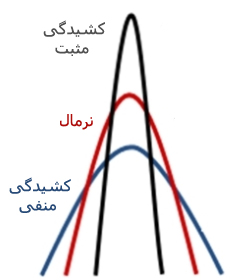
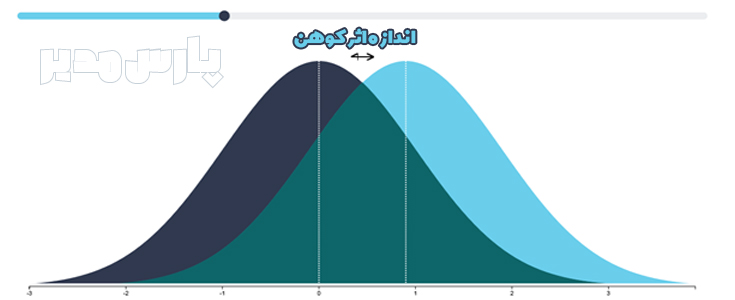
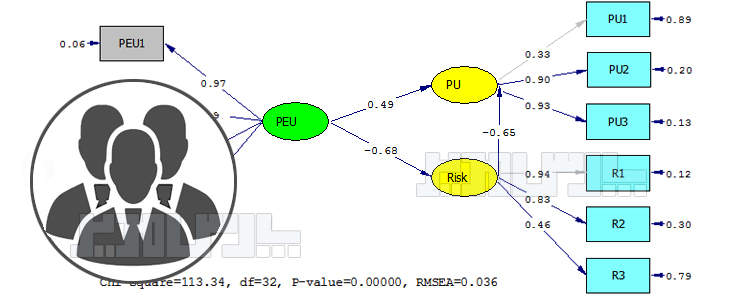
منبع: محسن مرادی و آیدا میرالماسی
آکادمی تحلیل آماری ایران https://analysisacademy.com/