
مفهوم نرمال بودن باقی مانده های رگرسیون

یکی از پرکاربردترین روشهای آماری برای تجزیه و تحلیل داده ها در علوم مختلف، رگرسیون خطی ساده یا چندگانه است. در تحلیل رگرسیون نوع روابط متغیرها و این که آیا یک متغیر می تواند در متغیر دیگر تأثیرگذار باشد یا خیر، بررسی می شود. به عبارت دقیقتر بر اساس اطلاع از یک یا چند متغیر مستقل، میتوان یک معادله رگرسیونی نوشت و از آن برای پیشبینی مقادیر متغیر وابسته استفاده کرد. (برای مثال : پیشبینی وزن افراد به وسیله فشار خون، قند خون و چربی خون افراد / پیشبینی عملکرد شرکت بر اساس مسئولیت اجتماعی، اهرم مالی و ساختار مالکیت).
برای استفاده از این روش آماری، پیش فرض هایی ذکر گردیده است :
پیشفرضهای رگرسیون خطی
1) نرمال بودن توزیع ماندهها
2) همسانی واریانس ماندهها
3) عدم وجود همبستگی سریالی در ماندهها
4) عدم وجود همخطی میان متغیرهای مستقل (رگرسیون چندگانه)
بررسی پیشفرض نرمال بودن ماندهها
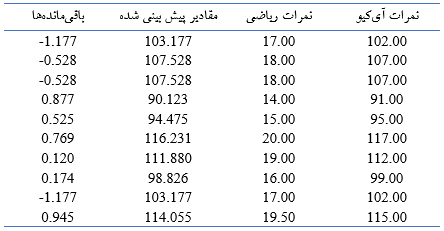
اجازه دهید با ارائه مثالی مفهوم این که چرا باید باقی مانده های بدست آمده از مدل رگرسیون دارای توزیع نرمال باشند را برایتان توضیح دهم. فرض کنید نمرات ریاضی و آیکیو تعداد 10 نفر از دانش آموزان را به صورت فرضی داشته باشیم. این نمرات به شرح زیر هستند :
جدول (1) داده های فرضی دانش آموزان
به وسیلهی این دادهها مدل رگرسیونی برای پیش بینی نمرات آی کیو به توسط نمرات ریاضی دانش آموزان به وسیله مدل زیر برآورد میشود :
![]()
حال از طریق جای گذاری نمرات ریاضی دانش آموزان در فرمول فوق مقادیر پیش بینی شده نمرات آی کیو در جدول (1) بدست میآید. از تفریق مقادیر واقعی آی کیو از مقادیر پیش بینی شده، مانده ها یافت می شود (ستون آخر جدول (1)). حال مسئله اساسی این است که چرا این اعداد باید نرمال باشند ؟
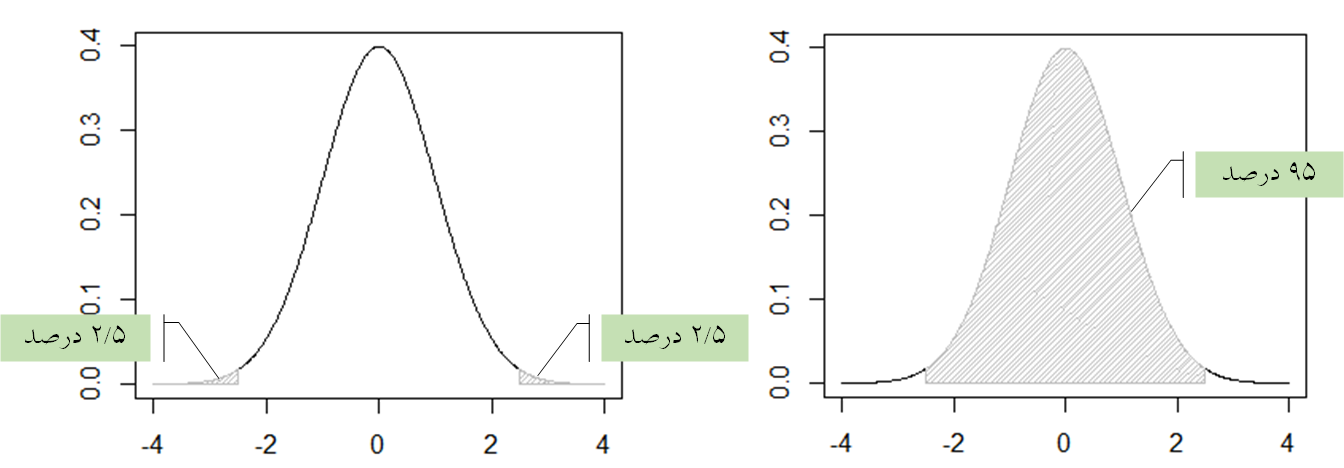
شکل (1) تابع چگالی توزیع نرمال
شکل (1) تابع چگالی توزیع نرمال را نشان میدهد. منحنی توزیع نرمال، زنگوله شکل است، نسبت به محور عمودی خود متقارن است و بیشتر دادهها را حول میانگین جای میدهد. با توجه به نمودار ملاحظه میشود میانگین برابر صفر است (وسط نمودار). همانطور که ملاحظه میکنید 95 دادهها حول صفر قرار دارند و فقط 5 درصد دادهها نسبت به میانگین اعدادی پرت هستند. حال اگر به ماندههای جدول (1) نگاه کنیم میبینیم که همگی حول عدد صفر (میانگین) قرار دارند (اگر ماندهای عدد صفر اختیار کند بدین معناست که مقدار پیشبینی شده با مقدار واقعی برابر است.) بنابراین وقتی میگوییم یکی از پیشفرضهای رگرسیون نرمال بودن ماندهها است بدین معنی است که اکثر ماندهها (95 درصد) نزدیک به صفر بوده و فقط اندکی از آنها (5 درصد) از صفر دور باشند. به عبارت دیگر اکثر مقادیر پیش بینی شده نزدیک به مقادیر واقعی بوده و فقط اندکی از مقادیر پیش بینی شده با مقادیر واقعی تفاوت زیادی داشته باشد (بدین معنی که دقت پیش بینی بالا باشد).

خیلی ممنون بابت توضیحات خوبتون.