یک نمودار ستونی میتواند از داده های شما نمایش گرافیکی واضحی ارایه دهد. اغلب علاوه بر آمار استنباطی این نمودار میتواند برای توصیف داده ها بکار رود. مثلا اگر شما در حال تحلیل داده های خود در نمونه های مستقل با تست t یا تحلیل داده ها در نمونه های جفت شده (وابسته) با تست t هستید یا میخواهید تحلیل واریانسی یکسویه یا چند سویه انجام دهید میتوانید از این نمودار کمک بگیرید.
مقدمه
اگر بخواهیم جهت انجام یک تحلیل واریانسی ترکیبی یا دوسویه از تست کای-اسکوئر (chi-square) استفاده کنیم، باید بجای نمودار ستونی از نمودار ستونی خوشه ای کمک بگیریم. (نکته: برای رسم نمودار ستونی خوشه ای ما میتوانیم به شما کمک کنیم). هدف از این مبحث این است که به شما نشان دهیم با نرم افزار SPSS چگونه یک نمودار ستونی رسم کنید . قبل از آموزش توجه شما را به مثالی که آورده ایم جلب میکنیم.
مثال
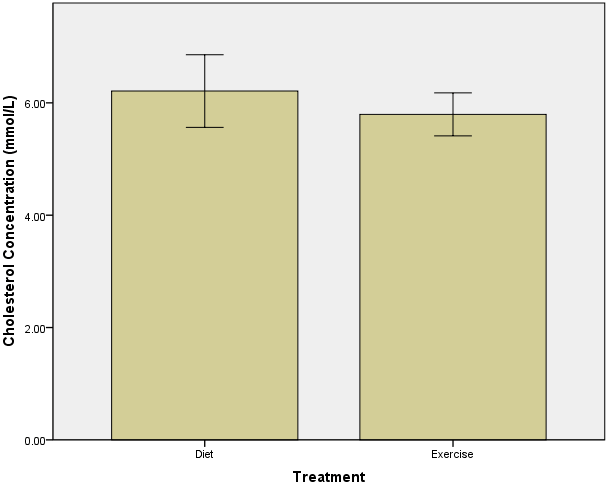
غلظت کلسترول (نوعی اسید چرب) در خون با خطر سکته قلبی رابطه دارد. غلظت بالای آن علامت بالا بودن خطر سکته و غلظت پایین علامت کم بودن خطر سکته میباشد. اگر غلظت کلسترول در خون کم شود خطر سکته قلبی کم می شود. وزن بالا یا فعالیت فیزیکی اندک غلظت کلسترول در خون را زیاد می کند. ورزش و کاهش وزن به کاهش کلسترول کمک میکندولی مشخص نیست که کدامیک کارامدتر است. بنابراین ما در اینجا یک نمونه آماری تصادفی از آقایان با وزن بالا برای تحقیق در نظر می گیریم تا بفهمیم آیا ورزش برای کاهش سطح کلسترول بهتر عمل می کند یا کاهش وزن. این نمونه آماری به دو گروه تقسیم می شود: یک گروه ورزش و فعالیت بدنی انجام میدهند (که در نمودار ستونی عنوان این گروه را “ورزش” می گذاریم) و گروه دیگر از یک رژیم غذایی با کالری کنترل شده استفاده میکند (که در نمودار ستونی نام آن را “رژیم غذایی” قرار میدهیم).
برای اینکه اجرای این برنامه های رفتاری برای هر دو گروه موثر واقع شود از غلظت های کلسترول در انتهای کار میانگین گرفته می شود.بنابراین متغیر وابسته غلظت کلسترول است و متغیر مستقل برنامه کاری این دو گروه یعنی ورزش و رژیم غذایی است. نکته این نمونه آماری شامل داده هایی است که ما از نمونه های مستقل خود با تست t بدست آورده ایم شما اگر مایل باشید می توانید از داده های مورد نظر خودتان در تست t استفاده کنید.
روش تست در SPSS :
۱۳ مرحله ای را که شما در اینجا دنبال می کنید نشان می دهد چگونه یک نمودار ستونی بدست آمده از SPSS را برای مثال بالا رسم کنید. (نکته: اگر شما برای رسم نمودار راهنمایی می خواهید این نوشتار به شما کمک می کند.)
Graphs>chart Builder … ابتدا روی Graphs وسپس روی Chart Builder در منویی که در شکل زیر می بینید کلیک کنید.
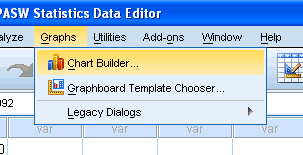
با صفحه زیر مواجه می شوید:
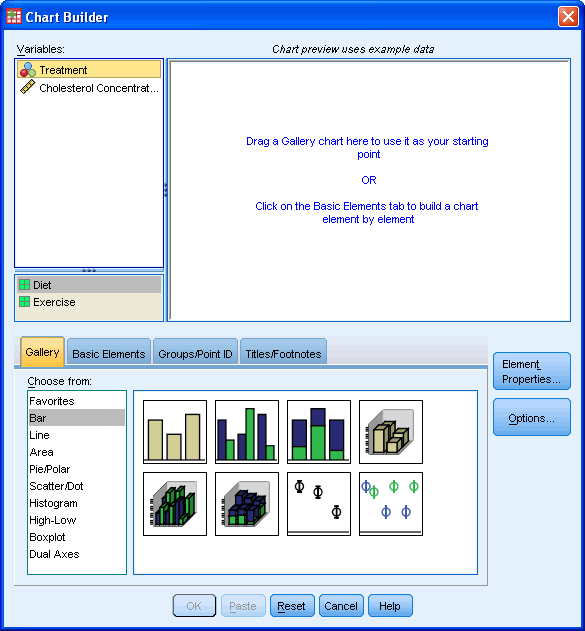
در برگه Gallery گزینه Bar راانتخاب کرده و آیکون نمودار ستونی ساده (ایکون بالا سمت چپ) را انتخاب کنید. این آیکون را بداخل کادر پیش نمایش نمودار کشیده و رها کنید.
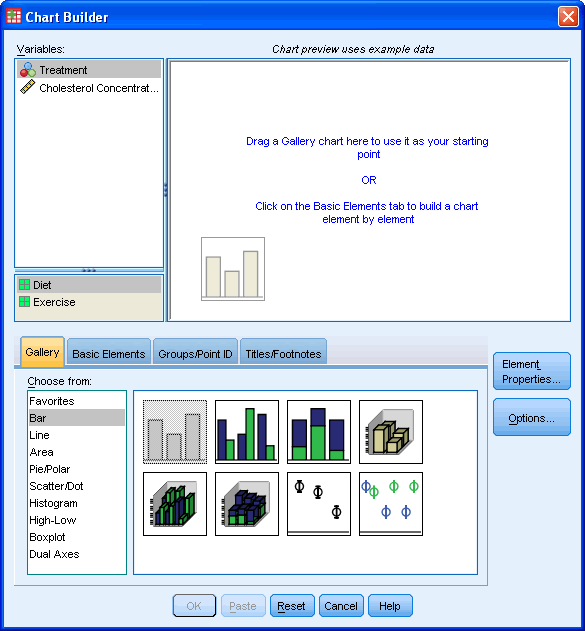
در اینجا کادرهای محاوره ای زیر را مشاهده خواهید کرد : کادر Chart Builder و کادر Element Properties . بطوریکه می بینید کادر پیشنمایش با یک نمودار ستونی ساده پر میشود.
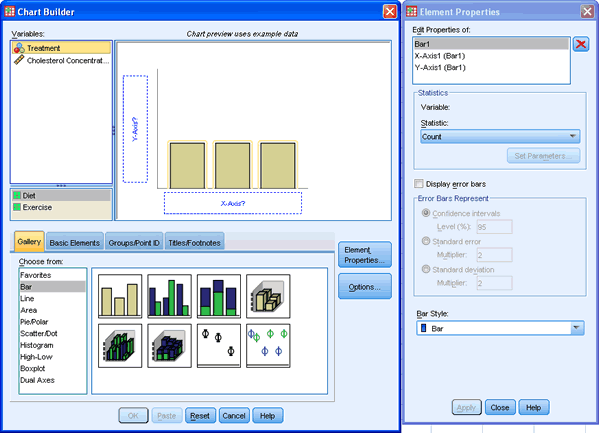
متغیر مستقل یا همان برنامه کاری را به کادری که زیر محور x است و متغیر وابسته (نتیجه) که همان غلظت کلسترول است را به درون کادر محور y انتقال دهید با کشیدن و رها کردن متغیرها از کادر Variables پیش نمایش نمودار را خواهید دید.
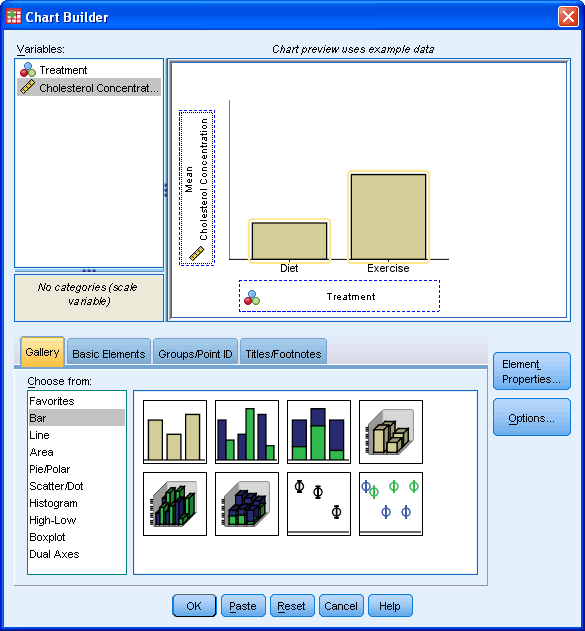
بطور ایده آل ما درصدد هستیم که اندازه پراکندگی داده ها را نشان دهیم و مایلیم در این مورد نوار خطایی با انحراف معیار ۱+ یا ۱- داشته باشیم برای این کار ما گزینه Display error bar را تیک میزنیم و سپس در محیط Error Bar Represent مقدار انحراف معیار را در کادر radio چک کرده و در کادر multiplier عدد ۱ را تایپ می کنیم.
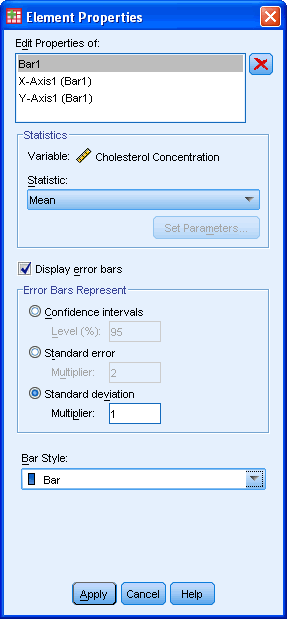
نکته: اگرشما مایلید که نمودار ستونی خود را با آمار استنباطی آنالیزکنید مثلاً ( تست t نمونه های مستقل ، تست t نمونه های وابسته ، تحلیل واریانسی یکسویه و چند سویه ANOVA ) بجای آمار توصیفی میتوانید از فاصله های اطمینان کمک بگیرید. ما دلیل آنرا شرح داده و نشان میدهیم چگونه این کار را انجام دهید.رویApply کلیک کنید. صفحه نمایشی زیر را می بینید.( صفحه نوار خطا در پیش نمایش نمودار)
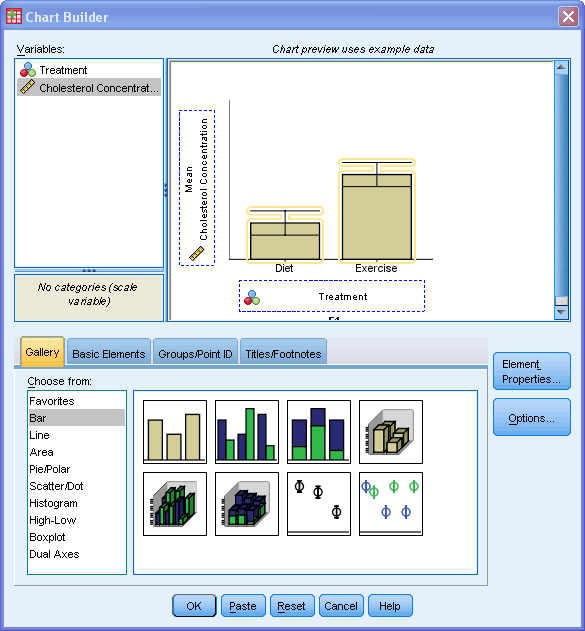
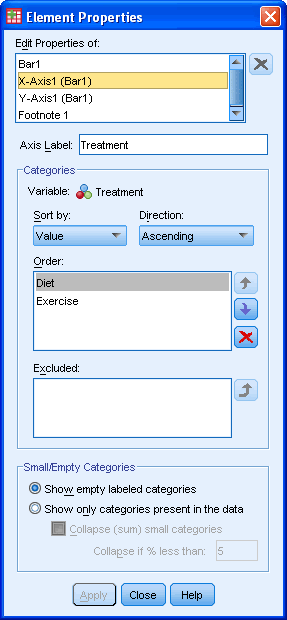
در این مثال لازم نیست در صفحه بعد کاری انجام دهیم این صفحه فقط چندنوع تنظیمات مفید دارد. میتوان از گزینه های ![]() و
و ![]() برای برگرداندن رتبه categories و از قسمت
برای برگرداندن رتبه categories و از قسمت ![]() برای خارج ساختن یک categories استفاده کنید. اگر اشتباهاً یک متغیر را از داده ها خارج کردید با کلیک روی
برای خارج ساختن یک categories استفاده کنید. اگر اشتباهاً یک متغیر را از داده ها خارج کردید با کلیک روی  در کادر Excludeمیتوانید آنرا برگردانید.
در کادر Excludeمیتوانید آنرا برگردانید.
حواستان باشد هر نوع تغییری ایجاد کردید رویApply کلیلک کنید. می خواهیم برچسب محور yراتغییر دهیم تا MEAN را حذف وواحد اندازه گیری دیگری قرار دهیم. با انتخاب “Y-Axis (Bar 1)” در کادر Edit Properties Of این کار را انجام می دهیم و سپس برچسب را بصورت زیر تغییر می دهیم.
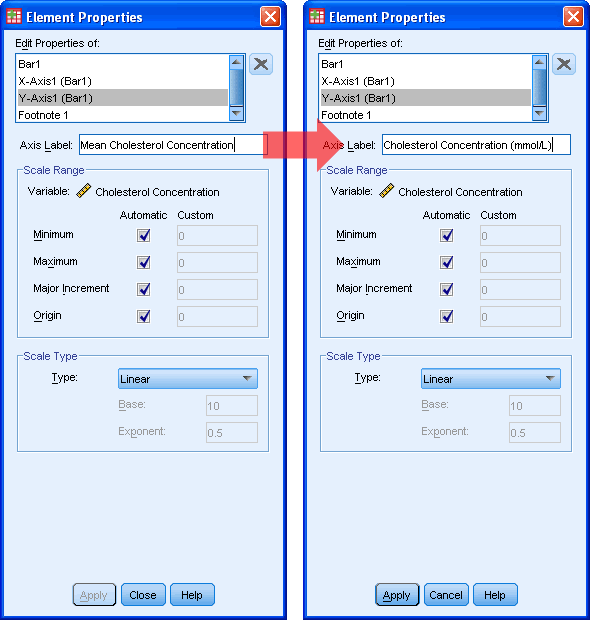
Apply و سپس Ok را کلیک کنید.
خروجی نمودار
شما در قسمت خروجی نمودار زیر را خواهید دید: